다중 접속 서버
다중접속 서버란 ?
둘 이상의 클라이언트의 동시접속을 허용하고, 동시에 서비스를 제공하는 서버
여기서 동시는 concurrency 이여도 괜찮다
다중 접속 서버를 구현하는 데에는 크게 3가지 방법이 있다
-
멀티프로세싱
-
멀티쓰레딩
-
멀티플렉싱
멀티 프로세싱 / 멀티 쓰레딩
멀티 프로세싱
이름과 같이 클라이언트의 요청 당 프로세스를 생성하는 방식의 멀티 프로세싱은 독립적인 프로그램의 개념인 프로세스를 사용하기 때문에 크게 어렵게 느껴지는 것은 없을 것이다
다만 프로세스를 생성하는 것은 오버헤드가 크고, 서버-클라이언트 구조에서 서버는 매번 비슷한 로직을 수행할 것이라고 기대하기 때문에 특별한 상황이 아니면 멀티 프로세싱은 지향하는 것이 나을 것이다
멀티 쓰레딩
클라이언트의 요청 당 쓰레드를 생성하는 방식을 멀티 쓰레딩이라고 한다
멀티 프로세싱 vs 멀티 쓰레딩
프로세스와 쓰레드의 차이를 비교하면 이해가 더 잘 될 것 같다
-
프로세스는 Context Switching 시 캐시, 레지스터 모두 초기화 시켜야하기 때문에 멀티 쓰레딩 보다 추가적인 시스템 콜 이 발생한다
-> 반대로 쓰레드는 stack 영역만 바꿔주면 되므로 비용이 적다. -
멀티 프로세싱에서 프로세스 자체가 독립되어 있기 때문에, 하나의 서버 로직에서 오류가 나도 다른 서버(프로세스)에 영향을 미치지 않는다
-> 반대로 멀티 쓰레딩은 하나의 쓰레드가 오류나면 전체 프로세스에 영향을 미칠 수 있다(자원을 공유하고 있기 때문) -
멀티 쓰레딩은 공유자원에 대한 동기화 로직을 추가해줘야한다.
멀티 프로세싱
새로운 프로세스를 생성하기 위한
fork 동작 자체가 현 프로세스의 메모리 영역을 완전히 복사 하기 때문에 오버헤드가 큰 작업이다
vfork 라는 부모 프로세스의 자원을 공유하면서 새로운 프로세스를 생성하는 방식이 있지만 race condition 을 방지하기 위해 부모 프로세스는 blocking 되고 자식 프로세스가 exit 될 때 까지 대기해야하는 단점(?) 이 존재한다
그럼에도 프로세스를 분리하는 이유는 한 쓰레드의 오류가 전체 프로세스에 전파되는 것을 막는 방식을 택하기 위해서일 것이다
코드
#include <unistd.h>
pid_t fork(void);해당 메소드 호출자는 부모 프로세스로 지정되며 메소드 반환값이 중요한데, 메소드 호출과 동시에 부모 / 자식 프로세스로 나뉘므로 각각의 리턴값이 달라진다
부모 : pid_t -> 자식의 pid
자식 : pid_t -> 0
좀비 프로세스
앞서 fork 에 생성된 프로세스를 자식 프로세스라고 했는데 부모-자식 관계가 있기 때문에, 자식 프로세스가 종료되면 부모 프로세스가 그 사실을 알고 종료정보를 확인해줘야한다
만약 확인하지 않고 가만히 냅둔다면 자식 프로세스는 좀비 프로세스 로 변환된다.
큰 의미가 있는 것은 아니고, 그냥 로직은 더이상 존재하지 않는데 메모리 리스소를 놓아주지않고 있는 프로세스를 의미한다
이를 막기 위해 부모 프로세스에서 wait 메소드를 통해 자식 종료 정보를 확인
#include <sys/wait.h>
pid_t wait(int* status)리턴값 : 자식 pid
status : 종료 정보
wait 호출 시 자식 프로세스가 종료된 정보를 확인하고, 확인하면 자식 프로세스는 비로소 종료된다.
부모 - 자식 끼리만 서로 종료된 것을 확인(wait) 가능하다
단 wait 메소드는 프로세스가 블로킹 상태에 빠진다는 단점이 존재한다
논블로킹 처리가 가능한 메소드는 waitpid 이다
pid_t waitpid(pid_t pid, int* status, int options)위 메소드의 기본적인 목적은 특정한 pid 를 가지는 프로세스의 종료여부를 판단하는 것이다.
pid : 종료 여부를 확인할 pid, -1 입력 시 임의의 프로세스에 대해 대기
status : wait 와 동일
options : 요놈이 중요한데 여기에 WNOHANG 을 넣어야지만 논블로킹 메소드가 된다.
waitpid(pid, &status, WNOHANG) (wait no hang up)
이 외에도 멀티 프로세싱 상황에서
좀비 프로세스 관리는 signal 을 통해서 이루어지기도 한다
Signal
signal
특정 signal 이 발생하면 특정 func 이 호출된다
#include <signal.h>
void (*signal(int signo, void (*func)(int)))(int);좀 메소드 형태가 난해하긴 한데 풀어 쓰자면
리턴 값 : 이전에 등록한 함수 포인터
signo : signo 에 해당하는 signal 이 발생하면
func : function 이 실행된다
코드는 그냥 signal(SIGCHLD, func) 로 사용하면 된다
하지만 signal 메소드는 운영체제 별 동작방식의 차이가 있기 때문에 sigaction 을 주로 사용해야 한다
sigaction
struct sigaction
{
void (*sa_handler)(int)
sigset_t sa_mask
int sa_flags
}
int sigaction(int signo, const struct sigaction* act,
struct sigaction* oldact)signo : signo 에 해당하는 signal 이 발생하면
act : sigaction 에 등록된 메소드를 호출한다
oldact : 예전에 등록한 sigaction 저장
멀티 플렉싱
멀티 쓰레딩을 보기 전에 멀티 플렉싱 을 먼저 보도록 하자
멀티 플렉싱은 프로세스 차원에서 다수의 클라이언트를 서비스할 수 있도록 하는 기술이다.
하나의 프로세스에서 일전에 iterative서버 를 짠 적이 있는데, 해당 방식의 고질적인 문제는 한번에 하나의 클라이언트만 처리할 수 있다는 것이다
그 이유는 read 라던지 accept 라던지 블로킹 메소드들이 존재하기 때문인데
가령 iterative서버로 2명의 클라이언트를 동시에 다루려고 아래와 같이 구성하면
cli1 = accept(..
cli2 = accept(..
read(cli1..
(service logic for cli1)
read(cli2..
(service logic for cli2)
(next logic for cli1)
(next logic for cli2)
.
.
이 코드 까지만 봐도 사실 문제가 생길 수 있는데, cli2 에서 데이터를 굉장히 늦게 보낸다면? cli1 의 next logic 은 언제 실행될지 기약을 못 할 것이다.
그럼 상대방이 메세지를 보낸지 안보낸지 감지할 수 있다면?
cli1 = accept(..
cli2 = accept(..
(if cli1 데이터 송신 감지)
read(cli1..
(service logic for cli1)
(next logic for cli1)
(if cli2 데이터 송신 감지)
read(cli2..
(service logic for cli2)
(next logic for cli2)
위와같이 연결된 클라이언트 중 데이터를 송신한(블로킹 되지 않을) 클라이언트만 처리해줄 수 있을 것이다.
이런 방식을 지원해주는 것이 멀티 플렉싱 이다

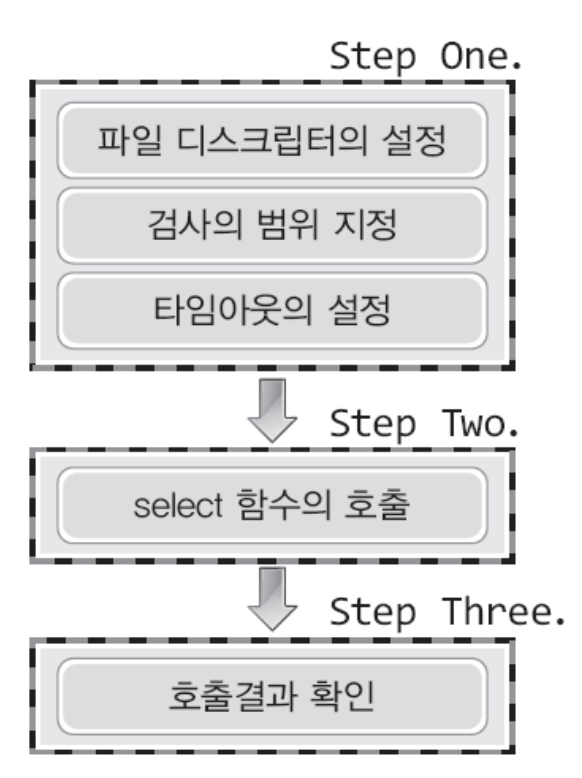
멀티 플렉싱의 과정은 크게 아래와 같이 나뉜다
관찰할 대상 지정(FD_SET) -> 관찰(select) -> 관찰결과 확인
FD_ZERO(fd_set* fdset)
FD_SET(int fd, fd_set* fdset)
FD_CLR(int fd, fd_set* fdset)
FD_ISSET(int fd, fd_set* fdset)관찰 대상 지정
위에서 부터 차례로
1. fdset 초기화 [0,0,0..]
2. 관찰할 fd 추가 [0,1,0..] -> 1추가 했을 때
3. 관찰 취소할 fd
4. fdset 에 fd 가 1 인가? true/false
이렇게 묶인 애들은 관찰 집합1 로 보면된다
관찰(select)
관찰 집합을 이제 관찰할건데 그 때 사용되는 메소드는 select 이다
#include <sys/select.h>
#include <time.h>
int select(int maxfd, fd_set* readset, fd_set* writeset,
fd_set* exceptset, const struct timeval* timeout)인자가 뭐가 굉장히 많은데 select 메소드는
"검사 집합에서 0번부터 몇개(maxfd)의 fd의 어떤 변화를 관찰할 것인가?" 라고 생각하면 될 것 같다
maxfd : 검사할 fd 수
readset : fd에 수신된 데이터가 존재하는지
writeset : 내가 데이터 보내면 바로 받을 수 있는 fd 가 있는지
exceptset : 오류값을 보내온 fd 가 있는지
확인할 fd_set 을 전달하면된다
timeout : 검사는 단 한번 하는게 아니라, select 메소드를 호출하면 변화가 있는 fd 가 1개 이상 나올 때 까지 블로킹 상태인데, 너무 오래 블로킹 되면 안되니깐 timeout 제한을 건다
하나 조심해야 하는건 select 메소드에 전달된 fd_set 은 변화가 있으면, 변화가 발생한 fd 값은 1로 바뀌고 나머지는 0으로 바뀐다.
즉, 변수 내부 값이 바뀌기 때문에 지속적으로 같은 fd 에 대해 관찰하고 싶다면 따로 temp 로 관찰할 set 을 저장해놔야한다.
반환 값
n : 변화 있는 fd 가 n개 있다
0 : timeout
-1 : error
관찰할 소켓은
최초에는 서버 소켓
그다음에 연결이 들어오면 연결하고 fd_set 에 넣고 fd_max 증가
select 할 때 fd_max 만큼 읽고
fd_max 는 현재 클라이언트 소켓 중 가장 큰 fd num 으로
-> 걔까지 관찰 하는게 맞으니깐
변화 있는 fd 가 서버 소켓이면 연결 요청이고
그게 아니면 클라이언트 요청 수행하면된다
수행하고 나서 클라이언트 set 에서 지우고
멀티 쓰레딩
쓰레드는 한 프로세스내에서 스택 공간을 제외한 나머지 영역을 공유하는 실직적인 스케줄링 단위를 의미한다
프로세스 내에서 생성되기 때문에 커널은 쓰레드의 존재를 모른다는 단점이 있지만 최근에는 1:1 연결 방식을 보편적으로 사용해서 실질적인 스케줄링 단위라고 불러도 무방하다
프로세스를 생성해서 로직을 수행하는 멀티 프로세싱은 위에서 언급했듯 그 비용이 너무 크다
다중 접속 서버의 주안점은 로직의 분할인데, 일반적으로 같은 로직은 분할된 시점 공통 동작을 하는 부분이 많을 것이기 때문에 항상 새로운 자원을 복사해서 쓸 필요가 없다는 것이다
따라서 서비스 와 사용자의 상태를 독립적으로 관리할 스택 영역을 제외하고, 나머지 영역은 공유가 가능하도록 하는 것이 쓰레드의 특징이다.
코드
#include <pthread.h>
pthread_t t1;
int param = 3;
pthread_create(pthread_t *thread_id, const pthread_attr_t *attr,
void*(*method_addr)(void*), void *args)thread_id : thread 또한 process 처럼 id 로 관리가 되는데, thread library 내에서 id 를 주입해준다
attr : attr flag
method_addr : 기본적으로 함수명은 함수의 주소를 의미한다
void* 는 반환형이 void 를 의미, *method_addr 은 함수 포인터 (void) 는 파라미터 포인터를 의미한다
args : 파라미터 주소
void * 는 타입에 의존하지 않는 코드를 만드는데 사용이 되는 것 같은데, thread 메소드에서 모든 형태의 메소드를 포함하고자 위와같이 메소드를 구성한 것 같다
블로킹
thread 또한 프로세스 내부에 있기 때문에 메인 쓰레드가 종료되면 전체 프로세스가 종료되고, 그러면 생성된 쓰레드가 동작을 마치기도 전에 종료가되는 문제가 생길 수 있다
이를 막기 위해 pthread_join method 가 존재한다
pthread_join(pthread_t thread, void **status)thread 와 같은 id 의 thread 가 종료가되면 블로킹이 해제가 되는 waitpid 와 매우 유사한 함수이다
임계 영역 처리
공유자원이 존재할 때 고려해야하는 부분은 바로 임계 영역이다
race condition 이 발생할 수 있는 영역인 만큼 동기화 로직이 필요할 때가 있는데, 특히나 클라이언트 소켓의 데이터를 받아서 로직을 수행하는 구조에서는 동기화 처리가 중요하다
동기화 처리를 위해서는 뮤텍스와 세마포어를 이용해서 처리할 수 있는데, 뮤텍스 세마포어에 대한 자세한 설명은 별도의 포스팅에서 하고 코드만 살펴보도록 한다
pthread_mutex_t m1;
int pthread_mutex_init(pthread_mutext_t* mutex, const pthread_mutexattr_t* atrr);
int pthread_mutex_destroy(pthread_mutex_t *mutex);mutex type 변수를 넘겨주면 특정 값을 주입해주고, 이제 해당 뮤텍스에 대해서는 lock, unlock 작업(atomic operation, H/W 에서 지원) 을 통해 동기화 로직을 수행한다
int pthread_mutex_lock(pthread_mutex_t* mutex) ;
int pthread_mutex_unlock(pthread_mutex_t* mutex);강의 시간에 들었던 로직을 상기해보자면
lock 를 호출한 쓰레드가 여러개 있을 건데, 지속적으로 mutex 검증(false 면 true 로 바꾸고 false 반환, true 면 그대로 true 반환) 과정을 통해서 블로킹을 해제할지를 판단한다
블로킹이 해제된 쓰레드는 단 하나일 거고, 공유자원에 대한 수정작업을 수행한다.
#include <semaphore.h>
sem_t s1;
int sem_init(sem_t *sem, int pshared, unsigned int value);
int sem_destroy(sem_t *sem);pshared 를 통해서 서로 다른 프로세스에서 접근가능한 세마포어를 생성할지 여부를 결정
value 를 통해서 세마포어 count 변경
int sem_post(sem_t *sem);
int sem_wait(sem_t *sem);뮤텍스와 같이 동기화 처리에 사용되는 세마포어는 뮤텍스와 다르게 공유자원을 사용할 수 있는 쓰레드의 수를 1개 이상으로 제한할 수 있는 특징을 가진다
