Hadoop MapReduce 원리
📌 왜 MapReduce인가?
2000년대 초반, 구글은 웹 페이지를 색인하기 위해 엄청난 양의 데이터를 처리해야 했다.
단일 서버는 용량·성능·내결함성 측면에서 한계가 있었고,
이를 해결하기 위해 나온 분산 처리 모델이 바로 MapReduce다.
2004년 구글이 논문을 발표했고, 이를 오픈소스로 구현한 게 Hadoop의 시작이다.
즉, 하둡 = HDFS(저장) + MapReduce(처리) 가 초기 핵심이었다.
🧩 MapReduce 개념
- Map 단계: 입력 데이터를
(key, value)쌍으로 변환 - Shuffle/Sort 단계: 같은 key끼리 묶고 정렬
- Reduce 단계: key별로 값들을 집계/가공
👉 즉, 대량 데이터를 key 기준으로 분산 집계하는 모델이다.
🔄 동작 흐름
-
입력(Input Split)
- HDFS에 저장된 데이터를 블록(128MB 단위)으로 분할
- 각 블록은 Mapper Task에 배정
-
Map
- 입력 레코드를
(key, value)형태로 변환 - 예:
"apple banana"→("apple",1), ("banana",1)
- 입력 레코드를
-
Shuffle & Sort
- 같은 key끼리 네트워크를 통해 한 Reducer로 모음
- key 기준으로 정렬
-
Reduce
- 모인 값들을 집계
- 예:
("apple",[1,1,1]) → ("apple",3)
-
출력(Output)
- 최종 결과를 다시 HDFS에 저장
📝 예시: 단어 세기 (WordCount)
입력 데이터
apple banana apple
banana apple orangeMap 출력
("apple",1), ("banana",1), ("apple",1),
("banana",1), ("apple",1), ("orange",1)Shuffle & Sort
("apple",[1,1,1])
("banana",[1,1])
("orange",[1])Reduce 결과
("apple",3)
("banana",2)
("orange",1)💻 코드 스니펫 (Java)
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable ONE = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] tokens = value.toString().split("\\s+");
for (String token : tokens) {
word.set(token);
context.write(word, ONE);
}
}
}
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}⚙️ MapReduce 특징
장점
- 장애 내성: 노드가 죽어도 다른 노드에서 재실행 가능
- 확장성: 서버(DataNode)를 추가하면 자동 확장
- 단순성: Map/Reduce 두 단계 모델
단점
- 느림: 중간 결과를 디스크에 쓰고 읽기 반복 → I/O 병목
- 실시간 처리 불가: 배치 처리 전용
- 표현력 제한: 복잡한 연산(조인, 반복 계산)에 비효율적
✅ 정리
- MapReduce는 Hadoop의 시작점이자 대용량 배치 처리의 전형적인 모델
- 구조: Map → Shuffle/Sort → Reduce
- 장점: 내결함성, 확장성
- 단점: 느림, 유연성 부족
좋은 포인트 짚었다. 👍 맵리듀스(MapReduce)를 블로그에 좀 더 입체적으로 설명하려면 “서버가 여러 대일 때 어떻게 병렬로 처리하는가”를 꼭 넣어주면 좋아.
🖥️ 분산 환경에서의 MapReduce 동작
1️⃣ 클러스터 구조
- NameNode: HDFS 메타데이터 관리 (파일 → 블록 매핑)
- JobTracker / ResourceManager(YARN): 잡(Job) 스케줄링, 어떤 서버에서 Mapper/Reducer 실행할지 결정
- TaskTracker / NodeManager: 실제 Mapper/Reducer Task 실행
2️⃣ 다중 서버에서의 처리 방식
-
입력 분할(Input Split)
- 파일이 HDFS 블록 단위(128MB)로 분산 저장됨
- 각 블록은 “가까운 서버(DataNode)”의 Mapper에서 처리 → 데이터 지역성(Data Locality)
-
Map Task 실행
- 각 서버에서 자기 하드에 있는 블록을 읽어
(key, value)생성 - 즉, 10대 서버면 동시에 10개의 Mapper가 돌 수 있음
- 각 서버에서 자기 하드에 있는 블록을 읽어
-
Shuffle & Sort
- Map 결과를 네트워크로 전송해 같은 key끼리 모음
- 예:
("apple",1)이 1000개 서버에 흩어져 있으면, Reducer 쪽으로 모아서 정렬
-
Reduce Task 실행
- 모인 key별 데이터를 집계
- Reducer 수도 조절 가능 (
setNumReduceTasks(n))
-
출력 저장
- Reduce 결과는 다시 HDFS에 저장
- 출력 파일은 보통
part-r-00000,part-r-00001형태
3️⃣ 병렬성 예시
- 데이터 1TB, 블록 크기 128MB → 약 8,000 블록
- 클러스터 100대 서버 → 동시에 최대 100개의 Map Task 병렬 실행
- 따라서 단일 서버 1TB 처리 시간이 하루라면, 분산하면 몇 시간 안에 끝남
4️⃣ 장애 내성
- Mapper/Reducer Task 중 하나가 실패하면?
→ YARN이 다른 서버에서 같은 InputSplit으로 재실행 - 서버 한 대 자체가 죽어도, HDFS 블록 복제 덕분에 다른 서버에서 동일한 데이터 처리 가능
5️⃣ MapReduce와 병렬 DB 차이
- RDBMS는 쿼리 옵티마이저가 분산 실행 계획을 세우는 방식
- MapReduce는 애플리케이션 레벨에서 Map/Reduce 로직을 작성해야 함
- 대신 훨씬 더 대규모 데이터(페타바이트급) 에 맞게 설계됨
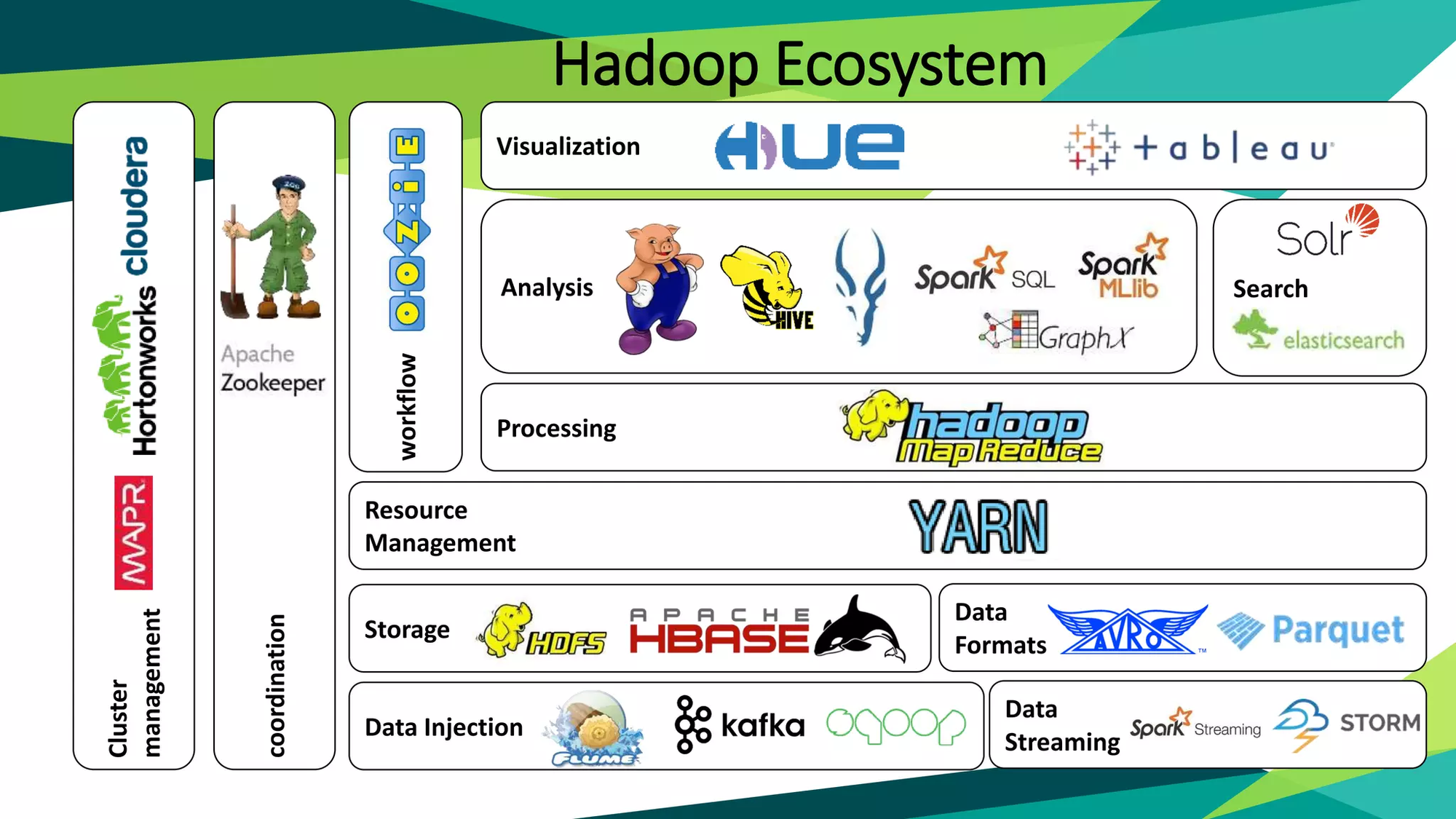
Hadoop 에코시스템 — 저장과 처리
🐘 하둡 에코시스템이 뭐길래?
Hadoop은 원래 단순했다.
- HDFS라는 분산 저장소
- MapReduce라는 배치 처리 엔진
딱 이 두 가지로 시작했다.
그런데 막상 데이터를 다루다 보니, 현실에서는 저장과 처리 말고도
- 로그를 수집해야 하고,
- 분석가들이 SQL로 데이터를 조회해야 하고,
- 운영팀은 보안·모니터링을 하고 싶어졌다.
이렇게 필요가 하나씩 늘어나면서, 하둡 옆에 각 기능을 담당하는 새로운 도구들이 붙기 시작했다.
이 전체 생태계를 통틀어 하둡 에코시스템(Hadoop Ecosystem) 이라고 부른다.
💾 저장(Storage) 계열
1) HDFS (Hadoop Distributed File System)
- “하둡의 심장”이라고 불린다.
- 파일을 128MB 단위 블록으로 쪼개 여러 서버에 분산 저장한다.
- 블록을 3개씩 복제하기 때문에 서버 한 대가 날아가도 안전하다.
👉 예시: 1GB짜리 로그 파일을 올리면, HDFS는 이를 8개의 블록으로 쪼개고, 클러스터 서버 여러 대에 나눠서 보관한다.
2) HBase
- HDFS 위에서 동작하는 NoSQL DB.
- RDB처럼 조인·SQL은 안 되지만, 키 기반으로 빠른 읽기/쓰기 가능하다.
- 👉 예시: “사용자 ID별 최근 로그인 시간” 같은 데이터를 실시간으로 읽고 싶을 때.
3) 클라우드 스토리지 (S3/GCS/ADLS)
- 요즘은 온프렘 HDFS 대신 클라우드 오브젝트 스토리지를 많이 쓴다.
- 원리는 같다. 다만 서버를 직접 운영하지 않아도 되고, 무한히 확장 가능하다.
⚙️ 처리(Processing) 계열
1) MapReduce
- 하둡 초창기 엔진.
- Map → Shuffle/Sort → Reduce 단계를 거쳐 데이터를 배치 처리한다.
- 안정적이지만 느리고, 실시간 처리는 불가능하다.
- 👉 예시: 웹 로그에서 “날짜별 페이지뷰 집계”
2) Spark
- MapReduce의 한계를 보완한 차세대 엔진.
- 데이터를 메모리에 유지하면서 처리하므로 수십 배 빠르다.
- 배치뿐 아니라 스트리밍, 머신러닝, SQL까지 지원한다.
- 👉 예시: 실시간으로 “상품별 클릭 수”를 계산해 대시보드에 반영
3) Flink
- 스트리밍에 특화된 엔진.
- Spark보다 더 낮은 지연(latency)을 목표로 한다.
- 👉 예시: 금융 거래에서 실시간 이상 거래 탐지
🎯 정리
- 하둡 에코시스템은 단순히 “하둡 = 맵리듀스”가 아니라,
저장(HDFS/HBase), 처리(MapReduce/Spark/Flink)까지 확장된 개념이다. - 오늘은 그중 저장과 처리를 봤고,
- 다음 편에서는 데이터를 수집하고, SQL로 분석하며, 운영 관리까지 하는 에코시스템 도구들을 소개한다.
Hadoop 에코시스템 — 수집, SQL, 운영
하둡 에코시스템의 저장(HDFS/HBase) 과 처리(MapReduce/Spark/Flink) 를 다뤘다.
그다음 단계, 즉 데이터를 어떻게 모으고, 어떻게 SQL로 분석하며, 운영은 어떻게 관리하는지를 살펴보자.
📥 데이터 수집(Ingestion)
데이터는 그냥 HDFS에 “짠!” 하고 생기지 않는다.
어디선가는 로그를 긁어오고, DB에서 뽑아내고, 실시간 이벤트를 흘려보내야 한다.
이를 담당하는 도구들이 바로 수집 계열이다.
1) Kafka
- 실시간 이벤트 스트리밍 파이프라인의 표준.
- Producer가 데이터를 토픽에 넣으면, Consumer가 이를 읽어간다.
- 👉 예시: 사용자가 웹에서 클릭한 로그 → Kafka 토픽 → Spark Streaming → 실시간 대시보드
2) Kafka Connect
- Kafka ↔ 외부 저장소를 자동 연동.
- Sink: Kafka → HDFS/S3/DB
- Source: DB → Kafka
- 👉 예시: MySQL 주문 테이블 변경 내역 → Kafka Connect → Kafka 토픽 → HDFS 보관
3) Debezium
- CDC(Change Data Capture) 전용.
- MySQL/Postgres의 변경 로그(binlog)를 읽어 Kafka로 흘려보낸다.
- 👉 예시: 고객 테이블에서 회원 탈퇴 발생 → Kafka 토픽 “user-events”에 자동 반영
4) Flume
- 서버 로그 수집 → HDFS에 바로 적재.
- 👉 예시: 웹 서버 access.log를 실시간으로 HDFS에 쌓기
5) Sqoop
- RDB ↔ HDFS 간 대량 데이터 이관.
- 👉 예시: Oracle DB의 주문 테이블 전체 덤프 → HDFS에 적재
📊 SQL / 분석 계열
데이터가 HDFS에만 저장돼 있으면 개발자 말고는 쓰기 어렵다.
분석가, 데이터 과학자들은 친숙한 SQL로 접근하길 원한다.
그래서 등장한 게 이 SQL 계열 도구들이다.
1) Hive
- HDFS 위에 SQL 레이어를 얹어줌.
SELECT COUNT(*) FROM logs WHERE date='2025-08-27'같은 쿼리 가능.- 내부 실행 엔진은 원래 MapReduce → 지금은 Tez, Spark도 가능.
- 👉 예시: 1TB 로그에서 “일자별 방문자 수” SQL로 바로 집계
2) Impala
- Hive와 유사하지만, 실시간 분석 쿼리에 더 최적화.
- 👉 예시: 대시보드에서 버튼 클릭 시 즉석 쿼리 실행
3) Presto / Trino
- 페이스북이 개발한 분산 SQL 엔진.
- Hive보다 훨씬 빠른 대화형 쿼리.
- HDFS뿐만 아니라 RDB, NoSQL, S3 등 다양한 소스에 동시에 접근 가능.
- 👉 예시: “S3에 저장된 로그 + MySQL 유저 테이블”을 한 번에 조인
🛠️ 운영 / 보안 / 워크플로우
데이터가 쌓이고, 분석되고 나면… 관리 지옥이 시작된다.
서버가 100대, 데이터가 수십 페타바이트면 “어디에 뭐가 있는지, 누가 접근 가능한지, 잡은 언제 실행되는지” 관리가 필요하다.
이걸 도와주는 도구들이 바로 운영 계열이다.
1) YARN
- Hadoop 클러스터 자원 관리.
- CPU/메모리 자원을 여러 잡(MapReduce, Spark, Flink)에 나눠 배정한다.
2) Oozie / Airflow
- 워크플로우(파이프라인) 관리.
- Oozie는 하둡 네이티브, Airflow는 요즘 대세.
- 👉 예시: 매일 02시에 “Kafka → HDFS → Spark 집계 → Hive 적재” 순서대로 자동 실행
3) Ambari
- 하둡 클러스터 설치, 모니터링, 운영 툴.
- GUI로 서버 상태, 잡 현황, 로그를 확인 가능.
4) Ranger / Sentry
- 보안·권한 관리.
- 👉 예시: “마케팅팀은 주문 데이터는 볼 수 있지만, 결제 금액은 볼 수 없음” 정책 설정
5) Atlas / Glue Catalog
- 메타데이터 관리.
- 👉 예시: “orders 테이블은 2025-01부터 수집 시작, 사용자 ID 필드는 암호화됨” 같은 데이터 계보 관리
🧩 전체 구조 요약 그림
[수집] Kafka / Flume / Sqoop / Debezium
↓
[저장] HDFS / HBase / S3
↓
[처리] MapReduce / Spark / Flink
↓
[SQL] Hive / Impala / Presto
↓
[자원/운영] YARN / Oozie / Airflow / Ambari / Ranger / Atlas✅ 마무리
- 하둡 에코시스템은 “맵리듀스=하둡”을 훨씬 넘어선 개념이다.
- 데이터를 수집(Kafka, Flume, Sqoop) 하고,
- 저장(HDFS, HBase, S3) 하고,
- 처리(MapReduce, Spark, Flink) 하고,
- SQL로 분석(Hive, Presto, Impala) 하고,
- 마지막으로 운영/보안(YARN, Airflow, Ambari, Ranger) 까지 커버한다.
👉 이게 바로 빅데이터 시대를 지탱하는 하둡 에코시스템의 전체 그림이다.
