1. 그래프(Graph)
1.1 그래프란?
- 여러 노드와 간선으로 연결된 네트워크 또는 자료구조이다.
- 그래프(Graph)는 노드(Vertex)와 간선(Edge)으로 이루어져 있다. G = (V, E)
- 차수(Degree)는 해당 노드에 연결된 간선의 수이다.
선형리스트, 트리로는 도시, 소자, 자원, 프로젝트 등의 객체들이 서로 연결되어 있는 복잡한 구조를 표현할 수 없었다. 그래서 사용되는 것이 그래프이고 컴퓨터 프로그래밍에서 유용하게 사용된다.
그래프 G는 V와 E로 표시할 수 있는데 여기서 V는 정점(vertex)이고, E는 간선(edge)이다.
- 정점 Vertex
- 여러가지 특성을 가질 수 있는 객체이다.
- V(G)란 그래프 G의 정점 집합을 의미한다.
- 노드(node)라고도 불린다.
- 간선 Edge
- 정점들 간의 관계를 의미한다.
- E(G)란 그래프 G의 간선 집합이다.
- 링크(link)라고도 불린다.
아래와 같이 그래프를 표현할 수 있다.
• V(G1)= {0, 1, 2, 3}, E(G1)= {(0, 1), (0, 2), (0, 3), (1, 2), (2, 3)}
• V(G2)= {0, 1, 2, 3}, E(G3)= {(0, 1), (0, 2))}
• V(G3)= {0, 1, 2}, E(G3)= {<0, 1>, <1, 0>, <1, 2>}
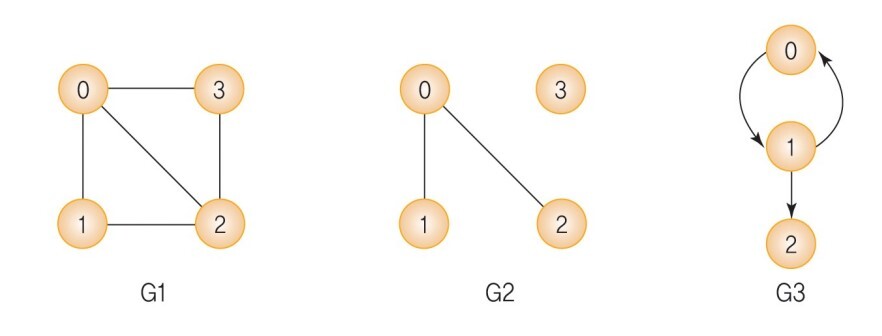
1.2 그래프의 종류
방향에 따라 그래프를 그래프를 분류하면 무방향 그래프와 방향 그래프 2가지 종류가 있다.
- 무방향 그래프는 간선을 그냥 선으로 표현하며, 양방향 그래프로 간선 하나로 둘 사이를 왔다갔다할 수 있다. 위의 그래프 G1, G2가 무방향 그래프이다.
- 방향 그래프는 방향이 있는 그래프로 화살표로 표시한다. 화살표 방향 편도로만 움직일 수 있는 특징이 있다. 위의 그래프 G3가 이에 해당된다.
1.3 그래프의 탐색
그래프 탐색은 하나의 정점에서부터 시작하여 차례대로 모든 정점들을 한 번씩 방문하는 것이다. 많은 문제들이 그래프 노드를 방문하는 것으로 해결될 수 있으며, 알고리즘 문제에서 dfs와 bfs는 가장 많이 사용되는 탐색 기법이다.
1.4 깊이 우선 탐색 DFS(Depth First Search)
한 방향으로 갈 수 있을 때까지 가다가 더 이상 갈 수 없게 되면 가장 가까운 갈림길로 돌아와 이곳에서부터 다시 깊숙히 탐색을 진행한다. 되돌아가기 위한 스택이 필요하다는 특징이 있다. 대체로 많은 사람들이 순환호출로 dfs를 구현하는데 이를 묵시적 스택이라고 한다.이는 루트-왼쪽 서브트리-오른쪽 서브트리 순으로 방문하는 트리의 전위 순회(inorder)와 비슷하다.
1.5 너비 우선 탐색 BFS(Breath First Search)
너비 우선 탐색은 시작 정점으로부터 가까운 정점을 먼저 방문하고 멀리 떨어져있는 정점을 나중에 방문하는 순회방법이다. BFS를 구현하기 위해서는 선형 자료구조인 큐가 필요하다. BFS 알고리즘은 큐에서 정점을 꺼내 방문하고 인접 정점들을 큐에 추가한다. 그리고 큐가 소진할 때까지 동일한 코드를 반복한다. 이는 트리의 레벨 순회(level order)와 비슷하다.

참조
