지금까지 정리해본 신경망 모델들은 데이터의 순서와 상호작용을 인식하여 전체 상황을 이해하는 능력이 부족하다. 현실에서 접하는 경험과 데이터는 순차적이기 때문에 데이터가 순서대로 나열된 순차적 데이터의 정보를 받아 전체 내용을 학습하는 RNN에 대해 정리해보았다.
* RNN -> 정해지지 않은 길이의 배열을 읽고 설명하는 신경망
* 주로 텍스트와 자연어 처리에 사용된다.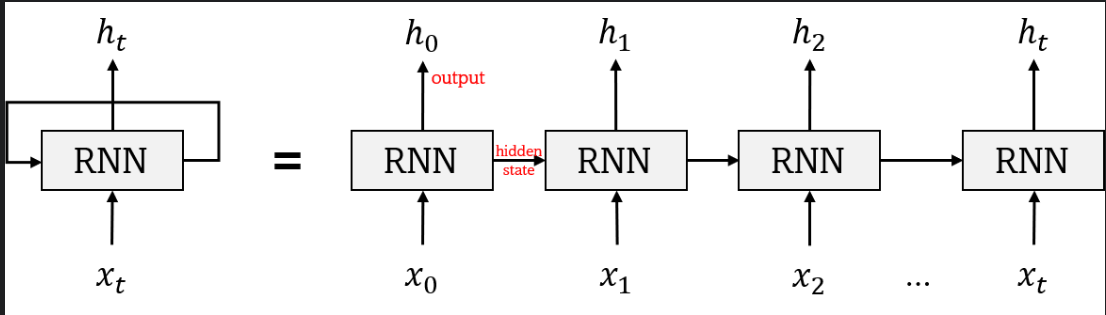
* RNN의 동작 방식은 위의 그림과 같이 입력을 받으면 은닉벡터를 생성한다.
마지막 은닉벡터는 배열 속 모든 벡터들의 내용을 압축한 벡터라고 할 수 있다.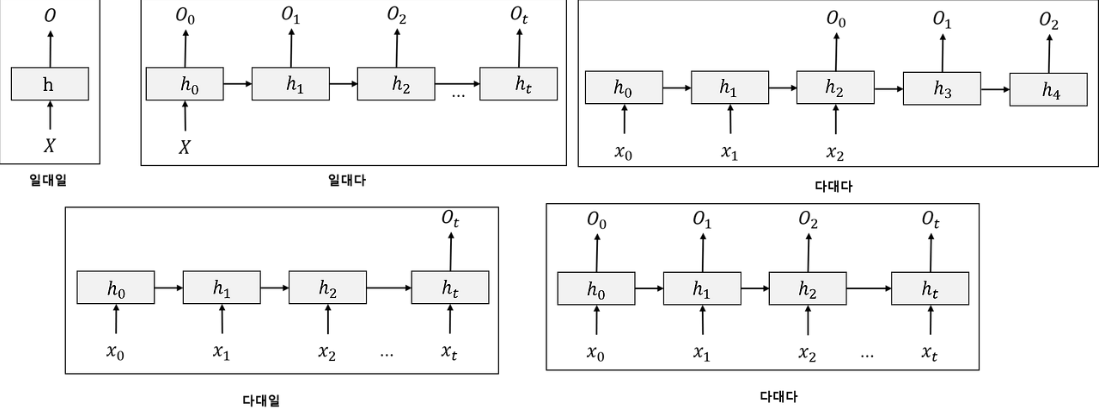
- 일대일 : 일반적인 신경망
- 일대다 : 캡셔닝(이미지 보고 이미지 내 상황을 글로 표현)
- 다대일 : 문장 감정 분석(순차적 데이터를 보고 값 하나를 출력)
- 다대다(우상단) : 챗봇, 기계 번역
- 다대다(우하단) : 비디오 분류(매 프레임 레이블링)이번에는 긍정적이면 2, 부정적이면 1로 레이블링 되어있는 영어 문장으로 이루어진 수많은 영화 리뷰들을 판단해주는 간단한 분류 모델을 만들어보았다.
code
#모델 구현과 학습에 필요한 라이브러리 임포트
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchtext import data, datasets
#필요한 하이퍼파라미터 정의
BATCH_SIZE = 64
lr = 0.001
EPOCHS = 40
USE_CUDA = torch.cuda.is_available()
DEVICE = torch.device("cuda" if USE_CUDA else "cpu")
##학습에 사용할 데이터셋 로딩 / 텐서로 변환
#필요한 설정
TEXT = data.Field(sequential = True, batch_first = True, lower = True) #sequential로 순차적 데이터셋 명시 / lower로 텍스트 전부 소문자 처리
LABEL = data.Field(sequential=False, batch_first = True) #batch_first로 신경망에 입력되는 텐서의 첫 번째 차원값이 batch_size가 되도록 정하기
#데이터셋 생성
trainset, testset = datasets.IMDB.splits(TEXT, LABEL)
#워드 임베딩에 필요한 단어사전
TEXT.build_vocab(trainset, min_freq=5) #min_freq는 학습 데이터에서 최소 5번 이상 등장한 단어만을 사전에 담기 위함
LABEL.build_vocab(trainset)
trainset, valset = trainset.split(split_ratio = 0.8)
train_iter, val_iter, test_iter, = data.BucketIterator.splits((trainset, valset, testset),batch_size = BATCH_SIZE, shuffle = True, repeat = False)
vocab_size = len(TEXT.vocab)
n_classes = 2
print("[학습셋]: %d [검증셋]: %d [테스트셋]: %d [단어수]: %d [클래스]: %d" %(len(trainset), len(valset), len(testset), vocab_size, n_classes))
class BasicGRU(nn.Module):
def __init__(self, n_layers, hidden_dim, n_vocab, embed_dim, n_classes, dropout_p=0.2):
super(BasicGRU, self).__init__()
print("building Basic GRU model...")
self.n_layers = n_layers #은닉 벡터들의 '층'인 n_layers 정의
self.embed = nn.Embedding(n_vocab, embed_dim)
self.hidden_dim = hidden_dim
self.dropout = nn.Dropout(dropout_p)
self.gru = nn.GRU(embed_dim, self.hidden_dim, num_layers = self.n_layers, batch_first = True)
#GRU는 기울기 폭발 / 소실의 문제를 가지고 있는 RNN의 결함을 보완하기 위해 사용
self.out = nn.Linear(self.hidden_dim, n_classes)
다층 형태의 RNN 모양으로써 화살표가 은닉상태를 나타내는 것이다.
입력데이터를 받아 모델을 통해 순전파 수행하여 출력
def forward(self,x):
x = self.embed(x)
#임베딩레이어를 통과시켜 벡터의 배열로 변환시켜주기
#단어 인덱스를 해당 단어의 임베딩 벡터로 매핑시키기
h_0 = self._init_state(batch_size=x.size(0)) #초기 은닉 상태 생성
x, _ = self.gru(x,h_0)
h_t = x[:,-1,:]
self.dropout(h_t)
logit = self.out(h_t)
return logitself_gru() -> 은닉 벡터들이 시계열 배열 형태로 반환
=> 결과값이 (batch_size, 입력 x길이, hidden_dim)의 3d 텐서
[:,-1:,:]로 인뎅싱 -> (batch_size, 1, hidden_dim)모양으로 텐서 추출
=> 즉 h_t가 영화 리뷰 배열들을 압축한 은닉 벡터
def _init_state(self,batch_size=1):
weight = next(self.parameters()).data
return weight.new(self.n_layers, batch_size, self.hidden_dim).zero_()parameters() -> 신경망의 가중치 정보들을 반복자 형태로 반환
=> 즉 init_state() 함수의 next(self.parameters()).data는 nn.GRU모듈의 첫 번째 가중치 텐서 추출
-> new()함수를 통해 (n_layers, batch_size, hidden_dim)모양의 텐서로 변환 후 zero()를 통해 모든 값 0으로 초기화
학습함수와 평가함수 구현
def train(model, optimizer, train_iter):
model.train()
for b,batch in enumerate(train_iter): #enumerate -> 반복마다 배치 데이터 반환
#배치내의 영화평 데이터와 레이블은 batch.text, batch.label을 통해 접근 가능
x, y = batch.text.to(DEVICE), batch.laber.to(DEVICE)
y.data.sub_(1) #y의 모든 값에서 1씩 빼기 -> 1은 0, 2는 1로
optimizer.zero_grad()
logit = model(x)
loss = F.cross_entropy(logit, y)
loss.backward()
optimizer.step()검증셋과 테스트셋의 성능 측정 함수
->데이터셋에 대한 오찻값과 정확도의 평균 반환
def evaluate(model, val_iter):
"""evaluate model"""
model.eval()
corrects, total_loss =0,0
for batch in val_iter:
x, y = batch.text.to(DEVICE), batch.label.to(DEVICE)
y.data.sub_(1)
logit = model(x)
loss = F.cross_entropy(logit, y, reduction='sum')
total_loss += loass.item()
corrects += (logit.max()[1].view(y.size()).data == y.data).sum()
size = len(val_iter.dataset)
avg_loss = total_loss / size
avg_accuracy = 100.0 * corrects / size
return avg_loss, avg_accuracy모델 객체 정의
model = BasicGRU(1,256, vocab_size, 128, n_classes, 0.5).to(DEVICE)
#은닉벡터 차원값 256, 임베딩된 토큰의 차원값 128로 임의 설정
optimizer = torch.optim.Adam(model.parameters(), lr = lr)학습 실행
best_val_loss = None
for e in range(1,EPOCHS + 1):
train(model, optimizer, train_iter)
val_loss, val_accuracy = evaluate(model,val_iter)
print("[이폭: %d] 검증 오차: %5.2f │ 검증정확도: %5.2f" %(e,val_loss, val_accuracy))검증오차가 가장 작은 모델을 저장
if not best_val_loss or val_loss <best_val_loss:
if not os.path.isdir("snapshot"):
os.makedirs("snapshot")
torch.save(model.state_dict(),
'./snapshot/txtclassification.py')
best_val_loss = val_loss테스트셋으로 모델의 성능 시험
-> 가장 성능이 좋았던 모델을 불러와 테스트
model.load_state_dict(torch.load('./snapshot/txtclassification.pt'))
test_liss, test_acc = evalutat(model, test_iter)
print('테스트 오차: %5.2f │ 테스트 정확도: %5.2f' %(test_loss, text_acc))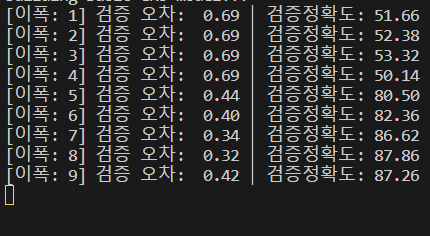
점차적으로 오차가 줄어들며 정확도가 향상되는 것을 볼 수 있다.

19011807