🐼 지도학습
분류 : 이진분류, 다중분류 -> y, class, 분류, Type
이진분류 : 질문의 답이 예/아니오로만 양성클래스/음성클래스
다중분류 : 셋 이상의 클래스로 분류
정답지 - y, class, label, 종속변수, Target
시험지 - x, 독립변수, feature, Data회귀 : 연속적인 숫자 -> 주식, 집값, 관객수 ...
💐 실습 : Iris 품종분류
- 세개 중 하나 예측 : 다중분류
- 문제 정의 :
붓꽃의 품종을 분류 -> 3개 품종 중 하나 예측하는 다중 분류 문제로 정의- 문제집 -> 데이터, 특성(feature), 독립변수(x) : 꽃잎, 꽃받침의 길이(cm) 4가지
- 정답 -> 클래스(class), 레이블(label), 타깃(target), 종속변수(y) : 붓꽃의 품종 (setosa, versicolor, vriginica)
- sepal과 petal(그냥내가모르겠ㅇㅓ서...^^)

# 데이터 준비하기
from sklearn.datasets import load_iris
iris_dataset = load_iris()
# 데이터 확인하기
iris_dataset['target'] # 정답, label
iris_dataset['data'].shape # -> (150,4) 4개의 feature
# 그리기
import matplotlib.pyplot as plt
import pandas as pd
# 데이터프레임을 사용하여 데이터 분석 -> feature와 label의 연관성을 확인
# NumPy 배열을 pandas의 DataFrame으로 변경
iris_df = pd.DataFrame(iris_dataset['data'], columns=iris_dataset.feature_names)
# y_train에 따라 색으로 구분된 산점도 행렬을 만듦
pd.plotting.scatter_matrix(iris_df, c=iris_dataset['target'], figsize=(15,15), marker='o', hist_kwds={'bins': 20}, s = 60, alpha=.8)
plt.show()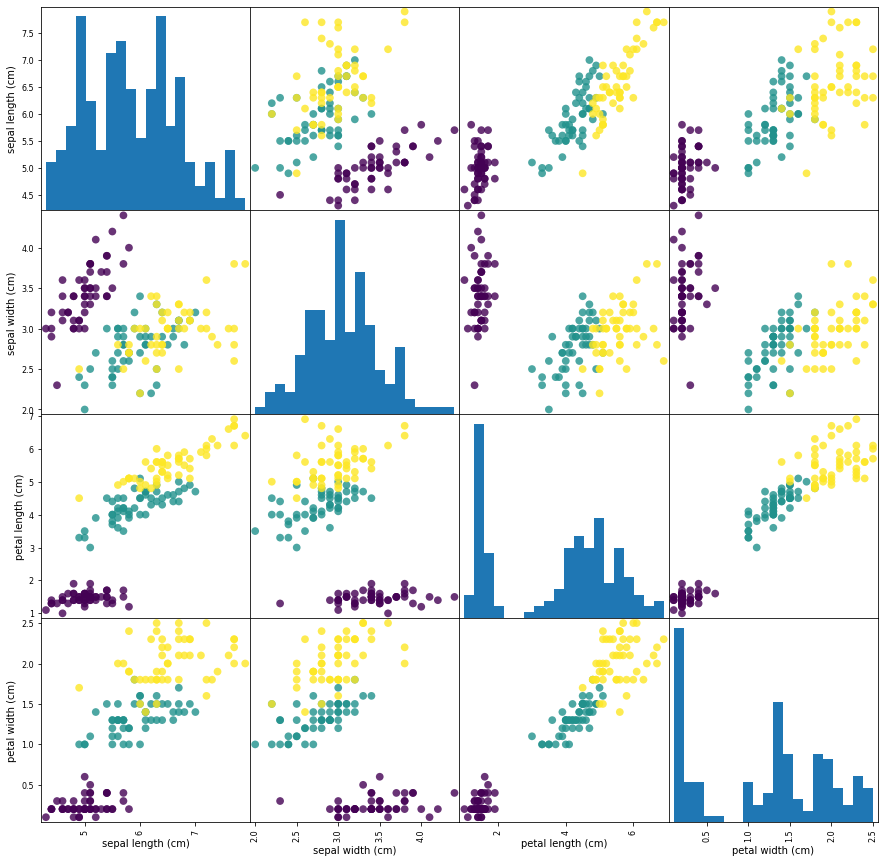
import numpy as np
plt.imshow([np.unique(iris_dataset['target'])])
_ = plt.xticks(ticks=np.unique(iris_dataset['target']), # 리턴타입을 호출하는 함수의 값을 쓰고싶지 않은데 변수를 써야할 때 '_'사용labels=iris_dataset['target_names'])
iris_df2 = iris_df[['petal length (cm)', 'petal width (cm)']]
# 각 feature들의 산점도 행렬 4 X 4
pd.plotting.scatter_matrix(iris_df2, c=iris_dataset['target'], figsize=(10,10), marker='o', hist_kwds={'bins': 20}, s = 60, alpha=.8)
plt.show()
# 훈련데이터와 테스트데이터 분리
# 훈련데이터, 테스트 데이터 -> 70:30 or 75:25 or 80:20 or 90:10
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(iris_dataset['data'], iris_dataset['target'], test_size=0.25, random_state=777)
# 훈련데이터 확인하기 150 -> 75% -> 112
X_train.shape
# 훈련데이터 확인하기 150 -> 25% -> 38
X_test.shape
# 머신러닝 모델 설정 -> k-NN
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=1) # 이웃의 개수를 1개로 지정
# 학습하기
knn.fit(X_train, y_train)
# 예측하기
y_pred = knn.predict(X_test)
# 모델평가하기
# 정확도 확인
# 1) mean() 함수를 사용해서 정확도 확인
np.mean(y_pred==y_test)
# 2) score() 함수를 사용해서 정확도 확인 -> 테스트 셋으로 예측한 후 정확도 출력
knn.score(X_test, y_test)
# 3) 평가 지표 계산
from sklearn import metrics
knn_report = metrics.classification_report(y_test, y_pred)
print(knn_report)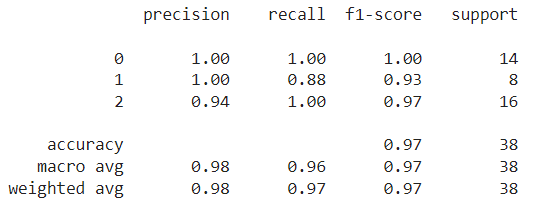
🔏 일반화, 과대적합, 과소적합
-
일반화 : 모델이 처음 보는 데이터에 대해 정확하게 예측할 수 있음
-
일반화 성능이 최대가 되는 모델이 최적
-
과대적합 : 모델이 훈련 세트의 각 샘플에 너무 가깝게 맞춰져서 새로운 데이터에 일반화 되기 어려울 때 나타남
-
과소적합 : 너무 간단한 모델이 선택됨
✒️ 모델 복잡도와 데이터셋 크기의 관계
- 우리가 찾으려는 모델 : 일반화 성능이 최적점에 있는 모델
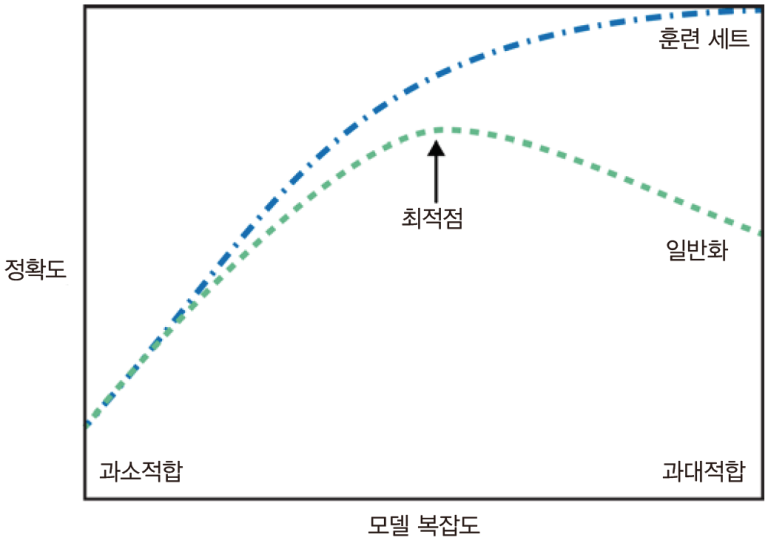
- 데이터 포인트를 더 많이 모으는 것이 다양성을 키워주므로 큰 데이터셋은 더 복잡한 모델을 만들 수 있게 해줌 -> 그러나 같은 데이터 포인트를 중복하거나 매우 비슷한 데이터를 모으는 것은 도움 X
🔏 지도학습 알고리즘
🐼 준비
# 한글 깨짐 방지 import matplotlib as mpl import matplotlib.pyplot as plt %config InlineBackend.figure_format = 'retina' !apt -qq -y install fonts-nanum import matplotlib.font_manager as fm fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf' font = fm.FontProperties(fname=fontpath, size=9) plt.rc('font', family='NanumBarunGothic') mpl.font_manager._rebuild() pip install mglearn
✒️ 이진분류 데이터셋 확인하기
import mglearn
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
# 데이터셋 다운로드
X , y = mglearn.datasets.make_forge()
# 데이터 확인하기
print('X.shape : ', X.shape) # -> (26,2)
print('y.shape : ', y.shape) # -> (26,)
plt.figure(dpi=100)
plt.rc('font', family='NanumBarunGothic')
# 산점도 그리기
mglearn.discrete_scatter(X[:,0], X[:,1], y) # 첫번째 feature, 두번째 feature 중간지점이 scatter차트로 찍힘
plt.legend(['클래스 0', '클래스 1'], loc=4)
plt.xlabel("첫번째 특성")
plt.ylabel("두번째 특성")
plt.show()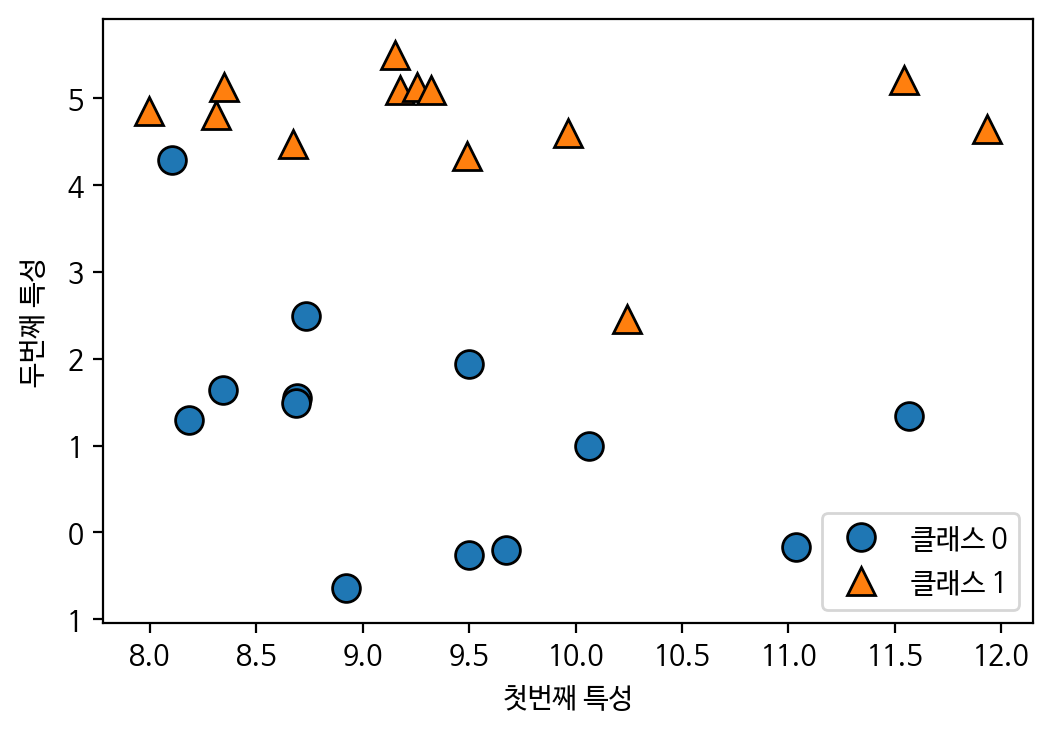 -> 두개의 특성 중 두번째 특성을 선택하는게 좋음
-> 두개의 특성 중 두번째 특성을 선택하는게 좋음
✒️ 회귀 데이터셋 확인하기
X, y = mglearn.datasets.make_wave(n_samples=40)
# 데이터 확인
print('X.shape : ', X.shape) # -> (40, 1)
print('y.shape : ', y.shape) # -> (40,)
# 산점도 X, y
plt.figure(dpi = 100)
plt.rc('font', family='NanumBarunGothic')
plt.rcParams['axes.unicode_minus'] = False
plt.plot(X, y, 'o')
plt.ylim(-3, 3)
plt.xlabel("특성")
plt.ylabel("타깃")
plt.show()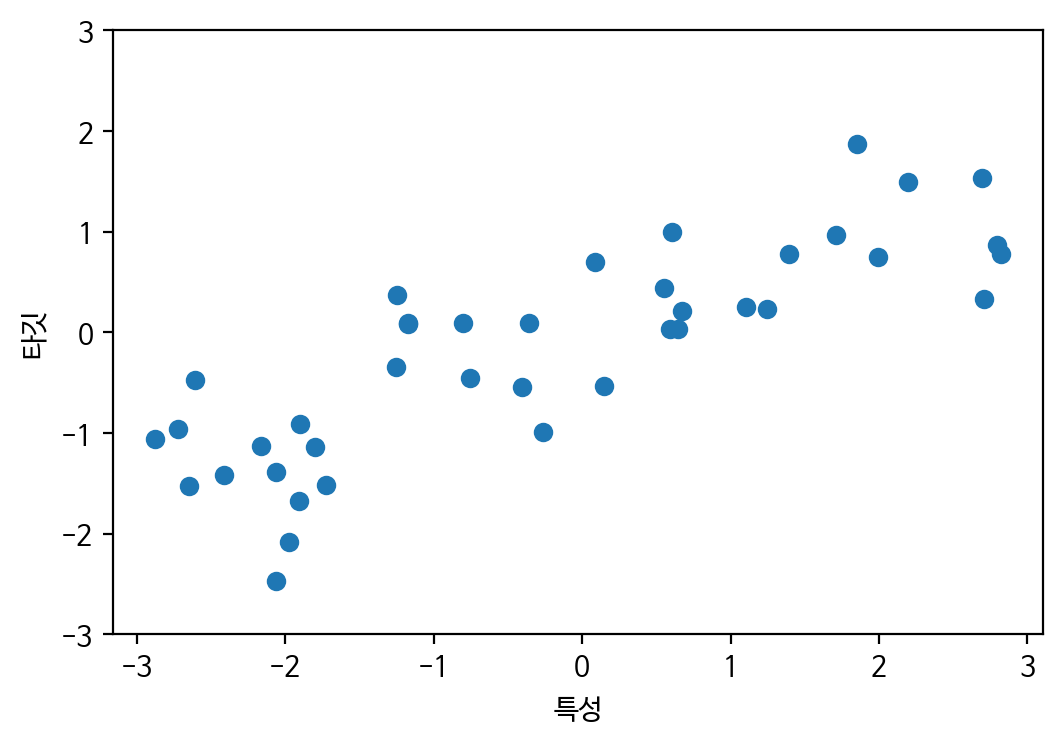 -> feature값이 커지면 y값도 커짐
-> feature값이 커지면 y값도 커짐
🔏 분류문제 정의
✒️ 위스콘신 유방암 데이터셋
https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+%28Diagnostic%29
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
# 데이터 확인하기
cancer['target'] # 0: 악성, 1: 양성
cancer['data'].shape # -> (569, 30) 569건의 데이터 수와 30개의 feature으로 이루어진 dataset
👀 이진분류 할 때 내가 찾을 데이터셋을 1로 설정하는게 유리
✒️ 1970년대 보스턴 주변의 주택 평균 가격
from sklearn.datasets import load_boston
boston = load_boston()
# 데이터 확인하기
boston.data.shape # -> (506,13)
boston_feature_names
array(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD',
'TAX', 'PTRATIO', 'B', 'LSTAT'], dtype='<U7')
'CRIM' : 지역별 범죄 발생률
'ZN' : 25000 평방피트를 초과하는 거주 지역의 비율
'INDUS' : 비상업 지역 넓이 비율
'CHAS' : 찰스강에 대한 더미 변수 (가까우면 1, 아니면 0)
'NOX' : 일산화질소 농도
'RM' : 거주할 수 있는 방의 개수
'AGE' : 1940년 이전에 건축된 소유 주택의 비율
'DIS' : 5개 주요 고용센터까지의 가중 거리
'RAD' : 고속도로 접근 용이도
'TAX' : 10000달러당 재산세율
'PTRATIO' : 지역의 교사와 학생 수 비율
'B' : 지역의 흑인 거주 비율
'LSTAT' : 하위 계층의 비율
🔏 회귀문제 정의
✒️ k-Nearest Neighbors(k-NN)
- k-NN 알고리즘은 가장 간단한 머신러닝 알고리즘
- 가장 가까운 훈련 데이터 포인트 하나를 최근접 이웃으로 찾아 예측에 사용
- KNeighborsClassifier
알고리즘이 클래스 0과 1로 나뉘는 결정 경계 확인 가능
이웃을 적게 사용하면 모델 복잡도 ↑
🔏 지도학습 알고리즘 k-NN
- 분류, 회귀모델 모두 제공
🐼 준비
pip install mglearn import matplotlib as mpl import matplotlib.pyplot as plt %config InlineBackend.figure_format = 'retina' !apt -qq -y install fonts-nanum import matplotlib.font_manager as fm fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf' font = fm.FontProperties(fname=fontpath, size=9) plt.rc('font', family='NanumBarunGothic') mpl.font_manager._rebuild()
✒️ forge데이터셋 분류
import mglearn
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
plt.figure(dpi=100)
# n_neighbors : 주변 몇개의 neighbor 탐색할건지
mglearn.plots.plot_knn_classification(n_neighbors=1)- n_neighbors = 1일때
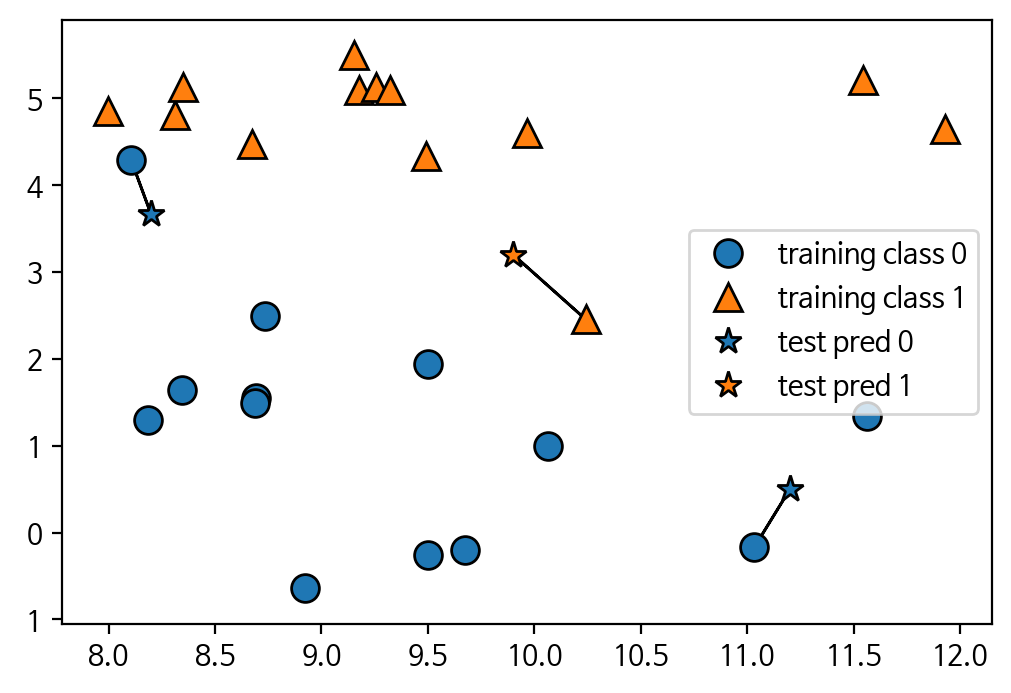
- n_neighbors = 3일때

✒️ 분류 문제 정의 forge 데이터셋을 사용한 이진분류 문제로 정의
# 데이터 준비
X , y = mglearn.datasets.make_forge() # X: 데이터(feature), y: 레이블(label, 정답)
# 데이터 분리 -> 훈련셋, 테스트셋
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=7) # 75:25(default)
# 데이터 확인
X_train.shape # 26 중 19
X_test.shape # 26 중 7🖊️ k-NN분류모델 설정
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=3)
# 모델 학습
clf.fit(X_train, y_train)
# score함수 사용하여 예측 정확도 확인
clf.score(X_train, y_train) # 정확도 0.9473684210526315
clf.score(X_test, y_test) # 정확도 0.8571428571428571 훈련 데이터셋과 차이많이나는 overfitting 상황 -> 최적의 모델이라고 볼 수 없다.KNeighborsClassifier 이웃의 수에 따른 성능평가
- 이웃의 수를 1~10까지 증가시켜 학습 진행
- score() 함수 이용하여 예측 정확도 저장
- 차트로 최적점 찾기
# 이웃의 수에 따른 정확도를 저장할 리스트 변수
train_scores = []
test_scores = []
n_neighbors_settings = range(1,15)
# 1 ~ 10까지 n_neighbors의 수를 증가시켜서 학습 후 정확도 저장
for n_neighbor in n_neighbors_settings:
# 모델 생성 및 학습
clf = KNeighborsClassifier(n_neighbors=n_neighbor)
clf.fit(X_train, y_train)
# 훈련 세트 정확도 저장
train_scores.append(clf.score(X_train, y_train))
# 테스트 세트 정확도 저장
test_scores.append(clf.score(X_test, y_test))
# 예측 정확도 비교 그래프 그리기
plt.figure(dpi=100)
plt.plot(n_neighbors_settings, train_scores, label='훈련정확도')
plt.plot(n_neighbors_settings, test_scores, label='테스트정확도')
plt.ylabel('정확도')
plt.xlabel('이웃의 수')
plt.legend()
plt.show()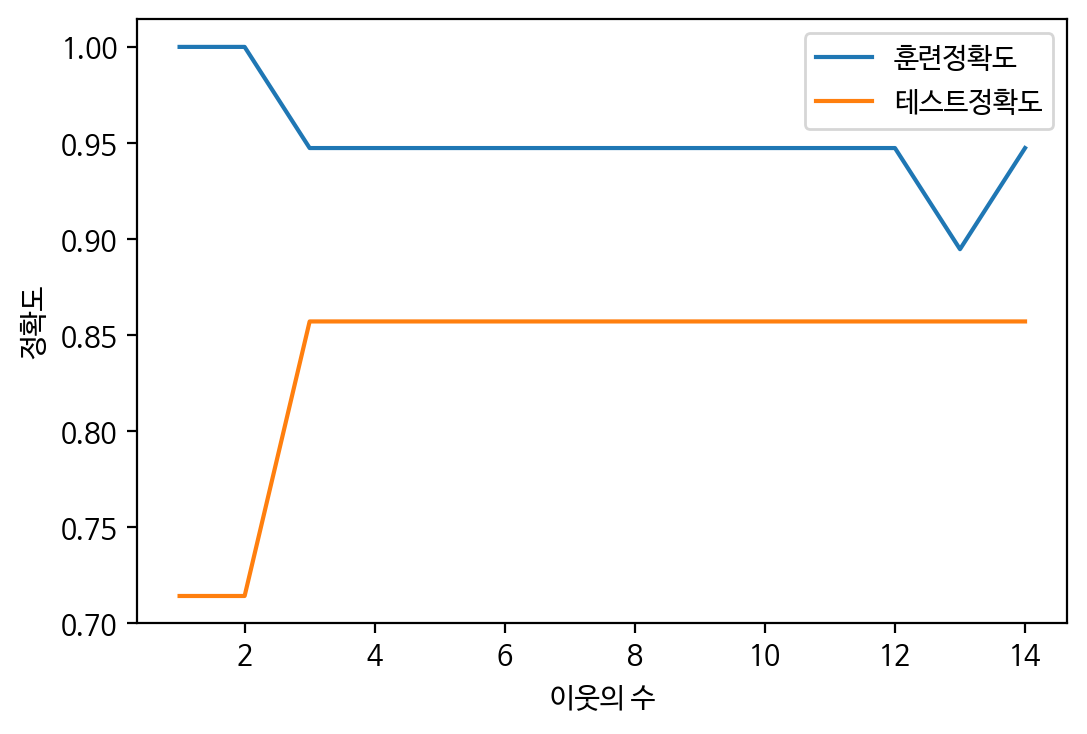
유방암 데이터셋을 사용하여 이웃의 수(결정경계)에 따른 성능평가
# 데이터준비
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
# 데이터분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, random_state=7)
# 569 -> 75% -> 426 학습
X_train.shape
# 569 -> 25% -> 143 학습
X_test.shape
# 이웃의 수에 따른 정확도를 저장할 리스트 변수
train_scores = []
test_scores = []
n_neighbors_settings = range(1,21)
# 1 ~ 10까지 n_neighbors의 수를 증가시켜서 학습 후 정확도 저장
for n_neighbor in n_neighbors_settings:
# 모델 생성 및 학습
clf = KNeighborsClassifier(n_neighbors=n_neighbor)
clf.fit(X_train, y_train)
# 훈련 세트 정확도 저장
train_scores.append(clf.score(X_train, y_train))
# 테스트 세트 정확도 저장
test_scores.append(clf.score(X_test, y_test))
# 예측 정확도 비교 그래프 그리기
plt.figure(dpi=100)
plt.plot(n_neighbors_settings, train_scores, label='훈련정확도')
plt.plot(n_neighbors_settings, test_scores, label='테스트정확도')
plt.ylabel('정확도')
plt.xlabel('이웃의 수')
plt.legend()
plt.show()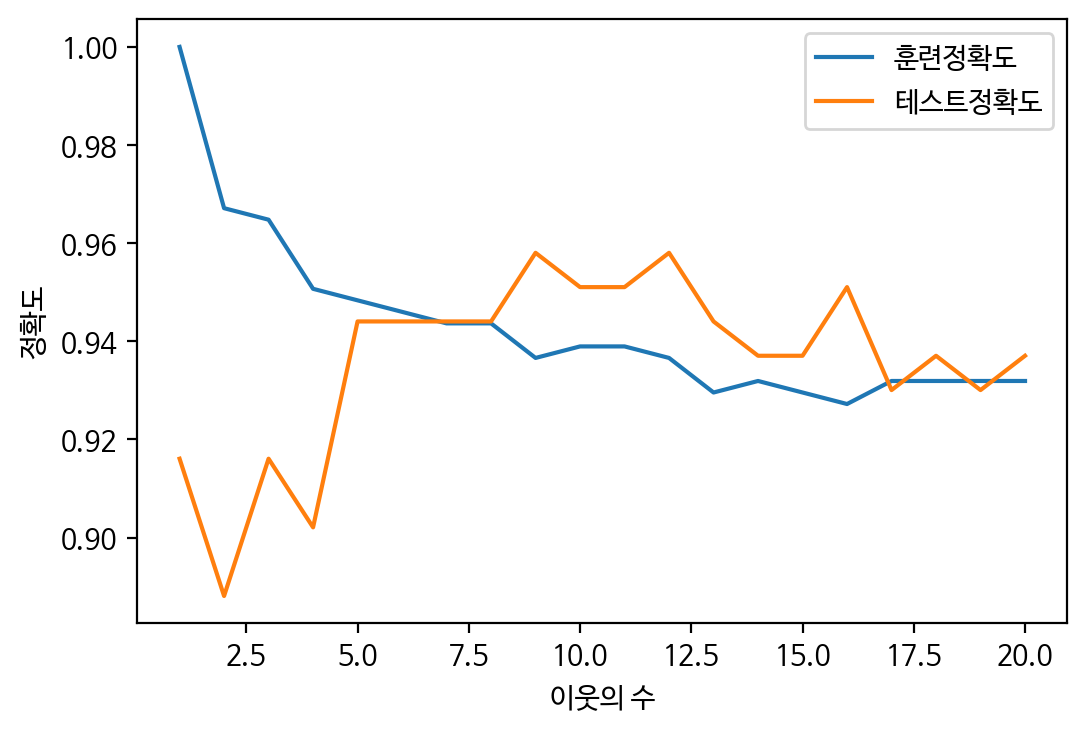

배고파용.