개요
- 데이터베이스: 데이터를 체계적으로 모아 놓은 핵심 저장소
1. 데이터와 정보
- 정보가 있어야 의사결정을 제대로 내릴 수 있다
- 데이터베이스가 데이터를 체계적으로 저장하고(1.5단계), 우리가 원하는 조건으로 쉽고 빠르게 찾아내고 가공해서(2단계) 정보로 만들 수 있도록 도와주는 강력한 도구이다
1).데이터
- 아직 가공되지 않는 개별적인 사실이나 값 그자체를 의미한다
- 예) 쇼핑몰의 주문기록:
user01, 티셔츠, 25,000
- 이 데이터들만 봐서는 user01이 누구인지, 티셔츠르 산건지 반품한 건지 알 수가 없다
1.5). 구조화된 데이터
- 현실에서는 엑셀같은 곳에 수집단계에서부터 최소한의 구조를 가지고 정리한다
- 하지만 기록의 목록일 뿐이고,
어떤 상품이 인기가 많을까에 대한 대답은 할 수 없다
| 주문번호 | 고객ID | 상품명 | 수량 | 주문금액 | 주문일자 |
|----------|--------|--------------|------|------------|-------------|
| 10001 | C001 | 사과 1kg | 2 | 20,000원 | 2025-08-01 |
| 10002 | C002 | 바나나 1송이 | 1 | 5,000원 | 2025-08-02 |
| 10003 | C001 | 딸기 500g | 3 | 15,000원 | 2025-08-03 |
| 10004 | C003 | 우유 1L | 2 | 4,000원 | 2025-08-03 |
| 10005 | C004 | 계란 30구 | 1 | 7,500원 | 2025-08-04 |
2). 정보 - 목적을 가진 결과물
- 구조화된 데이터를 특정한 목적을 가지고 분석하고 가공해서 얻어낸 유의미한 결과물이다
- 그룹핑을 해서 티셔츠가 딸기가 가장 많이 팔렸다는 걸 알 수 있고, 특정 일자의 매출액 등을 알 수 있다
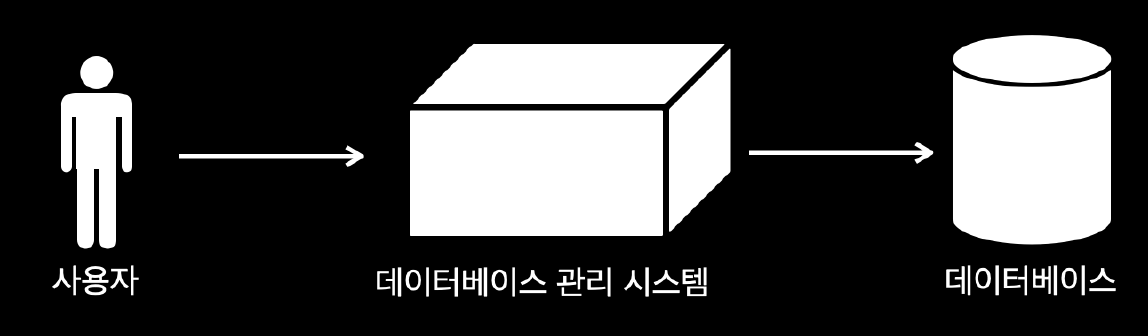
2. RDBMS
- DB를 효율적으로 관리하는 소프트웨어이다
- DBMS는 데이터를 보다 체계적이고 안전하고 효율적으로 관리할 수 있는 추상화된 방법을 제공한다
1). 역할과 기능
- 데이터 정의 기능(DDL): DB의 구조를 정의할 수 있는 기능을 제공한다
- 데이터 조작 기능(DML): CRUD를 효율적이고 편리하는 방법을 제공한다
- 보안, 동시성 제어, 트랜잭션 관리 기능
- 데이터 중복 최소화 및 일관성 유지: 정규화 과정을 통해 불필요한 데이터 중복을 줄인다
- 데이터 백업 및 복구
2). 기본 개념
- 테이블: RDB에서 데이터를 저장하는 가장 기본적인 구조이다
- 행: 테이블의 각 가로줄을 의미한다
- 개별적인 데이터 항목 하나를 나타낸다
- 레코드 또는 튜플이라고 불린다
- 열: 테이블의 각 세로줄을 의미한다
- 테이블에 어떤 종류의 데이터가 저장될지를 정의한다
- 속성 또는 필드로 불린다
| 주문번호 | 고객ID | 상품명 | 수량 | 주문금액 | 주문일자 |
|---|
| 10001 | C001 | 사과 1kg | 2 | 20,000원 | 2025-08-01 |
| 10002 | C002 | 바나나 1송이 | 1 | 5,000원 | 2025-08-02 |
| 10003 | C001 | 딸기 500g | 3 | 15,000원 | 2025-08-03 |
| 10004 | C003 | 우유 1L | 2 | 4,000원 | 2025-08-03 |
| 10005 | C004 | 계란 30구 | 1 | 7,500원 | 2025-08-04 |
1. 기본키
- 데이터를 구분할 수 있는 유일한 키
- 테이블에 있는 모든 행들 중에서 특정 행 하나를 유일하게 식별할 수 있는 열 또는 열들의 조합이다
- 2가지 규칙
- 고유성: 기본키로 지정된 값은 중복될 수 없다
- NOT NULL: 반드시 값이 있어야 한다. 비어있거나(NULL) 값이 없는 상태는 허용되지 않는다
2. 외래키
- A의 열(Column)이 다른 테이블(B)의 기본키를 참조하는 것을 말한다
- 두 테이블을 연결하는 관계의 고리 역할을 한다.
- FK값을 가진 곳이 자식 테이블이다
- 중요한 규칙
- 참조 무결성: FK는 반드시 부모 테이블의 기본키 값중 하나이거나 비어있어야 한다
- 존재하지 않는 값을 넣으려고 하면 오류를 발생시켜 정합성을 보장한다
SQL
- Structured Query Language: 구호좌된 질의 언어
- ISO/ANSI에 의해 표준이 정해진 관계형 데이터베이스의 표준언어이다
1. DDL
- Data Definition Language: 데이터 정의어
- 데이터의 구조를 정의하고 관리하는 언어이다
- 주요 명령어:
CREATE, ALTER, DROP
CREATE DATABASE MY_SHOP;
USE MY_SHOP;
CREATE TABLE sample(
product_id INT PRIMARY KEY,
name VARCHAR(100),
price INT,
stock_quantity INT,
release_date DATE,
constraint fk_orders_customers foregin key (customer_id) references customers(customer_id),
constraint fk_orders_products foregin key (product_id) references products(product_id)
);
DESC sample;
DROP TABLE sample;
alter table customers
add column point int not null
alter table customers
modify column address varchar(255) not null;
alter table customers
drop column point;
SET FOREIGN_KEY_CHECKS = 0;
SET FOREIGN_KEY_CHECKS = 1;
TRUNCATE Table sample;
2. DML
- Data Manipulation Language: 데이터 조작어
- 테이블 안에 있는 실제 데이터를 직접 조작한다
- 주요 명령어:
INSERT, SELECT, UPDATE, DELETE
INSERT INTO sample (product_id, name, price, stock_quantity, release_date)
VALUES (1, 'iPhone', 10000000, 100, '2023-01-01');
update sample set stock_quantity = 400 where product_id = 1;
SELECT name,price FROM sample;
delete from sample where product_id = 1;
3. DCL
- Data Control Language: 데이터 제어어
- 데이터에 대한 접근 권한을 부여하거나 회수하는 등 보안과 관련된 권한을 제어한다
- 주요 명령어:
GRANT, REVOKE
4. TCL
- Transaction Control Language: 트랜잭션 제어어
- DML에 의해 수행된 데이터 변경 작업들을 하나의 거래단위로 묶어서 관리하는 언어이다
- 작업의 일관성을 보장하여 데이터가 잘못되는 것을 보장한다
- 주요 명령어:
COMMIT, ROLLBACK
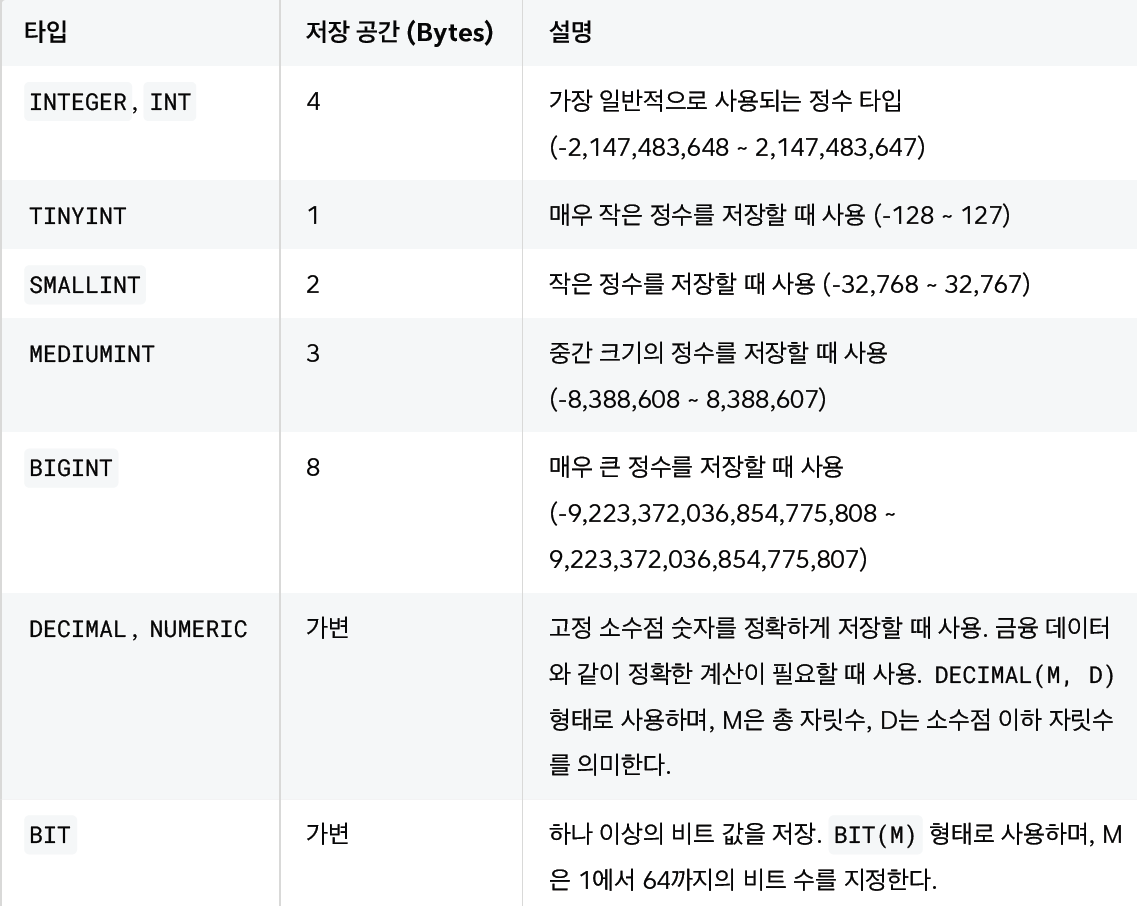
5.데이터 타입
1). 숫자타입
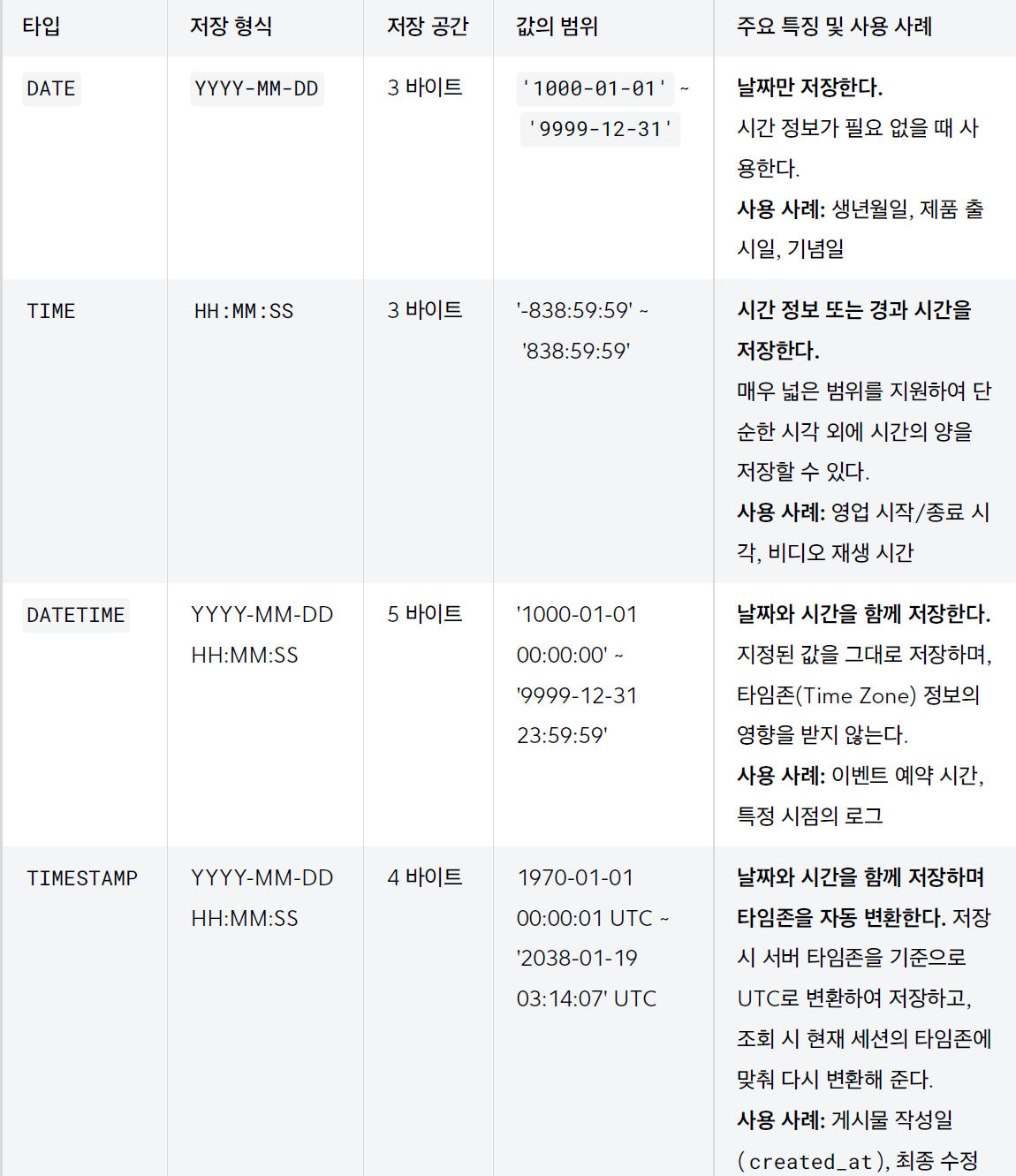
2). 날짜와 시간타입
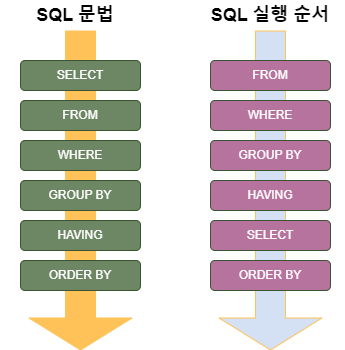
6. SQL 실행 순서
- FROM: 어떤 테이블에서 데이터를 가져올지 결정한다. Join도 마찬가지
- WHERE: 테이블의 개별 행을 필터링한다
- GROUP BY: Where절의 필터링을 통과한 행들을 기준으로 그룹을 형성한다
- HAVING:
Group By를 통해 만들어진 그룹들을 필터링한다
- SELECT: 최종 그룹들에 대해 우리가 보고자 하는 컬럼을 선택한다
- ORDER BY: 지정된 순서로 정렬한다
- LIMIT: 정렬된 결과 중에서 최종적으로 사용자에게 반환할 행의 개수를 제한한다