참고) https://velog.io/@holicme7/Apache-Kafka-Kafka-Connect-%EB%9E%80
https://minkwon4.tistory.com/319
https://velog.io/@ksh9409255/Kafka-Connect
1. 개요
- 카프카를 사용하여 외부 시스템과 데이터를 주고 받기 위한 오프소스 프레임워크
- 데이터베이스, 키-값 저장소, 검색 인덱스 및 파일 시스템 간의 데이터 통합을 위한 중앙 집중식 데이터 허브 역할을 하는 Apache kafka의 무료 오픈소스 구성요소
- 프로듀서와 컨슈머를 직접 개발해 원하는 동작을 처리할 수 있지만 개발하고 운영하는데 들어가는 리소스나 비용이 부담이 될 수 있다
- 이럴 때 카프카 커넥트를 사용하면 좀 더 효율적으로 빠르게 클라이언트를 구성하고 적용할 수 있다
- 데이터를 어디서(Source) 복사하는지와, 어디에다(Sink) 붙여넣어야 하는지 정의한다
카프카 커넥트와 카프카 커넥터의 차이
- 카프카 커넥트: 프레임워크이다
- 카프카 커넥터: 커넥트 안에 들어가는 플러그인의 한 종류
1). 특징
- 데이터를 자유롭게 import, export할 수 있는 기능
- 코드 없이 Configuration으로 데이터를 이동
- Standalone mode, Distribution mode 지원
- RESTful API 통해 지원
- Stream 또는 Batch 형태로 데이터 전송 가능
- 커스텀 Connector를 통한 다양한 Plugin제공
2). 구성
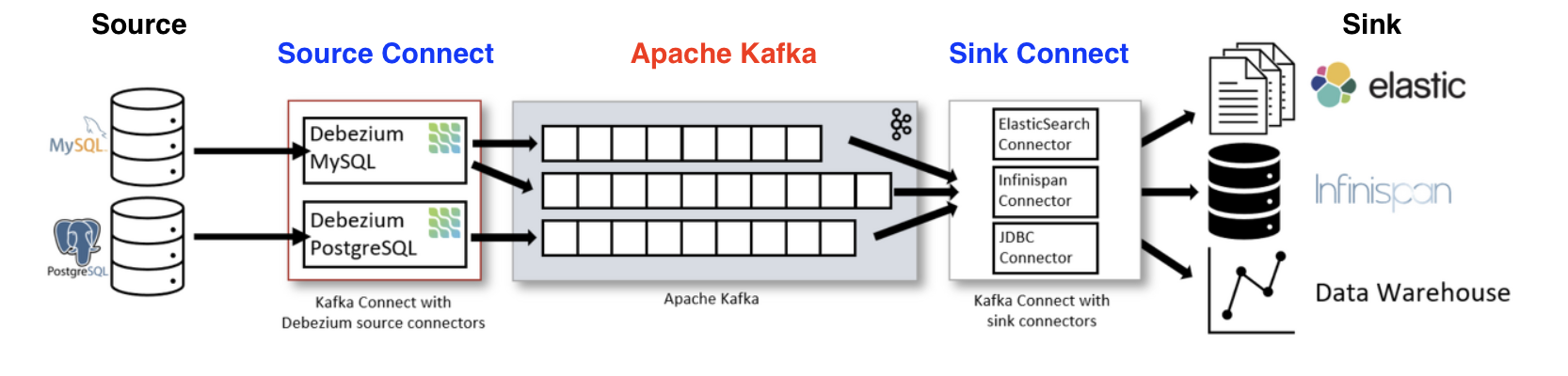
- 카프카를 기준으로 들어오고 나가는 방향에 커넥트가 존재한다
- 동일한 두 커넥트를 구분하기 위해 소스(Source)방향에 있는 커넥트를 소스 커넥트(Source Connect)
- 나가는 방향에 잇는 커넥트를 싱크 커넥트(Sink Connect)라고 한다
- 소스와 카프카 사이에 위치해서 프로듀서 역할을 하는 것이 소스 커넥트
- 카프카와 싱크 사이에 위치해서 컨슈머 역할을 하는 것이 싱크 커넥트
용어 정리
- Connect: Connector를 동작하게 하는 프로세서(서버)
- Connector: Data Source의 데이터를 처리하느 소스가 있는 파일 (Connector 목록 참조)
- Source Connector: 데이터를 가져오는 쪽
-> 데이터를 카프카 토픽에 보내느 역할을 하는 커넥터(producer)
-> 특정한 리소스에서 데이터를 가져와서 클러스터에 저장 (Connect Source)- Sink Connector: 데이터를 보내는 쪽
-> 토픽에 담긴 데이터를 특정 Data Source로 보내는 역할을 하는 커넥터
-> 클러스터에 저장된 데이터를 가져와서 Export (Connect Sink)- 단일 모드(Standalone Mode): 하나의 Connect만 사용하는 모드
- 분산모드(Distributed Mode): 여러개의 Connec를 한 개의 클러스터로 묶어서 사용하는 모드
(1). 커넥트 내부
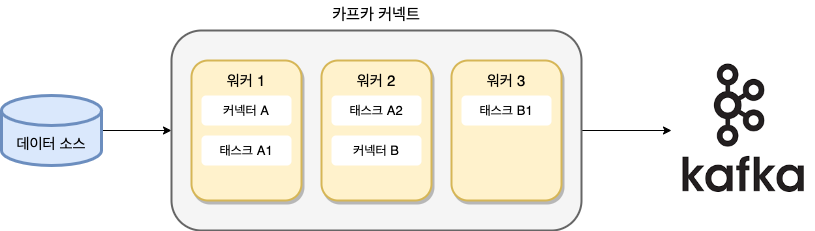
- 아래 사진은 총 3대의 워커(인스턴스)를 실행한 분산 모드 소스 커넥트다
- 단독모드로 실행했다면 단 하나의 워커인 워커1만 동작함
- 워커: 카프카 커넥트 프로세스가 실행되는 서버 또는 인스턴스, 커넥터나 태스트들이 워커에서 실행
- 커넥터: 직접 데이터를 복사하지 않고, 데이터를 어디에서 어디로 복사해야 하는지의 작업을 정의하고 관리하는 역할
- 커넥터도 커넥트와 동일하게 소스에서 카프카로 전송하는 역할을 하는 소스 커넥터와 카프카에서 저장소로 싱크하는 싱크 커넥터가 있다
- 예를 들어 RDBMS의 데이터를 카프카로 전송하고 싶다면 JDBC 소스 커넥터가 필요하고, 카프카에 적재된 데이터를 HDFS로 적재하고 싶으면 HDFS싱크 커넥터가 필요하다 (RDBMS -> Kafka -> UDFS)
(2). 내부 동작
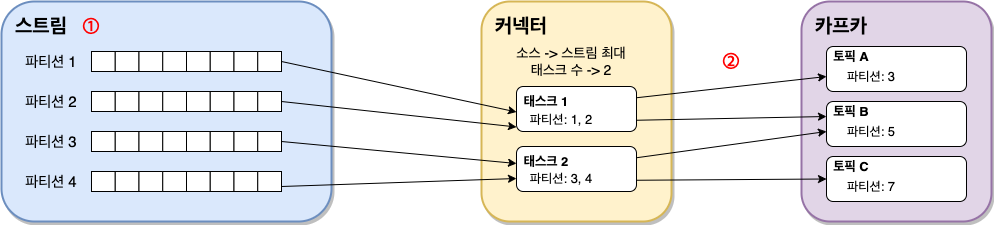
- 분산 배치된 각 태스트들은 메시지들을 소스에서 카프카로, 혹은 카프카에서 싱크로 이동시킨다
- 커넥트는 파티셔닝 개념을 적용해 데이터들을 하위집합으로 나뉜다
- 카프카에서도 병렬처리를 위해 토픽을 파티션으로 나누는데, 커넥트도 이와 동일하다
- 다만 커넥트에서 나눈 파티션과 토픽의 파티션은 용어만 같을 뿐 아무런 관계가 없다
- 여기에서 나뉜 파티션들에는 오프셋과 같이 순차적으로 레코드들이 정렬된다
3). 장점
- 데이터 중심 파이프라인
- 커넥트를 이용해 카프카로부터 데이터를 보내거나, 카프카로부터 데이터를 가져올 수 있다
- 유연성과 확장성
- 테스트 및 일회성 작업을 위한 단독모드로 실행할 수 있고
- 대규모 운영환경을 위한 분산 모드(distributed mode(클러스터형))으로 실행할 수 있다
- 재사용성과 기능 확장
- 이미 만들어진 기존 커넥트를 활용할 수 있고, 운영 환경에서의 요구사항에 맞춰 빠르게 확장 가능
- 장애 및 복구
- 분산 모드로 실행하면, 워커 노드의 장애 상황에도 유연하게 대용 가능
2. 설치
1-1. fafka connect 설치
https://packages.confluent.io/
- 압출 풀고 해당폴더로 이동
1-2. 실행
.\bin\windows\connect-distributed.bat .\etc\kafka\connect-distributed.properties- 오류: Classpath is empty. Please build the project first e.g. by running 'gradlew jarAll'
rem classpath addition for LSB style path
if exist %BASE_DIR%\share\java\kafka\* (
call:concat %BASE_DIR%\share\java\kafka\*
)- 오류: log4j 못찾는 오류
2-1. kafka connect jdbc 설치 및 설정
https://www.confluent.io/hub/confluentinc/kafka-connect-jdbc
2-2. connect-distributed.properties 파일에 plugin path 추가
- etc/kafka/connect-distributed.properties에 추가
plugin.path=[confluentinc-kafka-connect-jdbc-10.7.11 폴더 lib 위치]
3-1. Kafka Connect 폴더내로 mariadb-java-client.jar 파일 복사
- 인터넷에 mariadb connect 다운로드를 하면 된다
3. 테스트
1). Source Connect
1-1. postman으로 post 요청
- localhost:8083/connectors
mariadb일때
{
"name": "my-source-connect",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mariadb://localhost:3308/mydb",
"connection.user": "root",
"connection.password": "test1357",
"mode": "incrementing",
"incrementing.column.name": "id",
"table.whitelist": "mydb.users",
"topic.prefix": "my_topic_",
"tasks.max": "1"
}
}1-2. postman으로 확인 (get)
localhost:8083/connectors- name이 나온다
my-source-connect
1-3. 상세보기
localhost:8083/connectors/my-source-connect/status
1-4. 삭제 (delete)
localhost:8083/connectors/[name]
2-1. 토픽 데이터 확인
- 도커 컨테이너 exec -it로 진입한후
- 토픽확인:
kafka-topics.sh --list --zookeeper zookeeper kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic my_topic_users --from-beginning --max-messages 1
2). Sink Connect
1-1. postman으로 post 요청
- localhost:8083/connectors
{
"name": "my-sink-connect",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url": "jdbc:mariadb://localhost:3308/mydb",
"connection.user": "root",
"connection.password": "test1357",
"auto.create": "true",
"auto.evolve": "true",
"delete.enabled": "false",
"tasks.max": "1",
"topics": "my_topic_users"
}
}