성능이 느려지는 3가지 요인
- 동시 사용자 수의 증가
- 데이터 양의 증가
- 비효율적인 SQL문 작성
DB 성능 개선시 필요한 개초 개념
- 인덱스
- 실행 계획
1. DB 성능개선 방법
- SQL 튜닝
- 캐싱 서버 활용 (Redis 등)
- 레플리케이션 (Master/Slave 구조)
- 샤딩
- 스케일업 (CPU, Memory, SSD 등 하드웨어 업그레이드)
그중에 SQL튜닝을 먼저 고려해야 한다
- SQL 튜닝을 제외한 나머지 방법은 추가적인 시스템을 구축해야 한다
- 조금 더 복잡해진 시스템구조로 관리비용과 금전적, 시간적 비용이 든다
- 하지만 SQL 튜닝은 기존의 시스템 변경없이 성능을 개선할 수 있다
- 근본적인 문제를 해결하는 방법은 SQL 튜닝
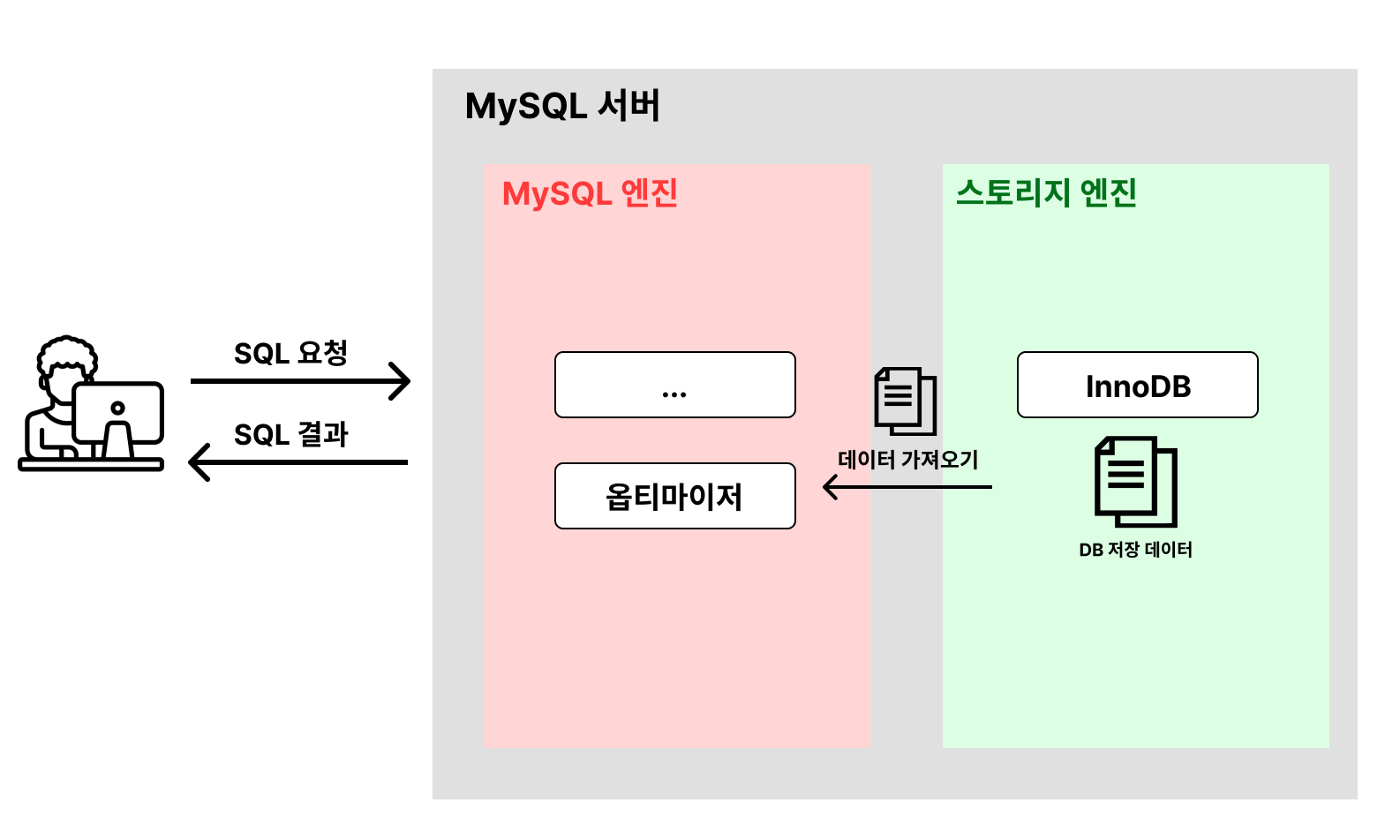
2. MySQL 구조
- 클라이언트가 DB에 SQL 요청을 보낸다
- MySQL 엔진에서 옵티마이저가 SQL문을 해석한 후 빠르고 효율적으로 데이터를 가져올 수 있는 계획을 세운다. 어떤 순서로 테이블을 접근할 지, 인덱스를 사용할 지, 어떤 인덱스를 사용할 지 등을 결정 한다
-> 옵티마이저가 세운 계획은 완벽하지 않다. 따라서 SQL 튜닝이 필요하다 - 옵티마이저가 세운 계획을 바탕으로 스토리지 엔진에서 데이터를 가져온다
-> DB 성능에 문제가 생기는 대부분의 원인은 스토리지 엔진으로부터 데이터를 가져올 때 발생 - MySQL 엔진에서 정렬, 필터링 등의 마지막 처리를 한 뒤에 클라이언트에게 SQL 결과를 응답
SQL 튜닝의 핵심
- 스토리지 엔진에서 데이터를 찾기 쉽게 바꾸기
- 스토리지 엔진으로부터 가져오는 데이터의 양 줄이기
가장 많이 활용되는 방법은 인덱스 활용이다.
-> 무작정 인덱스를 적용한다고 해서 해결되는게 아니라 적절하게 활용해야 한다
1). 인덱스
- 데이터를 빨리 찾기 위해 특정 컬럼을 기준으로 미리 정렬해놓은 표
- 예를 들어 나이 기준으로 정렬해놓은 표가 있다면 23살로 시작하는 지점과 24살로 시작되는 지점만 찾은 뒤에 그 사이에 있는 값들을 찾아오면 된다. 모든 데이터를 일일히 찾아올 필요 없다
# 인덱스 생성
# CREATE INDEX 인덱스명 ON 테이블명 (컬럼명);
CREATE INDEX idx_age ON users(age);
# SHOW INDEX FROM 테이블명;
SHOW INDEX FROM users;(1). 기본키
- 대부분의 경우 테이블을 생성할 때 PK를 설정한다.
- PK의 특징 중 하나는 PK를 기준으로 정렬을 해서 데이터를 보관한다
- 이렇게 원본 데이터 자체가 정렬되는 인덱스를 보고 클러스터링 인덱스라고 부른다
- PK = 클러스터링 인덱스
(2). UNIQUE
- UNIQUE 제약조건을 추가하면 자동으로 인덱스를 추가한다
- 고유 인덱스라고도 부른다
- UNIQUE 옵션을 사용하면 인덱스가 같이 생성되기 때문에 조회 성능이 향상된다
(3). 인덱스를 많이 걸면 어떻게 될까
- 인덱스를 추가하면 조회성능은 향상되지만 추가와 삭제 성능은 하락된다
- 인덱스를 추가한다는 건 인덱스용 테이블이 추가적으로 생성된다는 뜻
- 원래 테이블과 인덱스용 테이블 둘 다에 데이터를 넣어야 하기 때문에 느릴 수 밖에 없다
- 조회를 제외한 나머지 삽입, 수정, 삭제 성능은 느려진다
- 즉 최소한의 인덱스만 사용해야 한다
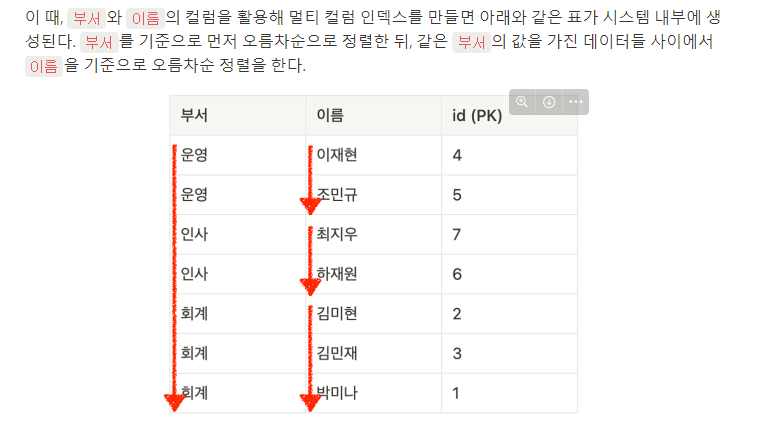
(4). 멀티 컬럼 인덱스
- 2개 이상의 컬럼을 묶어서 설정하는 인덱스
- 데이터를 찾기 위해 2개 이상의 컬럼을 기준으로 미리 정렬해놓은 테이블
- 인덱스 생성:
CREATE INDEX idx_부서_이름 ON users (부서, 이름);

주의점
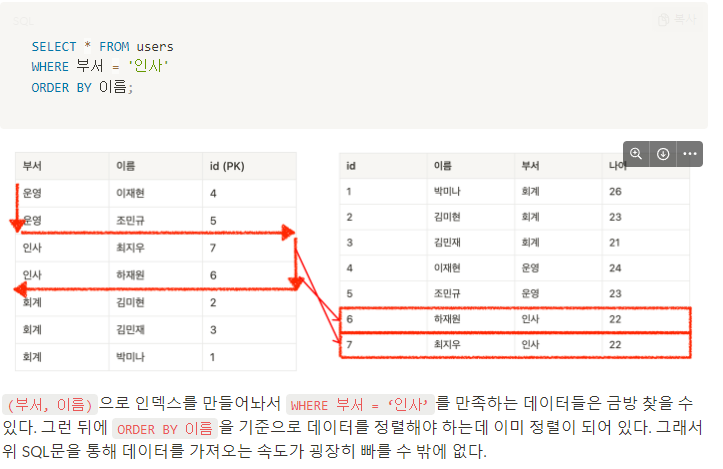
- 멀티 컬럼 인덱스는 일반 인덱스처럼 사용할 수 있다
- 부서를 기준으로 정렬이 되어있고 부서내에서 이름이 정렬되어 있기 때문에 부서컬럼만 놓고 봤을때는 부서 인덱스와 동일한 정렬 상태를 갖고 있다
- 하지만 이름 컬럼은 인덱스처럼 사용할 수 없다. 이름 순으로 정렬이 되어있지 않기 때문에
- 따라서 멀티 컬럼 인덱스에서 일반 인덱스처럼 활용할 수 있는 건 처으멩 배치된 컬럼들뿐이다.
멀티컬럼 인덱스를 구성할 때 대분류 -> 중분류 -> 소분류 컬럼순으로 구성하기
- 어떻게 순서를 정하냐에 따라 성능차이가 난다
- 10층짜리 회사에서
박미나를 찾아야 한다고 가정해보면.박미나가 속한부서를 먼저 찾은뒤에부서에서박미나를 찾는게 편하다박미나를 먼저 찾고부서를 물어보는 건 오래 걸린다- 따라서 멀티 컬럼 인덱스를 구성할 때 데이터 중복도가 높은 컬럼이 앞쪽에 오는게 좋은 경우가 많다
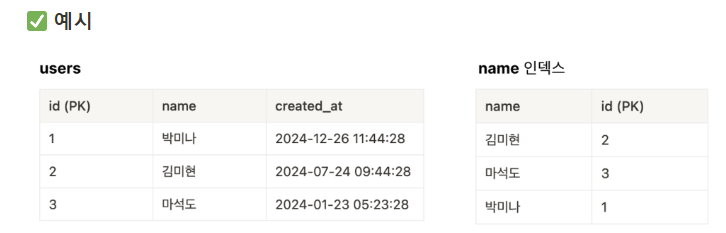
(5). 커버링 인덱스
- SQL문을 실행시킬 때 필요한 모든 컬럼을 갖고 있는 인덱스
- 예를 들어 이름과 id만 갖고오면 SQL을 짠다면
select id, name from users
-> 인덱스만으로도 조회가 가능하다. 이것을 바로 커버링 인덱스라고 한다 - 커버링 인덱스가 있는 경우에는 실제 DB로 가서 조회하지 않고 인덱스로만 조회를 한다
3. SQL문의 실행계획 사용해보기
1. 실행계획
- 옵티마이저가 SQL문을 어떤 방식으로 어떻게 처리할지를 계획한걸 의미
- 이 실행계획을 보고 비효율적으로 처리하는 방식이 있는지 점검하고, 비효율적인 부분이 있다면 효율적인 방법으로 SQL문을 실행하게끔 튜닝을 하는 게 목표다
- rows랑 filtered는 정확한 값이 아니라 추정값이다
2. 실행 계획 조회하기
# 실행 계획 조회하기 EXPLAIN [SQL문] # 실행 계획에 대한 자세한 정보 조회하기 EXPLAIN ANALYZE [SQL문] # 예시 EXPLAIN SELECT * FROM users WHERE age = 23;

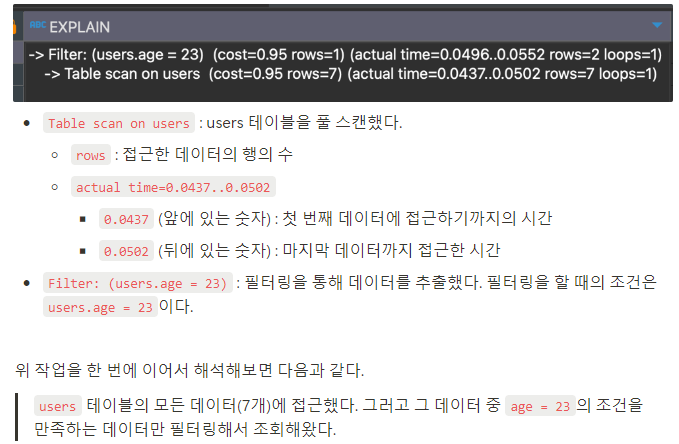
3. 실행 계획에 대한 자세한 정보 조회하기
EXPLAIN ANALYZE SELECT * FROM users WHERE age = 23;
- 밑에서부터 올라오면서 읽으면 된다
- actual time에서 앞쪽은 읽지말고 뒤쪽만 일거엇 users 풀스캔이 0.0502ms 걸렸다고 알면 된다
- 이 작업을 할때 접근할 데이터 수가 7개
- 그 다음 필터링을 한다는 것이다 0.0552는 전체 시간이다 필터링 시간자체는 0.0552 - 0.0502 하면 된다
1). 실행 계획에서 TYPE 의미 분석
1. ALL : 풀테이블 스캔
- 풀 테이블 스캔: 인덱스를 활용하지 않고 테이블을 처음부터 끝까지 뒤져서 데이터를 찾는 방식
- 처음부터 끝까지 다 뒤져서 필요한 데이터를 찾는 방식이다 보니 비효율적이다
2. Index: 풀 인덱스 스캔
- 풀 인덱스 스캔: 인덱스 테이블을 처음부터 끝까지 다 뒤져서 데이터를 찾는 방식
- 인덱스 테이블은 실제 테이블보다 크기가 작기 때문에 풀 테이블스캔보다 효율적이다
- 하지만 인덱스 테이블 전체를 읽어야 하기 때문에 아주 효율적이라고 볼 수 없다
3. Const: 1건의 데이터를 바로 찾을수 있는 경우
- 조회하고자 하는 1건의 데이터를 헤매지 않고 단번에 찾아올 수 있을 때 const 출력
- 고유 인덱스 또는 기본 키를 사용해서 1건의 데이터만 조회하는 경우 const가 출력
- 고유하다면 1건의 데이터를 찾는 순간 나머지 데이터는 볼 필요가 없어진다
4. Range: 인덱스 레인지 스캔
- 인덱스 레인지 스캔: 인덱스를 활용해 범위 형태의 데이터를 조회한 경우
- 범위형태: between, 부등호, in, like를 활용한 데이터 조회
- 효율적이지만 데이터를 조회하는 범위가 클 경우 성능 저하의 원인이 되기도 한다
5. Ref: 비고유 인덱스를 활용하는 경우
- 비고유 인덱스를 사용한 경우(UNIQUE가 아닌 컬럼의 인덱스를 사용한 경우)
- UNIQUE가 아니기 때문에 중복되는 값이 있을 수 있다
- 예를 들어 박지성을 찾는데 정렬은 되어있기 때문에 그 밑에 또 박지성이 있는 경우
4. SQL문 튜닝 연습
- 조회 데이터가 많아질수록 성능이 느려지는건 어쩔수없다. 페이지네이션으로 조금씩 가져오자
- 조회를 할 때 인덱스를 만들면 조회가 훨씬 빨라진다
- 부등호, in, between같은건 인덱스를 사용하면 성능이 향상될 가능성이 높다
- 데이터 액세스를 크게 줄일 수 있는 컬럼은 중복정도가 낮은 컬럼이다
- 범위가 넓으면 인덱스를 이용하더라도 다시 원래 테이블에서 일일이 찾아야하니까 차라리 그냥 테이블에 바로 접근해서 정렬시키는게 더 빠르다고 판단한다
-> 그래서 범위를 좁혀서 조회해야 인덱스로 빠르게 접근할 수 있다 - 정렬은 시간이 오래걸리는 작업, 인덱스를 활용하면 자동으로 정렬이 되기 때문에 좋다
컬럼을 가공하면 인덱스를 활용하지 않는다
# User000000으로 시작하는 이름을 가진 유저 조회 EXPLAIN SELECT * FROM users WHERE SUBSTRING(name, 1, 10) = 'User000000'; # 2달치 급여(salary)가 1000 이하인 유저 조회 SELECT * FROM users WHERE salary * 2 < 1000 ORDER BY salary;
그래서 컬럼을 가공하지 않아야한다
# User000000으로 시작하는 이름을 가진 유저 조회 EXPLAIN SELECT * FROM users WHERE name LIKE 'User000000%'; # 2달치 급여(salary)가 1000 이하인 유저 조회 EXPLAIN SELECT * FROM users WHERE salary < 1000 / 2 ORDER BY salary;
1). Where문에 인덱스 vs Order By에 인덱스
- 사실 정답은 없다 실행계획을 보고 결정해야 한다
- 하지만 보통 where절로 검색결과를 줄이고 order를 하는게 더 나을 가능성이 높다
- salary로 인덱스를 만들면 일단 where절에 조건에 맞는지 확인하기 위해서 원래 테이블에서 데이터를 가져와야 하기 때문에 더 비효율적으로 작동을 해버린다
EXPLAIN SELECT * FROM users
WHERE created_at >= DATE_SUB(NOW(), INTERVAL 3 DAY)
AND department = 'Sales'
ORDER BY salary
LIMIT 100;2). Having문 SQL 튜닝
- having은 group by를 처리한다음 having을 하기 때문에 비효율적이다
- where로 처리할 수 있는건 where로 먼저 처리를 하고 group by, having을 해야한다
5. 실습
1). 유저이름으로 특정기간에 작성된 글 검색
SELECT p.id, p.title, p.created_at
FROM posts p
JOIN users u ON p.user_id = u.id
WHERE u.name = 'User0000046'
AND p.created_at BETWEEN '2022-01-01' AND '2024-03-07';# 인덱스 추가
CREATE INDEX idx_name ON users (name);
CREATE INDEX idx_created_at ON posts (created_at);
# posts.created_at 인덱스를 추가하더라도 사용하는 게 비효율적이라고 판단되어서 사용하지 않았다2). 특정 부서에서 최대 연봉을 가진 사용자 조회
SELECT *
FROM users
WHERE salary = (SELECT MAX(salary) FROM users)
AND department IN ('Sales', 'Marketing', 'IT');# department가 중복도도 높고 3개가 검색해야 되기 때문에 salary로 인덱스를 거는게 효과적이다
CREATE INDEX idx_salary ON users (salary);3). 부서별 최대 연봉을 가진 사용자들 조회
SELECT u.*
FROM users u
JOIN (
SELECT department, MAX(salary) AS max_salary
FROM users
GROUP BY department
) d ON u.department = d.department AND u.salary = d.max_salary;# department 그룹을 한 뒤에 최대연봉을 찾는거니까 멀티컬럼이 효과적이다
CREATE INDEX idx_department_salary ON users (department, salary);4). 2023년 주문 데이터 조회
# 인덱스를 가공해서 쓰고 있기 때문에 인덱스를 제대로 활용하지 못한다
SELECT *
FROM orders
WHERE YEAR(ordered_at) = 2023
ORDER BY ordered_at
LIMIT 30;
# 이런식으로 컬럼을 가공하지 않아야 인덱스를 제대로 활용한다
SELECT *
FROM orders
WHERE ordered_at >= '2023-01-01 00:00:00'
AND ordered_at < '2024-01-01 00:00:00'
ORDER BY ordered_at
LIMIT 30;# 간단하게 주문 시간을 인덱스로 만들면 된다
CREATE INDEX idx_ordered_at ON orders (ordered_at);5). 2024년 1학기 평균 성적이 100점인 학생 조회
# 성능향상 전 SQL문
SELECT
st.student_id,
st.name,
AVG(sc.score) AS average_score
FROM
students st
JOIN
scores sc ON st.student_id = sc.student_id
GROUP BY
st.student_id,
st.name,
sc.year,
sc.semester
HAVING
AVG(sc.score) = 100
AND sc.year = 2024
AND sc.semester = 1;# having에 있는 조건은 where로 옮겨야 데이터를 적게 검색하기 때문에 성능이 향상된다
SELECT
st.student_id,
st.name,
AVG(sc.score) AS average_score
FROM
students st
JOIN
scores sc ON st.student_id = sc.student_id
WHERE
sc.year = 2024
AND sc.semester = 1
GROUP BY
st.student_id,
st.name
HAVING
AVG(sc.score) = 100;6). 좋아요 많은 순으로 게시글 조회
# 성능개선 전 SQL
# join을 하기 위해서 post의 100만건 데이터 like의 100만건 데이터를 훑었다
# 200만건 이상의 데이터를 모았기 때문에 시간이 오래걸렸다
# 좋아요 많은수를 먼저 알고 실행하면 어떨까?
SELECT
p.id,
p.title,
p.created_at,
COUNT(l.id) AS like_count
FROM
posts p
INNER JOIN
likes l ON p.id = l.post_id
GROUP BY
p.id, p.title, p.created_at
ORDER BY
like_count DESC
LIMIT 30;# likes 테이블로 먼저 좋아요순으로 정렬을 했다 (inner Join)
# 그러면 좋아요가 제일많은 30개가 나올테니까 그걸 가지고 기존에 있었던 테이블과 조인을 한다
# 이렇게 되면 조인이 되는 데이터 수가 확 줄어드니까 성능이 향상된다
SELECT p.*, l.like_count
FROM posts p
INNER JOIN
(SELECT post_id, count(post_id) AS like_count FROM likes l
GROUP BY l.post_id
ORDER BY like_count DESC
LIMIT 30) l
ON p.id = l.post_id;