오프셋 재설정 동작
- 오프셋 리셋하는 방식에는 3가지가 있다
- 컨슈머가 특정 파티션에 대해 유효한 커밋된 오프셋을 찾을 수 없을 때 사용된다
- 새로운 컨슈머 그룹이 생성되었거나, 기존 컨슈머 그룹의 오프셋이 만료되거나 삭제된 경우
- none: 설정된 컨슈머 그룹이 없을 때 동작하지 않는다
- 즉 애플리케이션 시작 전에 컨슈머그룹을 설정해야 한다
- 컨슈머가 유효한 커밋된 오프셋을 찾지 못하면, 데이터를 읽는 대신 예외를 발생시킨다
- earliest: 토픽을 맨 처음부터 보겠다는 뜻이다
- 커밋된 오프셋이 없는 경우에만 처음부터 읽는다
- latest: 방금 보낸 새 메시지만 읽는다는 의미이다
- 기존 메시지는 무시하고 애플리케이션 시작된 이후 들어오는 메시지를 처리한다
- 기본값이다
properties.setProperty("auto.offset.reset", "earliest");
오프셋 재설정 동작
- 카프카는 기본적으로는 7일간 데이터를 저장한다
- 즉 컨슈머가 7일간 중지되면 읽으려 하는 오프셋이 무효화된다
- 이럴 때 알아야하는 것이 컨슈머 오프셋 재설정 동작이다
offset.retention.munutes로 기간을 제어할 수 있다
Polling
- 컨슈머를 실행할 때 Polling을 한다고 데이터를 바로 가져오지 않는다
- 컨슈머 그룹에 join을 하고 해당 토픽의 파티션을 할당한다
- 파티션에서 커밋된 오프셋을 찾고 메시지를 받는다
public class ConsumerDemo {
private static final Logger log = LoggerFactory.getLogger(ConsumerDemo.class.getSimpleName());
public static void main(String[] args) {
log.info("I am a Kafka Consumer");
String groupId = "my-java-application";
String topic = "demo_java";
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("key.deserializer", StringDeserializer.class.getName());
properties.setProperty("value.deserializer", StringDeserializer.class.getName());
properties.setProperty("group.id", groupId);
properties.setProperty("auto.offset.reset", "earliest");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Arrays.asList(topic));
while (true) {
log.info("Polling");
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
log.info("Key: " + record.key() + ", Value: " + record.value());
log.info("Partition: " + record.partition() + ", Offset: " + record.offset());
}
}
}
}
우아한 종료
public class ConsumerDemoWithShutdown {
private static final Logger log = LoggerFactory.getLogger(ConsumerDemoWithShutdown.class.getSimpleName());
public static void main(String[] args) {
log.info("I am a Kafka Consumer");
String groupId = "my-java-application";
String topic = "demo_java";
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("key.deserializer", StringDeserializer.class.getName());
properties.setProperty("value.deserializer", StringDeserializer.class.getName());
properties.setProperty("group.id", groupId);
properties.setProperty("auto.offset.reset", "earliest");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
final Thread mainThread = Thread.currentThread();
Runtime.getRuntime().addShutdownHook(new Thread(){
@Override
public void run() {
log.info("Detected a shutdown, let's exit by calling consumer.wakeup()...");
consumer.wakeup();
try {
mainThread.join();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
try {
consumer.subscribe(Arrays.asList(topic));
while (true) {
log.info("Polling");
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
log.info("Key: " + record.key() + ", Value: " + record.value());
log.info("Partition: " + record.partition() + ", Offset: " + record.offset());
}
}
} catch (WakeupException e) {
log.info("Consumer is starting to shut down");
} catch (Exception e) {
log.error("Unexpected exception in the consumer", e);
}finally {
consumer.close();
log.info("The consumer is now gracefully shut down");
}
}
}
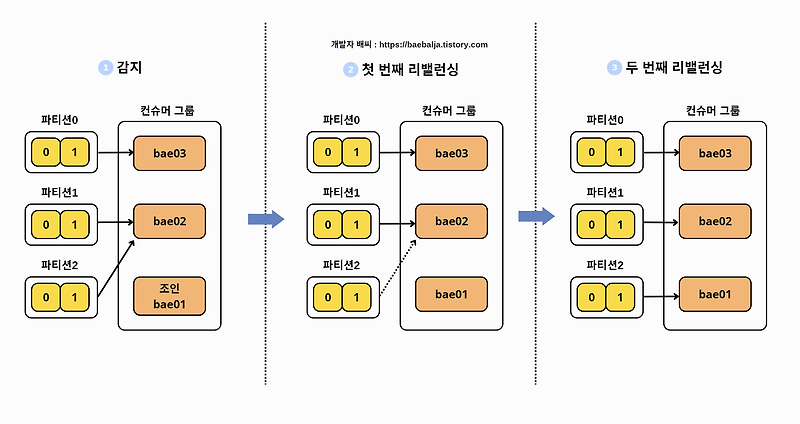
컨슈머 그룹
- 같은 컨슈머 그룹으로 컨슈머를 실행할 때마다 파티션들이 리밸런싱 된다
컨슈머1이 기존 파티션 1,2,3을 가지고 있다고 했을 때 컨슈머가 조인하게 되면 컨슈머1이 파티션 1,2 컨슈머2가 파티션 3을 폴링하도록 재배치하게 된다
- 컨슈머가 그룹에 합류하거나 나갈 때마다 파티션이 이동하게 된다
- 파티션이 이동하는 현상을
리밸런싱이라고 한다
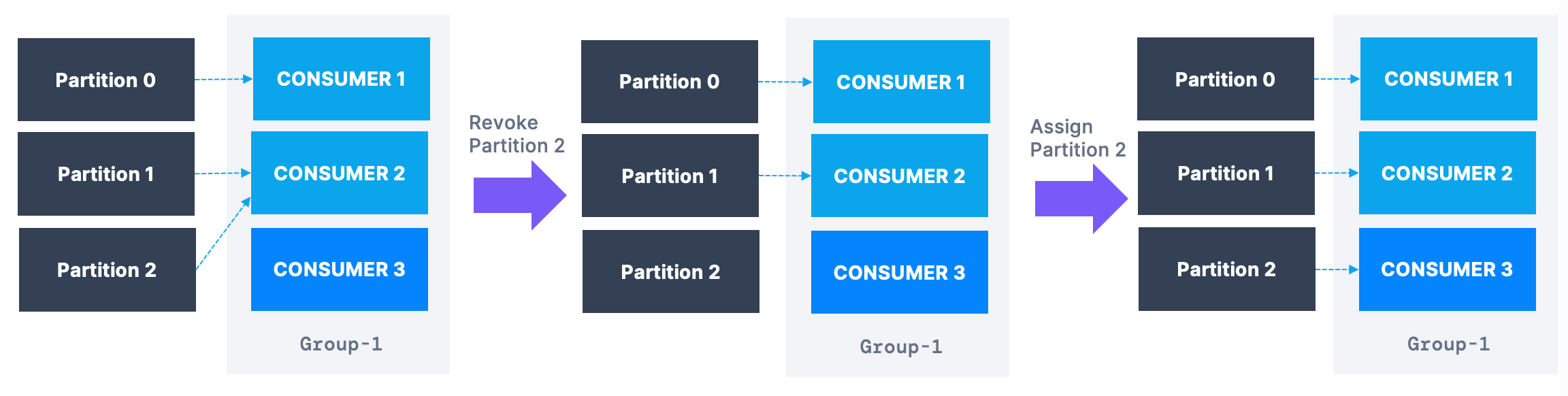
밸런싱 전략
- 적극적 리밸런싱
- 기본 전략으로 컨슈머가 들어오면 모든 컨슈머는 작업을 중단하고 무작위로 재할당 받는다
Stop the world: 짧은 시간에 모든 걸 멈추는 현상이 발생한다- 무작위이기 때문에 같은 파티션에 간다는 보장이 없고 사용을 중지한다는 단점이 있다

- 협력적 리밸런싱
- 파티션을 작은 그룹으로 나눠서 한 커슈머에서 다른 컨슈머로 재할당한다
- 중단 없이 데이터를 처리한다는 장점이 있다
- 여러번 반복에 거쳐서 하기때문에 안정적으로 할당받을 수 있다
적극적 리밸런싱
- RangeAssignor: 파티션을 토픽당 기준으로 할당해서 균형을 맞추기 어렵다
- RoundRobin: 모든 파티션이 모든 토픽에 걸쳐서 할당된다. 균형적이다
- StickyAssignor: 초반에는 라운드 로빈처럼 하다가 컨슈머가 이동하게 되면 이동을 최소화하기 위해 파티션 이동을 최소화 한다
협력적 리밸런싱
- CooperativeStickyAssignor: 데이터 이동 횟수를 최소화하기 위해 파티션 이동 횟수를 최소화한다
- kafka Conenct에서는 협력적 리밸런싱이 기본값이다
- Kafka Streams에서는 StreamsParitionAssignor이 기본값이다
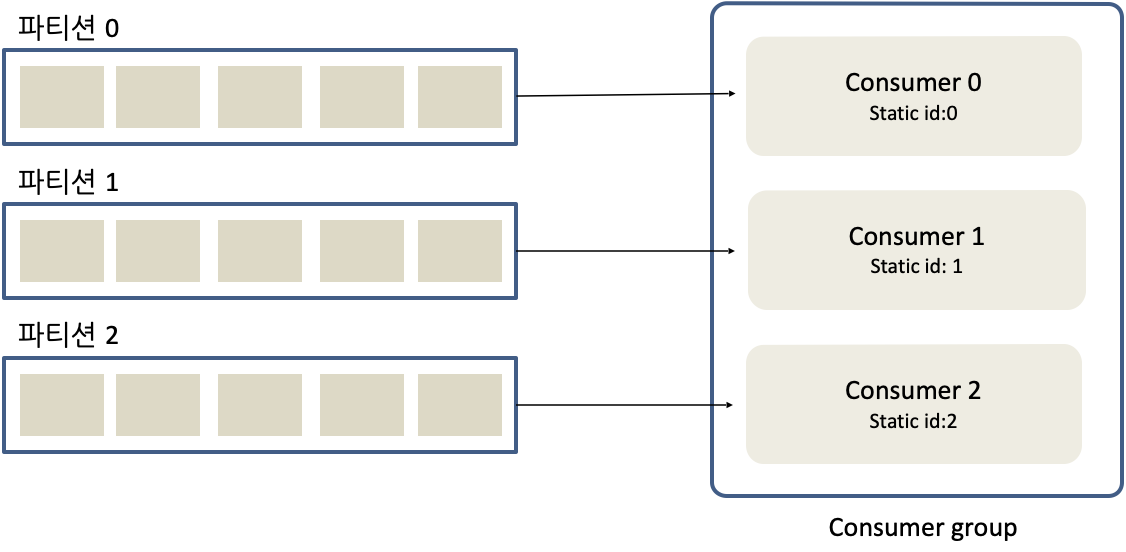
정적 그룹 멤버십
- 컨슈머가 그룹에 합류하거나 나갈 때마다 리밸런싱이 발생한다
- 왜냐하면 카프카는 모든 컨슈머가 모든 파티션을 읽어들이게 하기 때문이다
- 컨슈머가 나가더라도 할당을 바뀌지 않게 할 수 있다
- 컨슈머가 나갔다 들어오면 재할당을 받는 이유가
새 멤버 ID를 받기 때문이다
- 그룹 인스턴스 ID를 컨슈머 구성 값의 일부로 특정하면 컨슈머는 정적 멤버가 된다
- 세션 시간 내에 다시 합류하면 자동으로 재할당되고, 리밸런싱은 일어나지 않는다
properties.setProperty("partition.assignment.strategy", CooperativeStickyAssignor.class.getName());
전달 의미론
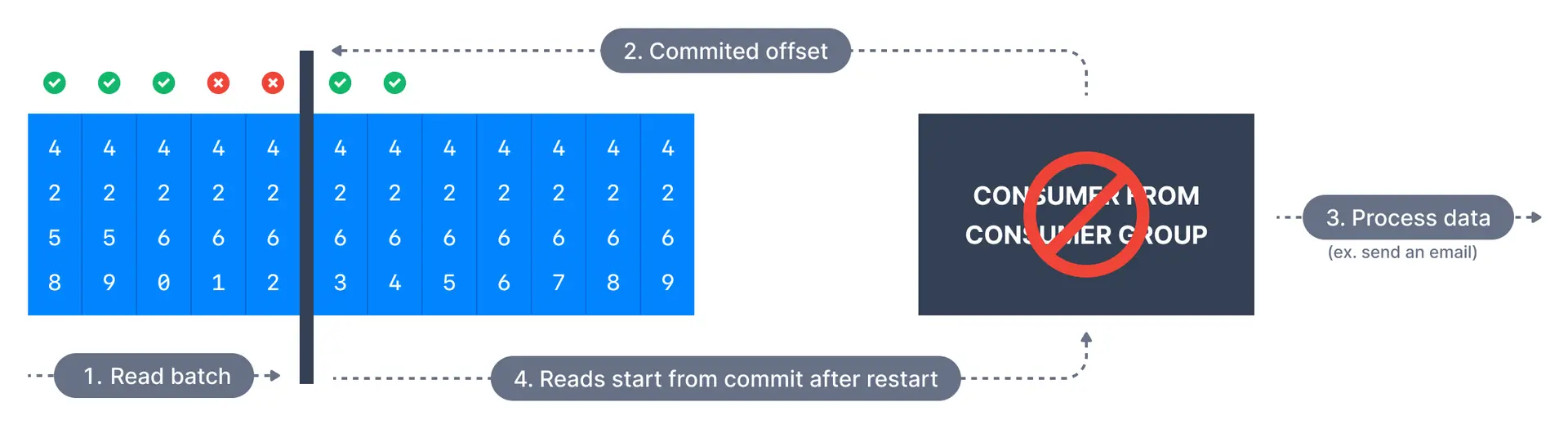
최대 한 번(At Most Once)
- 메시지 배치를 받자마자 오프셋을 커밋한다
- 처리가 잘못되면 메시지가 손실된다
- 메시지를 읽으면 바로 커밋하기 때문에 메시지를 처리하지 못하더라도 재처리가 불가능하다
- 두 번은 절대 안읽지만 안 볼 때도 있다
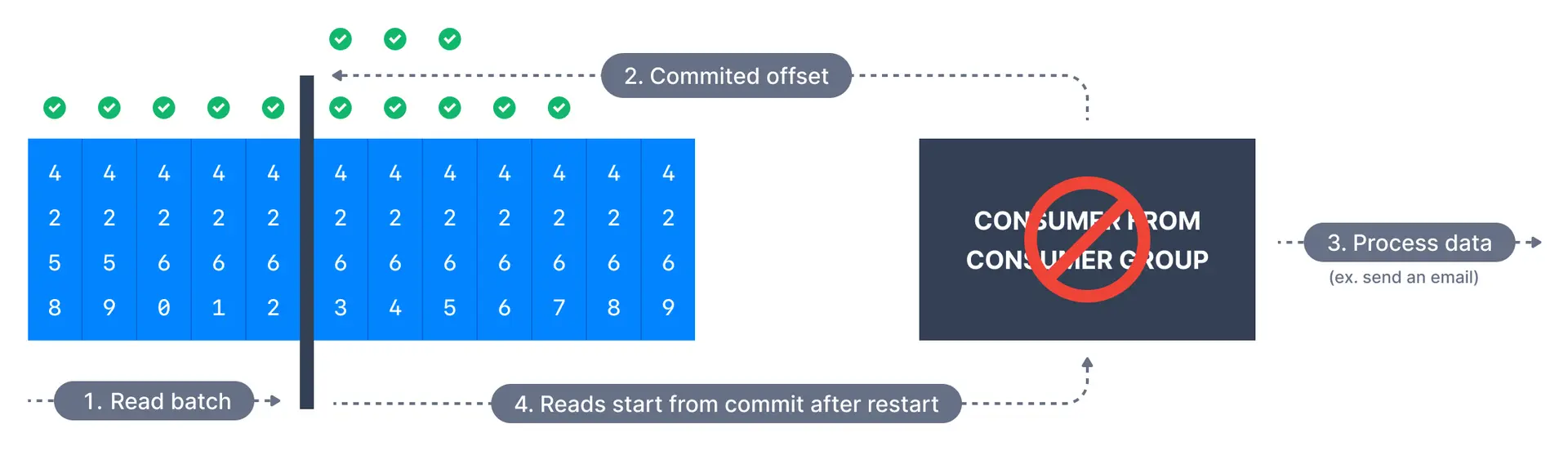
최소 한 번(At Least Once)
- 메시지 처리가 잘못되면 다시 읽을 기회를 준다
- 메시지를 읽을 기회가 두 번이기 때문에 처리가 멱등이어야 한다
- 메시지 커밋 전에 오류가 발생하면 커밋이 진행되지 않으므로, 커밋 전 과정에서 다시 처리가 이루어진다. 이를 방지하기 위해 멱등성을 보장해야 한다
- 애플리케이션에서는 적어도 최소 한 번을 보장해야 한다
정확히 한 번(Exactly once)
- 카프카에서 데이터를 가져오고 트랜잭션 API를 사용하여 다시 Kafka로 보낼 때 얻을 수 있다
- Kafka Streams API를 사용하면 쉽게 달성할 수 있다
멱등 컨슈머
- ID를 이용해서 처리를 하면 멱등성을 보장받을 수 있다
- 이건 잘 알아보고 해야 한다 ID가 없을 수도 있고 ID로 멱등성을 보장하지 않는 곳도 있다
- 방법 1: 카프카 데이터상의 있는 내용을 이용해서 ID를 정의한다
- 방법 2: 데이터 내의 ID를 사용한다
String id = record.topic() + "_" + record.partition() + "_" + record.offset();
try {
IndexRequest indexRequest = new IndexRequest("wikimedia")
.source(record.value(), XContentType.JSON)
.id(id);
}
Consumer Offset Commit Strategies
(1). 자동커밋
enable.auto.commit=true이면 오토커밋으로 배치가 동시에 처리된다- 기본설정으로 오프셋이 정기적으로 커밋된다
- 최소 한 번 읽기가 기본 설정값이다
동작방식
poll()메서드가 코드에 호출될 때 항상 커밋된다- 그러면
auto.commit.interval.ms가 경과한다
auto.commit.interval.ms가 5초인 경우 poll을 호출할 때마다 5초 간격으로 커밋된다
- 그전에 메시지를 성공적으로 처리해야 한다. 그러지 않으면 메시지가 소실될 수도 있다
- 마지막으로 poll 호출 전에 처리된 모든 메시지를 비동기적으로 처리한다
- 5초로 설정해도 폴을 하는 동안에는 커밋을 하지 않아 시간이 지날 수 있다

(2).수동커밋
enable.auto.commit=false으로 수동으로 오프셋을 커밋한다
동작방식
commitSync, commitAsync를 호출해 오프셋을 커밋을 한다
consumer.commitSync();
consumer.commitAsync();
컨슈머 작동방식
- 컨슈머 코디네이터와 통신하는 컨슈머가 있다
- 컨슈머 코디네이터는 컨슈머가 계속 사용중인지 감지하는데 사용하는 브로커이다
hearbeat 스레드와 poll 스레드가 있다- 컨슈머 코디네이터는
hearbeat매커니즘을 사용하는 브로커이다
- 데이터를 빠르게 처리하고 자주 폴 하는 것이 좋다
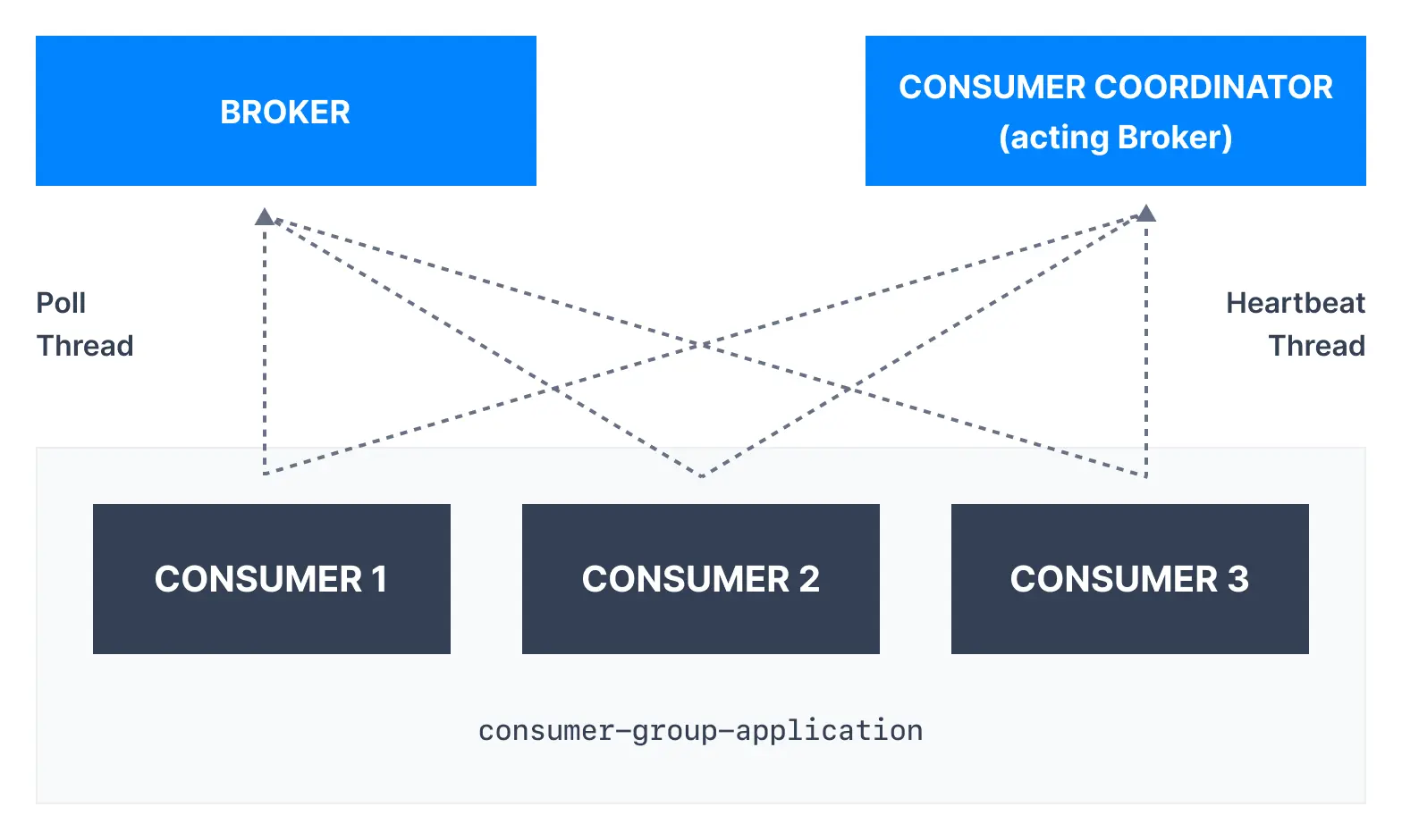
1). Heartbaet 쓰레드
heartbeat.interval.ms 기본값 3초로 Kafka로 데이터를 보낸다- 컨슈머가 사용 중임을 알리기 위한 heartbeat 데이터뿐이다
- 보통
session.timeout.ms의 1/3으로 설정한다
- heartbeat 타임아웃 시간 중에 전송되지 않으면 컨슈머가 사용 중이 아닌 것으로 간주한다
- 빠르게 리밸런싱을 하려면 시간을 짧게 하는 것이 좋다
2). Poll 쓰레드
max.poll.interval.ms의 기본값은 5분으로 두번의 poll사이에 시간을 얼마나 둘지이다- 처리에 5분이 넘게 걸릴 경우 컨슈머가 사용중이 아닌 것으로 간주한다
max.poll.records는 기본값이 500으로 요청 다 한번에 가져올 레코드 개수이다fetch.min.bytes는 기본값이 1로 요청당 kafka에서 가져올 최소 데이터 개수이다
- 이 값을 높이면 레이턴시를 대가로 요청 수를 낮춰 처리량을 높일 수 있다
- 1MB가 되기전까지는 데이터가 필요없다고 말하는 것과 같다
fetch.max.wait.ms는 기본값이 500, 즉 0.5초이다
- bytes에 다 차기전까지 데이터를 보내지 않을 최대 시간이다
max.partition.fetch.bytes는 기본값이 1MB이다
- 서버가 반환할 파티션 당 데이터의 최대 양이다
- 파티션이 100개라면 메모리에 100MB를 적재해야 하므로 필요에 따라 조정해야 한다
컨슈머와 파티션 리더
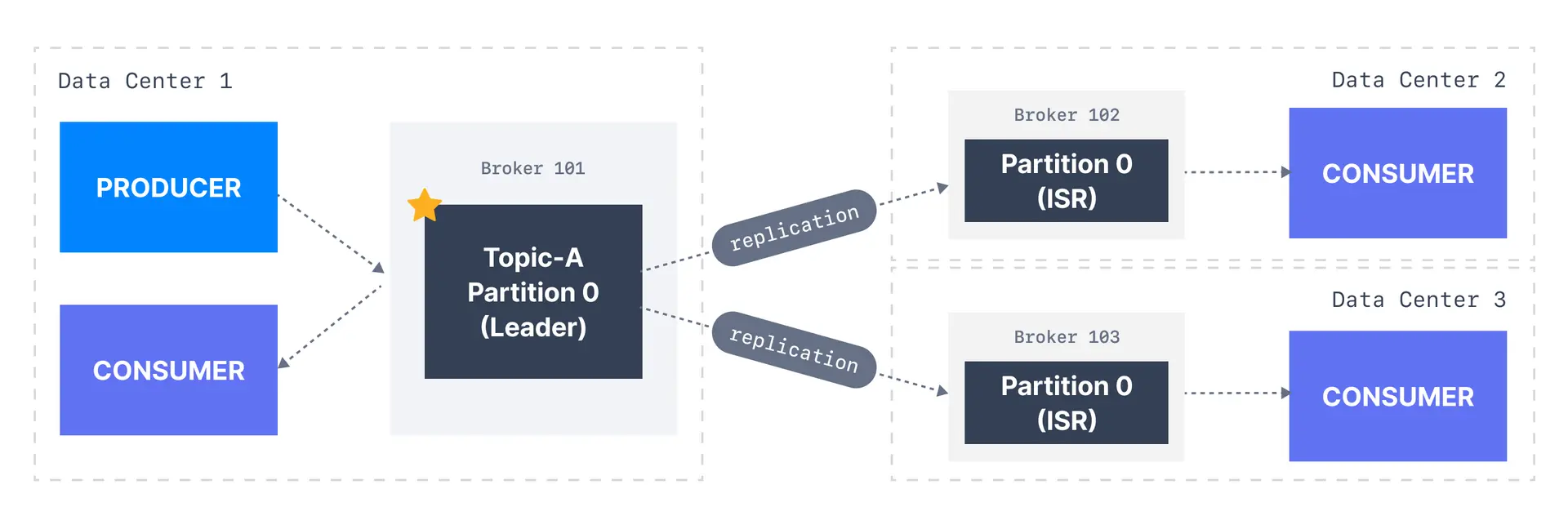
- 컨슈머는 기본적으로 파티션 리더에서 데이터를 읽어온다
- 하지만 데이터센터가 여러개라면 레이턴시와 네트워크 비용이 높아져 비효율적이게 될 것이다
- 그래서 2.4부터 가까운 레플리카에서 읽어오도록 변경됐다
- 레이턴시와 비용적으로 절감할 수 있게 되었다
- 이를 컨슈머 랙 인식을 할 수 있게 설정을 해줘야 한다
- AWS ID를 만들고 class.replicas 해줘야 한다