
Abstract
최근 시계열 예측(특히 장기 예측, LTSF) 과제에서 트랜스포머 기반 모델이 많이 등장했다. 이 논문은 기존 Transformer 모델이 정말 장기 시계열 예측에 적합한지에 대해 의문을 제기한다. 저자들은 기존 연구의 성능 향상이 Transformer의 고유한 능력 때문이 아니라, 자기회귀 방식 대신 직접 다단계(DMS) 방식을 썼기 때문이라고 주장한다. 이를 입증하기 위해 매우 단순한 선형 모델인 DLinear를 제안하여 다양한 벤치마크에서 기존의 복잡한 Transformer 기반 모델보다 오히려 우수한 성능을 확인하였다.
1. Introduction
최근 장기 시계열 예측(LTSF)에 Transformer 기반 솔루션이 크게 늘어났으며, 좋은 성과가 보고되었다. 그러나 기존의 비교 대상 모델이 주로 자기회귀 모델이라 오류 누적 문제를 가진다는 점을 지적하며, 저자들은 Transformer 모델이 정말로 시계열 예측에서 효과적인지에 의문을 제기한다. 이를 명확히 검증하기 위해 간단한 선형 구조를 가진 DLinear라는 모델을 제안하고, 다양한 현실 벤치마크에서 기존 Transformer 모델과 비교 실험을 수행한다. 실험 결과, 단순한 DLinear가 Transformer 모델을 대부분 뛰어넘었으며, Transformer의 성공은 모델 자체의 능력보다는 직접 다단계(DMS) 예측 전략 덕분이라는 점을 강조한다.
2. Preliminaries
시계열 예측(TSF)은 과거 관측 데이터로 미래의 데이터를 예측하는 과제이다. 시계열 예측 방법은 전통적인 통계 방법(ARIMA, 지수평활법 등), 머신러닝 방법(GBRT), 최근에는 딥러닝 방법(RNN, CNN 등)으로 발전해왔다. 미래 여러 단계 예측 방법에는 반복 다단계 예측(IMS)과 직접 다단계 예측(DMS)이 있다. IMS는 분산이 작지만 예측 오류가 누적되는 단점이 있으며, DMS는 긴 예측 기간에 더 적합할 수 있다.
기존 Transformer가 아닌 시계열 예측 방법들
통계적 방법(ARIMA, 지수 평활법 등)은 도메인 지식을 필요로 한다. 기계학습 방법(GBRT 등)은 데이터 기반 학습으로 편의성을 높였지만, 여전히 특징 추출 과정이 필요하다. 최근에는 RNN이나 CNN 기반 모델이 등장했고, 특히 CNN 기반 모델은 IMS와 DMS 방식을 모두 사용할 수 있다.
3. Transformer-based LTSF Solutions
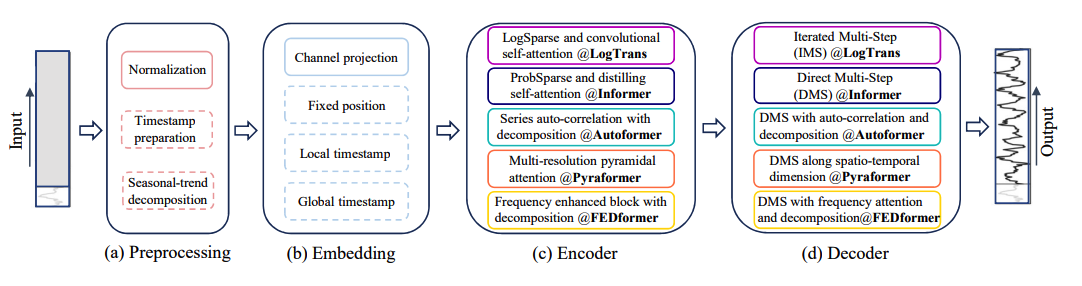
Transformer는 본래 NLP 분야에서 뛰어난 성능을 입증한 모델로서 최근 시계열 예측에도 적용되고 있다. 하지만 기본적인 Transformer는 계산 복잡도가 높고, 자기회귀 디코더 구조로 인해 장기 예측에서 오류 누적의 한계가 있다. 이에 Informer, Autoformer, Pyraformer, FEDformer 등 변형 모델들이 등장했으며, 시계열 분해 및 희소성(sparsity) 제한, 낮은 랭크의 어텐션 행렬 사용, 자기상관(auto-correlation)을 활용하여 효율성 문제를 개선하였다. 그러나 Transformer는 데이터 요소 간 의미적 관계를 찾는 데 적합한 반면, 시계열 데이터의 필수적인 '시간적 순서'를 무시하는 본질적 문제를 가지고 있다.
4. DLinear
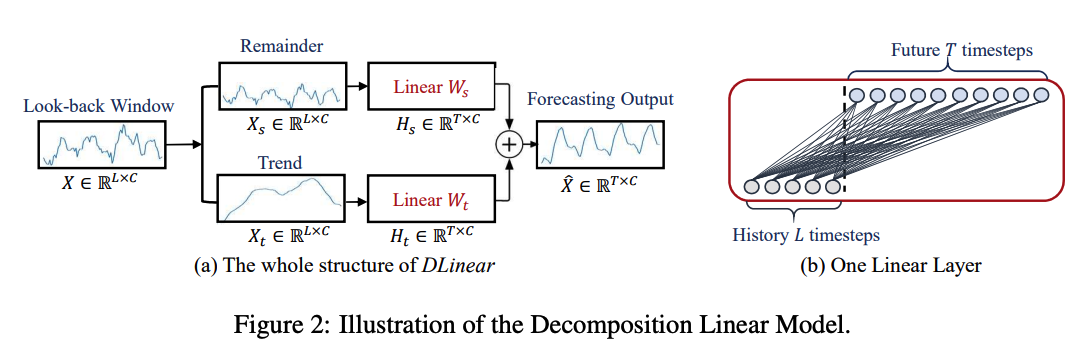
본 논문은 기존 연구의 문제를 지적하며 비교를 위해 매우 단순한 선형 모델인 DLinear를 제안한다. DLinear는 시계열 데이터를 추세(trend)와 잔여(remainder)로 나누고 각각 단 하나의 선형 계층만을 이용해 미래를 직접 예측한다. 모델은 두 가지 설계로 구성되었으며, 변수마다 별도의 가중치를 가지는 모델(DLinear-I)과, 모든 변수가 동일한 가중치를 공유하는 모델(DLinear-S)이 있다. 간단한 구조에도 불구하고 DLinear는 효율적이며, 해석이 쉽고, 다양한 데이터셋에서 기존 Transformer 모델을 능가하는 우수한 성능을 보였다.
5. Experiments
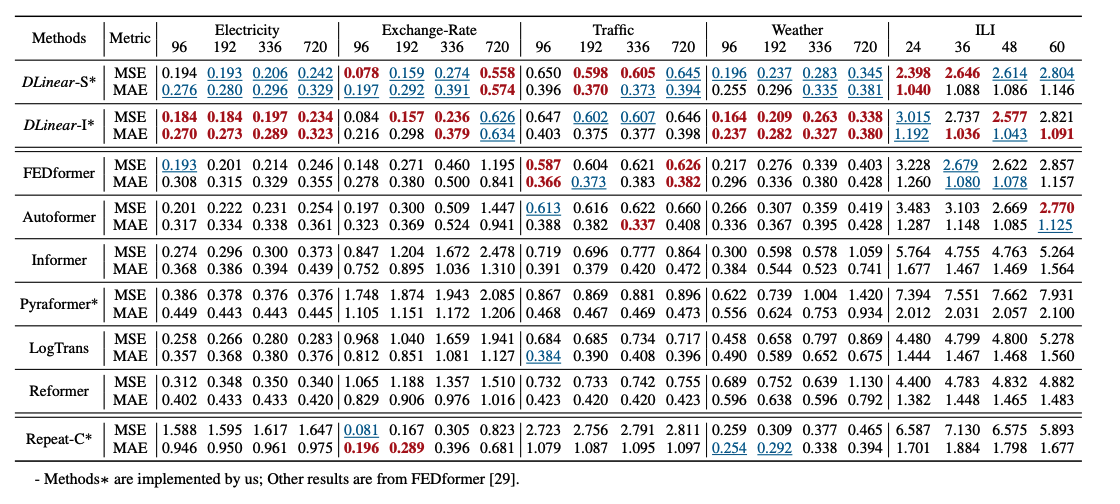
실험 환경 및 데이터셋
9가지 현실 세계의 데이터셋(ETTh1, ETTh2, ETTm1, ETTm2, Traffic, Electricity, Weather, Exchange-Rate, ILI)을 사용해 광범위한 실험을 수행했다.
성능 평가는 평균제곱오차(MSE)와 평균절대오차(MAE)를 사용했다.
Transformer와의 다변량 예측 성능 비교
다양한 데이터셋에서 DLinear는 Transformer 모델들(Informer, Autoformer, FEDformer 등)을 대부분 능가하였다.
특히 Exchange-Rate 데이터셋에서는 오차가 최대 50% 이상 감소하였다.
Transformer 모델들이 특히 비주기적 데이터에서는 올바른 추세를 예측하지 못함을 시각적으로 확인하였다.
Transformer 모델에 대한 추가 분석
과거 윈도우 크기 영향: Transformer 모델은 과거 윈도우 크기를 늘려도 성능이 좋아지지 않았지만, DLinear는 과거 데이터가 많아질수록 성능이 크게 개선되었다.
임베딩 전략 영향: Transformer는 시간 임베딩을 제거하면 성능이 급격히 악화되었으며, FEDformer만이 다소 덜 민감했다.
훈련 데이터 크기 영향: 훈련 데이터를 줄이더라도 Transformer의 성능이 오히려 향상되었으며, 이는 데이터 크기가 성능의 한계가 아님을 보여준다.
효율성 비교: Transformer 변형 모델들은 실제 효율성(추론 속도, 메모리 사용량) 측면에서 기본 Transformer 모델과 큰 차이가 없었다.
DLinear의 소거 분석
시계열 분해 기법이 명확한 추세를 갖는 데이터셋에서 DLinear의 성능을 높였다.
가중치 시각화를 통해 모델이 주기성과 계절성을 어떻게 포착하는지 명확히 드러낼 수 있었다.
6. Conclusion and Future Work
본 연구는 기존 Transformer 기반 TSF 방법이 실제로 장기 예측에 적합하지 않으며, 단순한 모델(DLinear)이 대부분의 벤치마크에서 더 뛰어난 성능을 보여주었음을 제시하였다.
앞으로의 연구에서는 무작정 Transformer 모델을 선택하기보다, 모델의 시간적 관계 학습 능력을 면밀히 점검하고, 변화점(change points) 등 더 복잡한 시계열 패턴을 효과적으로 다룰 수 있는 새로운 모델 설계의 필요성을 제안한다.
종합적 평가
본 논문은 최근 트렌드인 Transformer 모델의 유행을 비판적으로 재검토하며, 단순한 모델이 오히려 우수한 성능을 낼 수 있음을 명확한 실험으로 입증한 의미 있는 연구이다. 이를 통해 시계열 예측 모델 개발 시 모델의 복잡성을 무작정 높이는 대신, 과제에 맞는 모델 설계를 하는 것이 중요하다는 유익한 시사점을 제공한다.

잘 읽었습니다. 감사합니다!