기초
public class ProducerDemo {
private static final Logger log = LoggerFactory.getLogger(ProducerDemo.class.getSimpleName());
public static void main(String[] args) {
log.info("hello world");
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("key.serializer", StringSerializer.class.getName());
properties.setProperty("value.serializer", StringSerializer.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("demo_java", "hello world");
producer.send(producerRecord);
producer.flush();
producer.close();
}
}
콜백
- 프로듀서가 어느 파티션의 어느 오프셋으로 전송되지는지 알 수 있다
- 데이터를 보내고 성공적으로 반환받는지, 에러를 반환받는지 알 수 있다
public class ProducerDemoWithCallback {
private static final Logger log = LoggerFactory.getLogger(ProducerDemoWithCallback.class.getSimpleName());
public static void main(String[] args) {
log.info("I am a Kafka Producer");
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("key.serializer", StringSerializer.class.getName());
properties.setProperty("value.serializer", StringSerializer.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("demo_java", "hello world");
producer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e == null) {
log.info("Received new metadata \n" +
"Topic: " + recordMetadata.topic() + "\n" +
"Partition: " + recordMetadata.partition() + "\n" +
"Offset: " + recordMetadata.offset() + "\n" +
"Timestamp: " + recordMetadata.timestamp() + "\n"
);
} else{
log.error("Error while producing", e);
}
}
});
producer.flush();
producer.close();
}
}
프로듀서 동작 방식
- 라운드로빈 방식
- 데이터가 하나씩 하나의 파티션으로 번갈아가면서 동작한다
- Sticky Prititioner
- 빠르게 데이터가 들어오면 배치처리를 한다
- 일괄처리로 하나의 파티션에 데이터가 들어가도록 한다
- 성능면에서 라운드로빈 방식에 비해서 낫고 Default이다
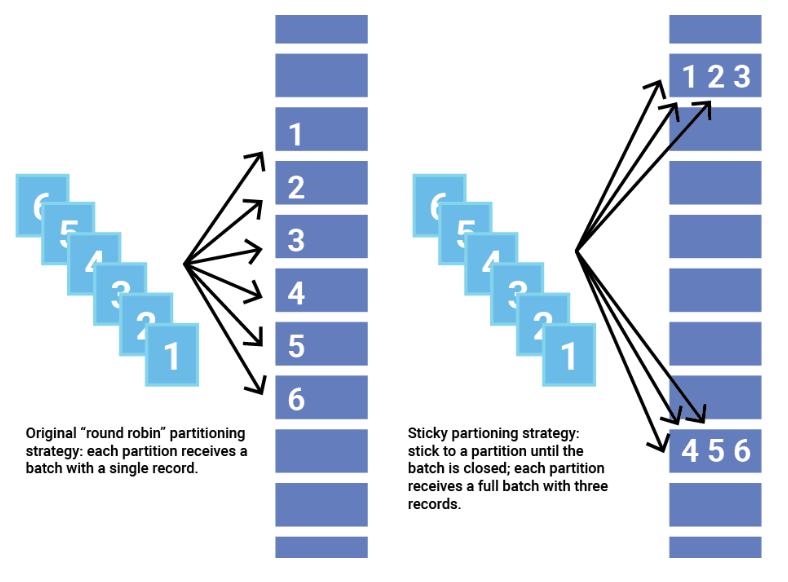
properties.setProperty("batch.size", "400");
properties.setProperty("partitioner.class", RoundRobinPartitioner.class.getName());
프로듀서 키
- 키를 지정하면 같은 파티션으로 간다
- 동일한 키는 동일한 파티션
public class ProducerDemoWithKeys {
private static final Logger log = LoggerFactory.getLogger(ProducerDemoWithKeys.class.getSimpleName());
public static void main(String[] args) {
log.info("I am a Kafka Producer");
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("key.serializer", StringSerializer.class.getName());
properties.setProperty("value.serializer", StringSerializer.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
for (int j = 0; j < 2; j++) {
for (int i = 0; i < 10; i++) {
String topic = "demo_java";
String key = "id_" + i;
String value = "hello world " + i;
ProducerRecord<String, String> producerRecord = new ProducerRecord<>(topic, key, value);
producer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e == null) {
log.info("Key: " + key + " | Partition: " + recordMetadata.partition()
);
} else {
log.error("Error while producing", e);
}
}
});
}
}
producer.flush();
producer.close();
}
}
확인 응답(Acknowledgements)
- 프로듀서가 브로커에게 데이터를 보내면 데이터 쓰기 작업이 완료됐다는 확인 응답을 받을 수 있다
- acks=0: 확인 응답을 기다리지 않겠다는 뜻이다
- 따라서 데이터 손실 가능성이 있다. 확인 요청조차 하지 않는다
- acks=1: 리더 브로커의 확인을 기다리겠다는 뜻이다
- acks=all: 리더와 모든 레플리카한테 확인을 받는다
- 데이터 손실이 발생하지 않는다.
acks=-1과 같은 의미이다
Acks=0
- 프로듀서는 메시지는 보내는 순간 메시지 쓰기에 성공했다고 간주한다
- 브로커가 오프라인이 되거나 예외가 발생하더라도 우리는 알 수 없고 데이터 손실로 이어진다
- 메트릭 정보처럼 메시지를 유실해도 괜찮을 때 유용하다
- 네트워크 오버헤드가 최소화되기 때문에 성능상 제일 우월하다
Acks=1
- 리더 브로커에게 확인 응답을 받을 때 메시지 쓰기가 성공했다고 간주한다
- 2.8까지 기본 값이었으나 현재는 Acks=all로 바뀌었다
- 데이터 확인을 받은 건 리더뿐이라 데이터가 복제되었는지 여부는 알 수 없다
- 리더가 오프라인이 됐을 때 레플리카들이 미처 데이터를 복제해두지 못했다면 데이터 손실이 발생한다
Acks=all
- 요즘은 데이터 안전을 최대한 보장하려는 추세이다
- 동기화된 레플리카(ISR)들에게 모두 확인을 받으면 메시지 쓰기에 성공했다고 간주한다
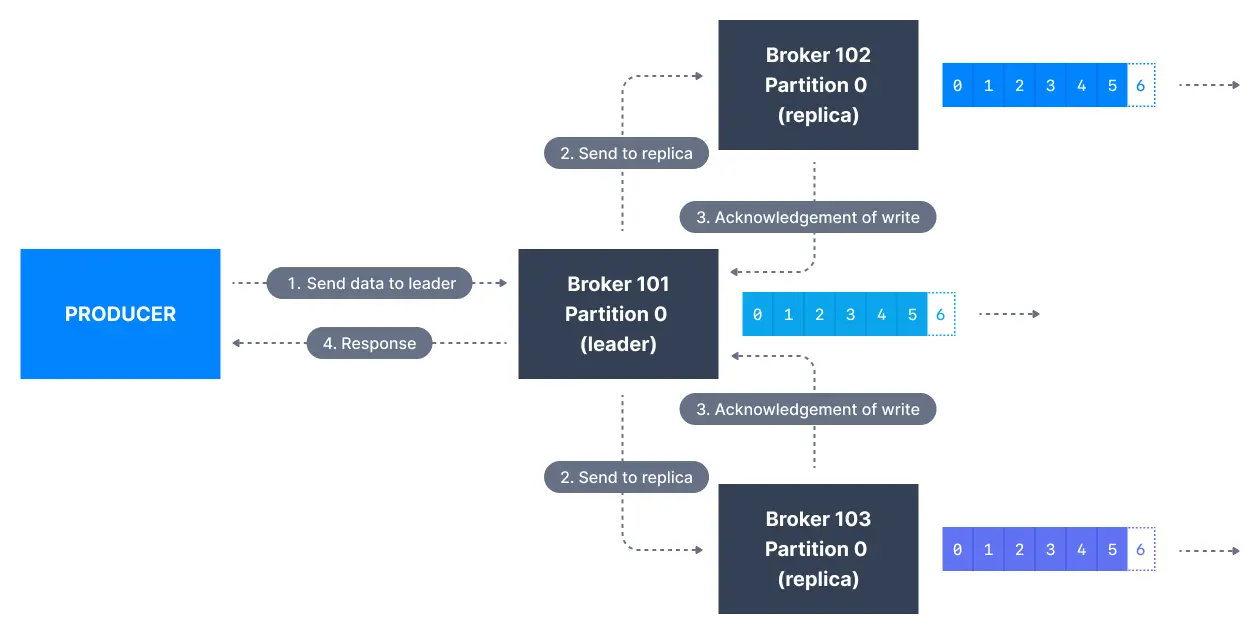
min.insync.replicas
- acks=all과 같이 쓰는 설정이 있다
min.insync.replicas이다
- acks=all을 할 때 리더가 현재 클러스터 내의 동기화된 레플리카 개수만으로 안전한 쓰기가 가능한지 확인한다
min.insync.replicas=1가 기본값인데 이 경우 리더 브로커만 확인 응답을 보내면 된다min.insync.replicas=2은 리더 브로커와 적어도 1개이상의 레플리카가 확인 응답을 보내야한다- 충족하지 못하게 되면 예외를 발생시킨다
- 데이터 안전을 최대로 하려면 복제 계수는 3으로
min.insync.replicas은 2로 설정해야 한다
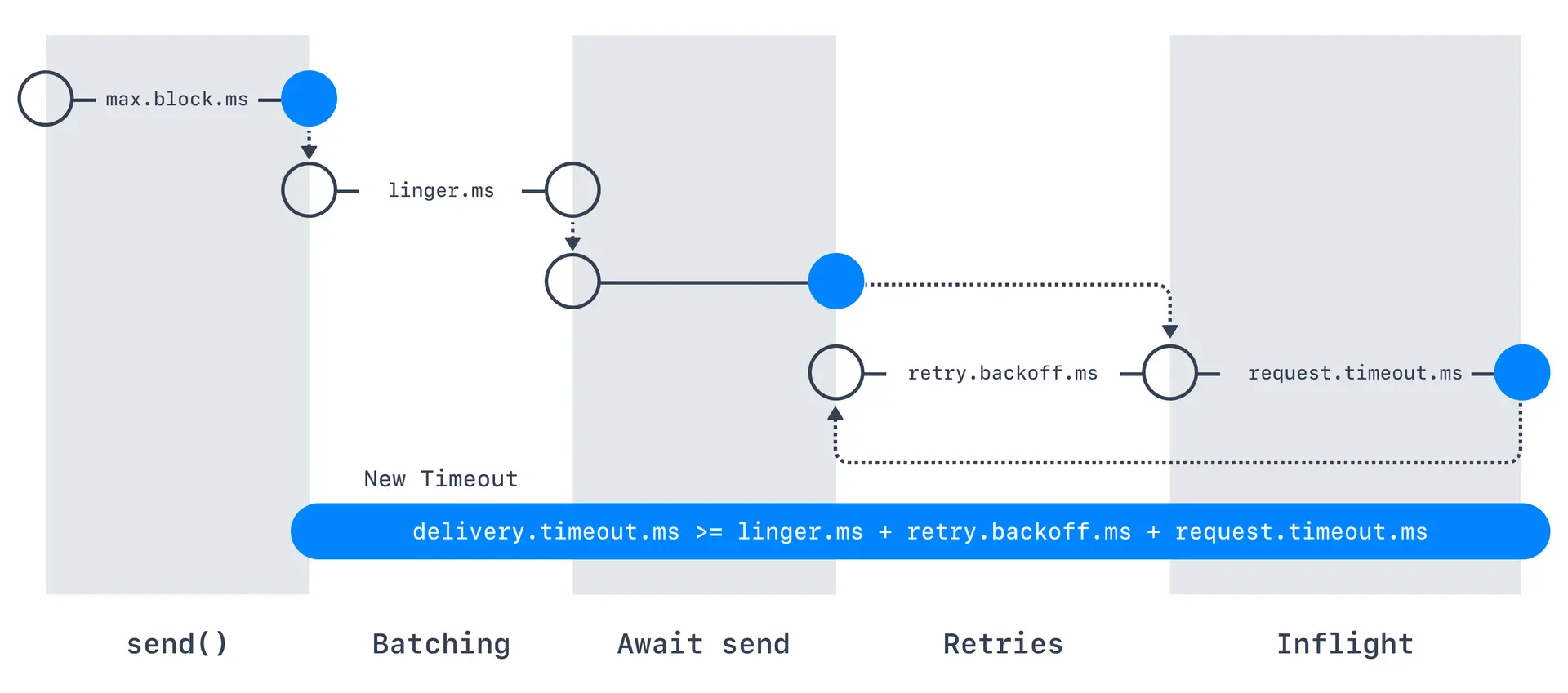
재시도
- 예외가 발생했는데 처리하지 않고 재시도 하는 방법이 있다
- 카프카 2.0에서는 기본값이 0이고 2.1 이상부터는 2^31승이다
retry.backoff.ms로 다음 재시도까지 대기 시간을 설정할 수 있다- 재시도에도 타임아웃이 걸린다
delivery.timeout.ms=120000으로 즉 2분이다
- 메시지 배달이 대기시간과 Retry로 시간을 넘지만 않으면 성공적으로 한것으로 본다
- 재시도를 하게 되면 메시지를 반복적으로 보내게 되어 멱등적인 프로듀서로 메시지를 보내야 한다
- 그래서 키 기준 정렬 방식을 쓰면 문제가 될 수 있다
- 이럴 때 사용하는것이
max.in.flight.requests.per.connection으로 기본값은 5이고 옛날 버전이고 재시도 값이 있으면 1로 설정해야 키 기준 정렬 방식을 사용할 수 있다
- 최신 카프카는 멱등 프로듀서를 사용하면 된다
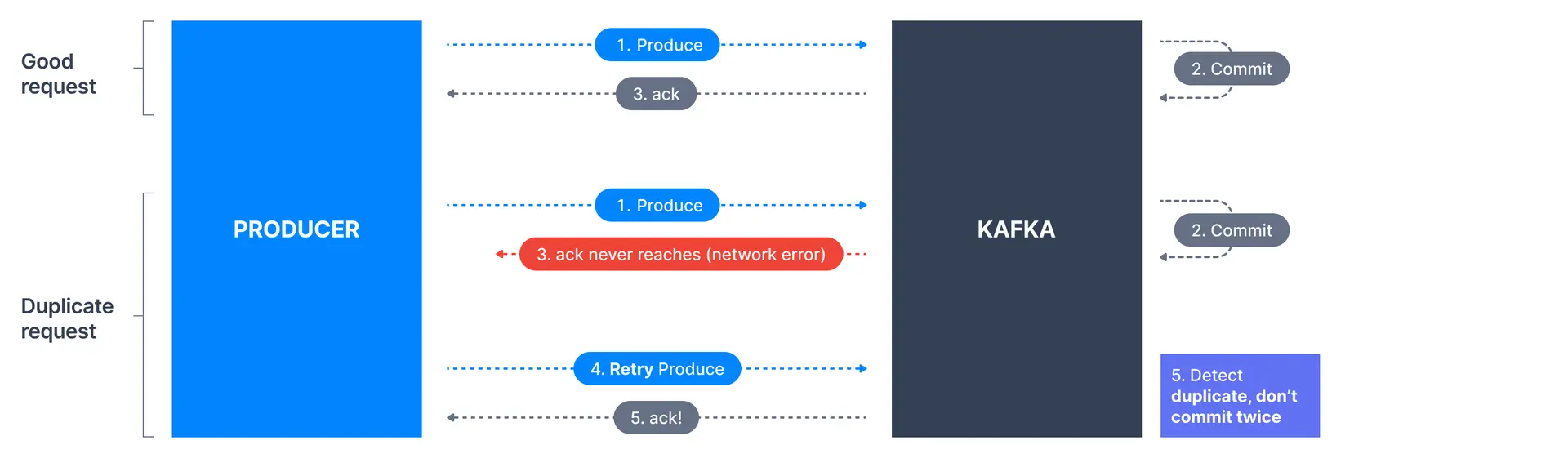
멱등 프로듀서
- 네트워크 오류로 인해 중복된 메시지가 전송될 수 있다
- 예를 들어 프로듀서가 메시지를 보내고 카프카가 응답확인을 보냈는데 네트워크 오류로 인해 응답확인을 보냈지만 프로듀서에게 전달되지 못한다
- 그러면 프로듀서는 메시지 전달을 못받은 걸로 간주하고 다시 보내게 된다
- 이를 카프카는 새로운 요청으로 여기고 중복된 데이터를 커밋하게 된다
- 이를 해결하기 위해 멱등 프로듀서를 사용한다
멱등 프로듀서
- 네트워크 오류에도 중복을 허용하지 않는 멱등 프로듀서가 있다
- 오류로 같은 메시지를 보내더라도 카프카가 중복 생성 요청임을 알아채고 두 번 커밋하지 않는다
- 3.0에서 이상에서는 디폴트로 사용한다
- 사용하려면
enable.idempotence=true로 설정하면 된다
properties.setProperty(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");
properties.setProperty(ProducerConfig.ACKS_CONFIG, "all");
properties.setProperty(ProducerConfig.RETRIES_CONFIG, Integer.toString(Integer.MAX_VALUE));
메시지 압축
- 보통은 프로듀서 데이터를 전송할 때 텍스트로 된 데이터를 전송한다
- 압축을 하게 되면 메시지 크기가 줄어들어 전송 속도가 줄어들어 디스크 내 저장공간을 적게 차지한다
- 압축은 프로듀서 레벨, 브로커 레벨, 토픽 레벨에서 압축을 할 수 있다
- 압축 타입
compression.type은 none, gzip, lz4, snappy, zstd 등 다양한 타입을 지원한다
- 메시지 배치의 크기가 클수록 압축률이 올라가 효율이 증가한다
- 먼저 snappy 또는 lz4를 사용하는 걸 권장한다 메시지가 텍스트라면 snappy가 좋다

압축 레벨
- 브로커 레벨에서 진행되면 모든 토픽이 압축이 된다
- 토픽 수준에서 활성화되면 해당 토픽에만 적용된다
compression.type=producer가 기본값으로 브로커는 프로듀서가 압축한 데이터를 재압축하지 않고 토픽의 로그 파일에 바로 저장한다
- 최적의 방법이지만 프로듀서가 압축하는 책임을 가진다
compression.type=none 압축한 모든 데이터를 브로커가 압축을 해제한다- 예를들어
compression.type=lz4 이렇게 설정하면 특정한 유형의 압축을 사용하도록 설정할 수 있다
- 토픽에 설정된 압축 유형이 프로듀서 설정의 유형과 일치하면 데이터가 다시 압축되지 않는다
- 압축 방법이 다르다면 브로커가 배치를 압축 해지하고 명시된 압축방법으로 다시 압축한다
- 추가 CPU 사이클을 소비하므로 기본값 설정하는 것이 좋다
- 프로듀서 설정을 건드릴 수 없어 압축을 활성화하고 싶은 경우 브로커에서 압축을 활성화해야 한다
linger.ms & batch.size
max.in.flight.requests.per.connection은 프로듀서와 브로커 사이에 최대 5개의 메시지 배치가 전송될 수 있다는 것을 의미한다 (병렬처리)
- 메시지 배치를 처리할 수 없을 때는 메시지 배치를 모은다
- 배칭 매커니즘에 영향을 주는 두 개의 설정이 있다
- linger.ms: 기본값은 0으로 배치를 전송할 때까지 대기하는 시간이다
- 5ms로 설정하면 메시지를 전송하기 5ms 동안 배치에 메시지를 추가한다
- batch.size:
batch.size가 다 차면 linger.ms이 되기 전에 배치를 전송한다
- 기본값은 16KB로 그 이상으로 늘리게 되면 압축률, 처리량, 요청의 효율이 늘어난다
- 배치크기보다 큰 메시지가 있는 경우 바로 전송한다
- 배치는 전송하는 파티션마다 하나씩 할당되므로 너무 큰 값을 할당하게 되면 메모리가 낭비된다
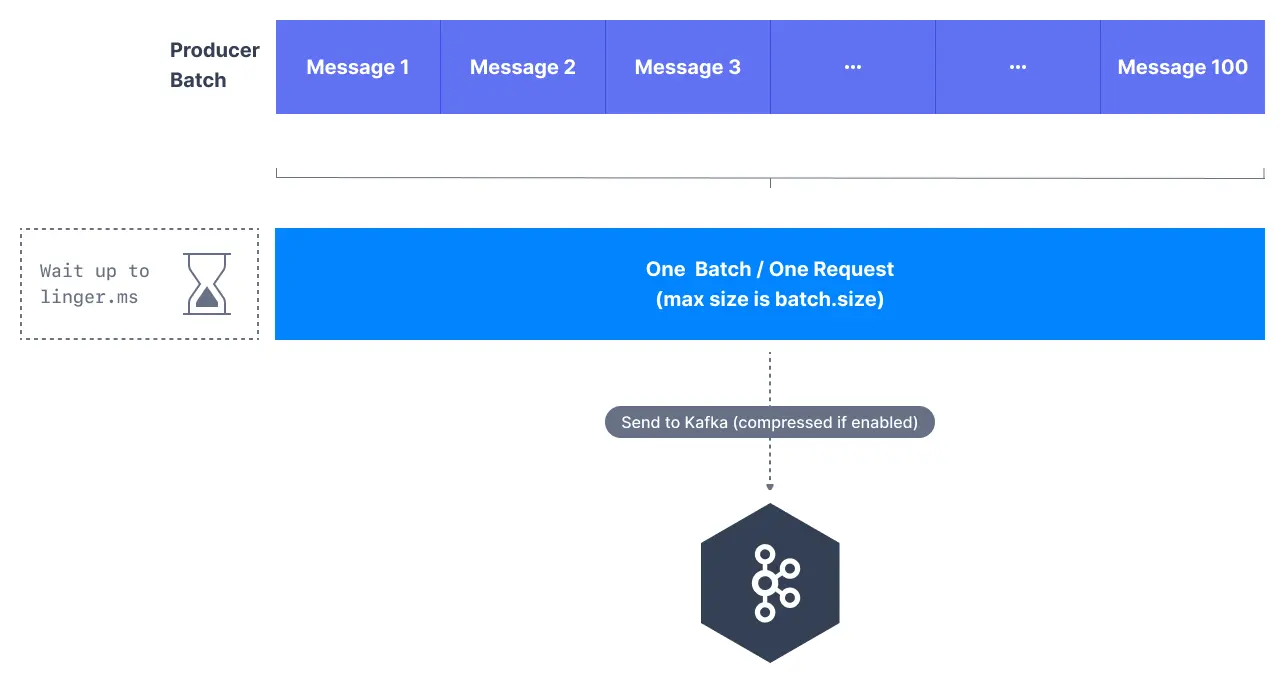
properties.setProperty(ProducerConfig.LINGER_MS_CONFIG, "20");
properties.setProperty(ProducerConfig.BATCH_SIZE_CONFIG, Integer.toString(32 * 1024));
properties.setProperty(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");
Default Partitioner
