
✅점근적 표기법 (asymptotic notation)
점근 표기법이란 함수를 단순화하여 함수의 증가율을 다른 함수와의 비교로 표현하는 방법입니다. 중요하지 않은 상수와 계수들을 제거하면 알고리즘의 실행시간에서 중요한 성장률에 집중할 수 있는데 이것을 점금적 표기법(Asymptotic notaion)이라 부른다.
점근적이라는 의미는 가장 큰 영향을 주는 항만 계산한다는 의미이다.
6n^2+100n+3006, 이라는 기계 명령을 받는다고 가정하자.
n값이 어느 정도 커지면(이 경우는 20) 나머지 항목인 100n + 300 보다 커지게 된다.
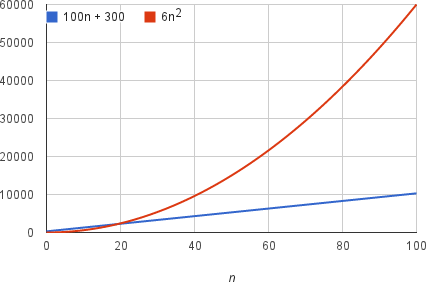
중요하지 않은 항과 상수 계수를 제거하면 이해를 방해하는 불필요한 부분이 없어져 알고리즘의 실행시간에서 중요한 부분인 성장률에 집중할 수 있다.
상수 계수와 중요하지 않은 항목을 제거한 것을 점근적 표기법(Asymtotoic notation) 이라고 한다.
1.1 점근적 분석의 필요성
어떠한 문제 해결을 위한 알고리즘의 성능분석을 할 때, 주어지는 데이터의 형태나 실험을 수행하는 환경, 또는 실험에 사용한 시스템의 성능 등 다양한 요소에 의해 공평한 결과가 나오기 힘들고 비교 결과가 항상 일정하지 않을 수 있다.
이를 효과적으로 해결하는 방법이 점근적 분석법이다.
1.2 점근적 표기법
점근적 표기법은 세가지가 있는데 시간 복잡도를 나타내는데 사용된다.
- 최상의 경우: 오메가 표기법 (Big-Ω Notation) Ω
- 평균의 경우: 세타 표기법 (Big-θ Notation) Θ
- 최악의 경우: 빅오 표기법 (Big-O Notation) O
✅Big O 표기법
알고리즘의 효율에서 가장 중요한 부분은 ‘n이 커질 때 알고리즘의 단계가 얼마만큼 증가하는가’이고, 이것을 잘 나타내는 빅 O 표기법을 사용합니다. 최악의 경우에 대한 알고리즘 수행 시간이 가장 쓸모가 많다 보니 가장 많이 사용하는 알고리즘 성능 표기법으로 빅 O 표기법이 꼽히곤 합니다.
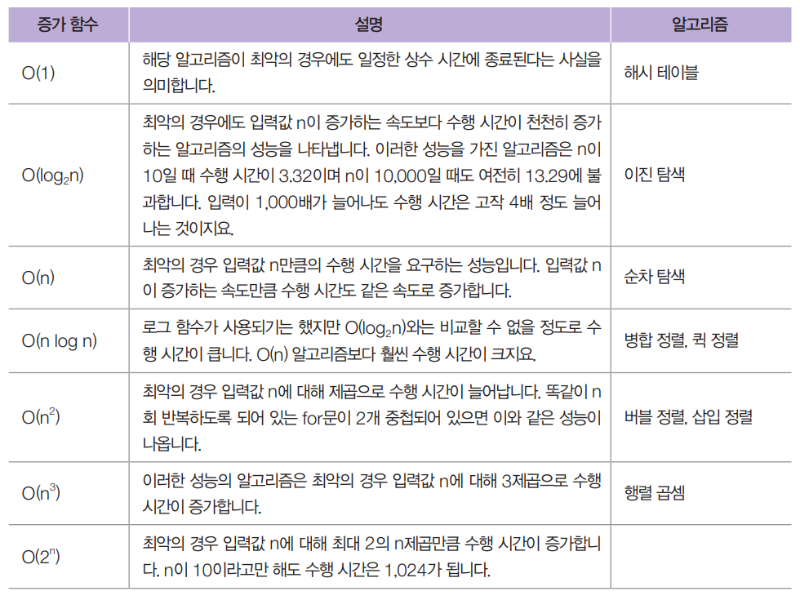
다음은 빅 O 표기법에서 가장 널리 사용되는 규모 함수들을 최선(가장 효율적)에서 최악(가장 비효율적)의 순서로 나열한 것입니다.

다음은 증가 함수와 알고리즘에 대한 표입니다.
✅오메가 표기법 (Omega Notation)
오메가 표기법은 알고리즘의 실행 시간이나 공간 복잡도를 하한으로 표현하는 데 사용됩니다.
Ω(f(n))으로 표기하며, 여기서 f(n)은 입력 크기 n에 대한 함수입니다. 예를 들어, Ω(n^2)은 적어도 이차 시간 복잡도를 나타냅니다.
✅세타 표기법 (Theta Notation)
세타 표기법은 알고리즘의 실행 시간이나 공간 복잡도를 상한과 하한으로 동시에 표현하는 데 사용됩니다.
Θ(f(n))으로 표기하며, 여기서 f(n)은 입력 크기 n에 대한 함수입니다. 예를 들어, Θ(n)은 선형 시간 복잡도를 나타냅니다.
✅상수 시간
가장 효율적인 규모는 상수 시간 복잡도(Constant Time Complexity)입니다. 어떤 알고리즘이 n의 크기에 관계없이 동일한 단계만 필요한 경우 ‘알고리즘이 상수 시간으로 실행된다’고 말합니다. 상수 시간 알고리즘을 빅 O 표기법으로 표기하면 O(1)과 같습니다.
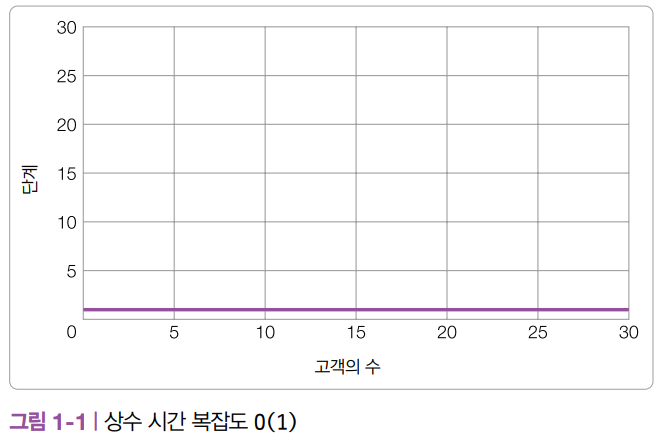 상수 시간 알고리즘은 [그림 1-1]과 같이 알고리즘이 완료될 때까지 필요한 단계가 일정합니다. 데이터 세트가 아무리 커지더라도 알고리즘의 실행 시간이 변하지 않으므로 가장 효율적인 알고리즘이라고 할 수 있습니다.
상수 시간 알고리즘은 [그림 1-1]과 같이 알고리즘이 완료될 때까지 필요한 단계가 일정합니다. 데이터 세트가 아무리 커지더라도 알고리즘의 실행 시간이 변하지 않으므로 가장 효율적인 알고리즘이라고 할 수 있습니다.
✅로그 시간
로그 시간 복잡도(Logarithmic Time Complexity)는 상수 시간에 이어 두 번째로 효율적인 시간 복잡도입니다. 데이터의 로그에 비례해 알고리즘의 단계가 늘어날 때, 알고리즘이 로그 시간으로 실행된다고 말합니다. 로그 시간 복잡도는 실행을 반복할 때마다 알고리즘의 탐색 범위를 1/2로 줄여 나가는 이진 탐색과 같은 알고리즘에서 볼 수 있습니다. 빅 O 표기법에서는 로그 시간 알고리즘을 O(log n)으로 표기합니다.
✅선형 시간
로그 시간 복잡도 다음으로 효율적인 것은 선형 시간 복잡도(Linear Time Complexity)입니다. 선형 시간으로 실행되는 알고리즘은 데이터의 크기가 커지는 만큼 같은 비율로 단계가 늘어나는 알고리즘을 말하며, 빅 O 표기법에서는 O(n)으로 표기합니다.
✅공간 복잡도
알고리즘의 효율을 생각할 때는 컴퓨터의 메모리도 유한한 자원이므로 시간 복잡도뿐만 아니라 자원을 얼마나 사용하는지도 고려해야 합니다. 공간 복잡도(Space Complexity)는 알고리즘의 실행을 완료할 때까지 필요한 자원의 양, 즉 고정 공간, 데이터 구조 공간, 임시 공간의 메모리를 얼마나 사용하는지 나타냅니다. 고정 공간(Fixed Space)은 프로그램 자체가 차지하는 메모리를 말하며, 자료구조 공간(Data Structure Space)은 데이터 세트, 예를 들어 탐색의 대상이 되는 리스트를 저장하는 데 필요한 메모리를 말합니다. 알고리즘에서 이 데이터를 저장하기 위해 사용하는 메모리는 n의 크기에 따라 달라집니다.
✅복잡도가 중요한 이유
알고리즘을 잘 선택하는 것은 실제로 큰 영향을 미칩니다. 같은 문제를 중첩되지 않은 두 개의 for 루프를 쓰는 알고리즘으로 풀 수 있다면 이 알고리즘의 시간 복잡도는 O(n)이 되고, 두 경우의 성능은 크게 차이나게 됩니다. O(n2)인 알고리즘을 조정하여 아무리 효율을 올린다고 해도 O(n)으로 고쳐 쓰는 것에는 비교할 수 없습니다. 하지만 알고리즘의 최선 또는 최악의 경우를 고려하는 것도 중요합니다. 피치 못하게 O(n2)인 알고리즘을 사용한다고 하더라도 최선의 경우에는 O(n)과 같은 결과를 낼 수 있고, 최선의 경우에 해당하는 데이터일 수 있습니다. 만약 이런 경우라면 O(n**2)인 알고리즘도 좋은 선택일 수 있습니다.
참조
