⚖️ CAP 이론과 CP vs AP 설계는 어떻게 결정하는가?
분산 시스템을 설계할 때 가장 먼저 부딪히는 벽,
바로 "Consistency vs Availability"의 트레이드오프입니다.
CAP 이론은 이를 이론적으로 설명해주는 핵심 원칙입니다.
🔰 1. 개요: CAP 이론이란?
2000년, Eric Brewer 교수에 의해 제안된 이론으로
분산 시스템에서는 세 가지 특성을 동시에 만족할 수 없다는 것이 핵심입니다.
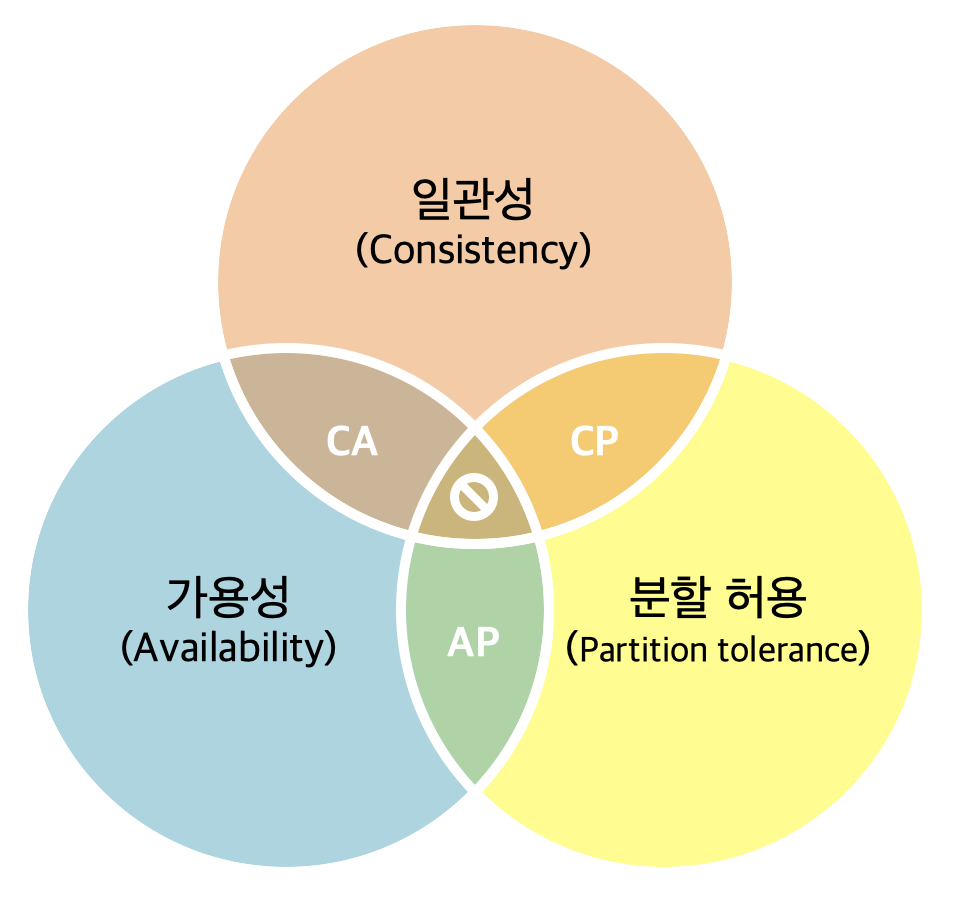
🎯 CAP 세 가지 요소
| 요소 | 설명 |
|---|---|
| C – Consistency (일관성) | 모든 노드가 같은 시간에 같은 데이터를 보여줌 |
| A – Availability (가용성) | 모든 요청에 대해 반드시 응답을 돌려줌 (에러가 아님) |
| P – Partition Tolerance (분할 허용성) | 네트워크 장애로 노드 간 통신이 끊겨도 시스템이 계속 작동 |
🧠 2. CAP의 본질
- P(Partition Tolerance)는 분산 시스템에서 항상 전제조건
- 따라서, 현실에서는 C와 A 중 하나를 선택해야 한다
[CAP 세 가지 중, 현실적으로는 둘만 선택 가능]
┌────────────┬────────────┬────────────┐
│ CP │ AP │ CA │
└────────────┴────────────┴────────────┘
↓ ↓ ↓
일관성 우선 가용성 우선 (현실적으로 불가능)⚖️ 3. 설계 유형별 특징
✅ CP (Consistency + Partition tolerance)
- 일관성 중시, 장애 시 일부 요청은 실패해도 됨
- 분산 노드 간 데이터가 항상 동기화되어 있음
- 📌 예: MongoDB(Replica Set), HBase, Zookeeper
금융, 주문 시스템처럼 데이터 정확성이 중요한 서비스에 적합
✅ AP (Availability + Partition tolerance)
- 가용성 중시, 응답은 반드시 주되 데이터는 나중에 동기화됨
- Eventually Consistent(최종 일관성) 모델
- 📌 예: Cassandra, DynamoDB, Couchbase
SNS 피드, 검색 결과처럼 빠른 응답이 중요한 서비스에 적합
❌ CA (Consistency + Availability)
- 네트워크 장애(Partition)를 허용하지 않음 → 분산 시스템에서는 불가능
- 단일 서버 또는 완전 연결된 내부망에서만 가능
- 📌 예: 단일 MySQL 인스턴스, 로컬 파일 시스템
🧩 4. 실무 설계에서 CAP은 어떻게 활용되는가?
| 상황 | 설계 선택 | 이유 |
|---|---|---|
| 금융 결제 시스템 | CP | 일관성이 매우 중요, 중복 처리 방지 |
| SNS / 피드 / 캐시 | AP | 빠른 응답 필요, 정합성은 나중에 맞춰도 됨 |
| 일반 CRUD 서비스 | 혼합 가능 | 일부는 CP, 일부는 AP로 나눠 설계 가능 |
🚧 5. CP ↔ AP 선택은 바뀔 수 있다?
✅ 예
- 초기에 CP로 설계했지만, 트래픽이 증가하면서 응답성 저하 → AP 구조로 전환
- 반대로, AP 구조에서 데이터 불일치 문제가 심각해져 CP로 전환하기도 함
즉, 설계 선택은 고정이 아니라 "비즈니스 요구"와 "운영 상황"에 따라 유동적임
✅ 6. 요약
CAP 이론은 분산 시스템에서
“무엇을 희생하고 무엇을 지킬 것인가”를 결정하게 해주는 나침반입니다.
💡 키포인트 요약
- C, A, P 중 3가지를 동시에 만족할 수는 없음
- P는 필수 → 현실적으로 CP 또는 AP 선택
- 설계는 비즈니스 특성 + 트래픽 특성에 맞춰 조정해야 함
🧱 Master, Slave, Active, Standby, Backup의 차이를 이해하자
고가용성 시스템을 설계하다 보면 다양한 용어가 등장합니다.
그중에서도 Master, Slave, Active, Standby, Backup은
서로 비슷해 보이지만 역할과 의미가 전혀 다릅니다.
🔰 1. 개요
분산 시스템 또는 고가용성 설계에서
각 노드(서버, DB, 캐시 등)의 역할을 구분하는 것이 중요합니다.
“누가 실제 서비스를 처리하고, 누가 대기 중이며, 누가 데이터를 복사만 하고 있는지”
명확히 이해해야 장애 시나리오 대응이 가능해집니다.
🧠 2. 용어별 의미와 역할
| 용어 | 의미 | 역할 |
|---|---|---|
| Master | 주 노드 | 데이터 쓰기, 주요 연산 처리, 기준 노드 |
| Slave | 보조 노드 | Master의 데이터 복제, 주로 읽기 전용 |
| Active | 현재 서비스 요청을 처리 중인 노드 | 트래픽을 직접 처리 |
| Standby | 대기 중인 노드 | Active가 죽으면 즉시 승격됨 |
| Backup | 정적인 복사본 | 데이터 유실 시 복구용 (수동 복원) |
🔄 3. 실전 예시로 구분하기
✅ Master-Slave 예시 (DB)
[Client]
↓
[Master DB] ← 쓰기 (INSERT, UPDATE)
↓
[Slave DB] ← 읽기 전용, Master로부터 복제됨- Master가 장애 나면, 수동/자동으로 Slave를 승격
- 일반적으로 읽기 부하 분산 + 장애 대응 목적
✅ Active-Standby 예시 (WAS)
[Load Balancer]
↓
[Active WAS] ← 요청 처리 중
[Standby WAS] ← 대기 중, Heartbeat 감시- Active가 죽으면 Standby가 자동 전환됨 (Failover)
- WAS, Gateway, Cache 서버 등에 자주 사용됨
✅ Backup 예시 (복구용)
Daily Backup → S3, NFS, GCS 등
장애 시 수동 복구- 실시간 운영과는 무관
- 데이터 유실을 막기 위한 마지막 방어선
⚖️ 4. 비교 정리
| 항목 | Master | Slave | Active | Standby | Backup |
|---|---|---|---|---|---|
| 동작 상태 | 주 작동 | 보조 작동 | 요청 처리 | 대기 중 | 저장만 |
| 쓰기 | ✅ | ❌ | ✅ | ❌ | ❌ |
| 읽기 | 보통 ✅ | ✅ | ✅ | ❌ | ❌ |
| 장애 대응 | 기준 노드 | 승격 가능 | 죽으면 대체됨 | 대체 역할 수행 | 수동 복구 |
| 동기화 | 기준 | Master로부터 복제 | 없음 | 실시간 상태 모니터링 | 정기적 복제 |
💥 5. 오해하기 쉬운 부분
| 오해 | 실제 |
|---|---|
| “Standby = Backup” | ❌ Standby는 실시간 대기, Backup은 정적 복사본 |
| “Slave는 항상 쓰기도 된다” | ❌ 보통은 읽기 전용 / 쓰기는 장애 시 승격 후 가능 |
| “Active는 Master랑 같다” | ❌ Active는 ‘서비스 중’ 의미, Master는 ‘데이터 기준’ 의미 |
✅ 6. 요약
고가용성에서의 역할 구분은
정확한 장애 대응과 안정적인 서비스 유지에 핵심적입니다.
💡 키포인트 요약
- Master/Slave는 데이터 복제 구조
- Active/Standby는 서비스 처리 여부
- Backup은 장애 복구를 위한 보존용
💓 하트비트와 미러링의 차이 – 감시 vs 동기화의 구분
고가용성 시스템에서 “노드 간 통신”이 중요한 이유는 두 가지입니다.
상태를 확인하기 위해, 그리고 데이터를 복제하기 위해
이 두 목적에 각각 대응하는 개념이 바로 하트비트(Heartbeat) 와 미러링(Mirroring) 입니다.
🔰 1. 개요
고가용성 구성을 하다 보면 다음과 같은 질문이 자주 나옵니다:
“서버 A와 B가 연결돼 있는데, 장애를 어떻게 감지하지?”
“데이터는 실시간으로 복사되고 있는 거야?”
→ 각각의 답이 하트비트와 미러링입니다.
💓 2. 하트비트(Heartbeat)란?
장비나 프로세스가 살아있는지 주기적으로 확인하기 위한 신호
📌 주요 특징
- 1~3초 간격의 헬스 체크 신호
- 주로 Active → Standby 전환 감지용
- 네트워크 단절 or 프로세스 중단 → 장애로 판단
✅ 예시 시스템
| 시스템 | 설명 |
|---|---|
| Keepalived | VIP를 가진 마스터 감시 (VRRP) |
| Kubernetes | Pod 상태 체크 (liveness, readiness probe) |
| Redis Sentinel | Master가 응답 없는지 판단하고 failover |
🪞 3. 미러링(Mirroring)이란?
실시간 또는 준실시간으로 데이터를 복제하여 다른 노드에 유지하는 동작
📌 주요 특징
- 주로 Master → Slave로 데이터 복사
- 장애 시 데이터 유실 최소화
- 디스크 미러링, DB 복제, 메시지 복제 등 다양하게 존재
✅ 예시 시스템
| 시스템 | 설명 |
|---|---|
| Redis Replication | Master → Replica 복제 |
| Kafka MirrorMaker | 클러스터 간 메시지 복제 |
| RAID 1 | 디스크 레벨 미러링 (동일한 복사본 유지) |
⚖️ 4. 하트비트 vs 미러링 비교
| 항목 | 하트비트 (Heartbeat) | 미러링 (Mirroring) |
|---|---|---|
| 목적 | 상태 감시 | 데이터 복제 |
| 동작 주기 | 주기적 (초 단위) | 실시간 또는 준실시간 |
| 장애 대응 | Failover 트리거 역할 | 데이터 유실 방지 |
| 구성 위치 | Active/Standby 감시 라인 | Master/Slave, 노드 간 복제 |
| 예시 | Keepalived, Sentinel | Redis Replication, RAID 1 |
🧠 5. 함께 사용하는 경우
하트비트 + 미러링 조합이 진짜 고가용성을 만든다
예: Redis Sentinel + Master-Slave 구성
- 미러링으로 데이터를 복제 → Slave가 실시간 복사본 유지
- 하트비트로 장애 감지 → Master 장애 시 Slave를 승격
이렇게 감시 + 복제가 결합돼야 고가용성이 제대로 작동합니다.
⚠️ 6. 오해 방지 포인트
| 오해 | 진실 |
|---|---|
| “하트비트는 데이터도 복제하겠지” | ❌ 하트비트는 감시만 함 |
| “미러링만 하면 고가용성 끝이지” | ❌ 장애 감지 + 전환이 없으면 failover 불가 |
| “둘이 비슷한 말 아닌가요?” | ❌ 목적과 동작이 완전히 다름 |
✅ 7. 요약
하트비트는 살아있는지 감시하고,
미러링은 살아있는 동안 복제한다
💡 키포인트 요약
- 하트비트: 장애 감지용 신호 (Failover 트리거)
- 미러링: 데이터 동기화용 메커니즘 (복제/동일화)
- 둘은 함께 써야 진짜 고가용성 시스템 구성 가능
