🐼 준비
# 한글 깨짐 방지 import matplotlib as mpl import matplotlib.pyplot as plt %config InlineBackend.figure_format = 'retina' !apt -qq -y install fonts-nanum import matplotlib.font_manager as fm fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf' font = fm.FontProperties(fname=fontpath, size=9) plt.rc('font', family='NanumBarunGothic') mpl.font_manager._rebuild()
🚣♀️ KNeighborsClassifier 타이타닉 생존자 예측
데이터 준비
import pandas as pd
import seaborn as sns
df = sns.load_dataset('titanic')
df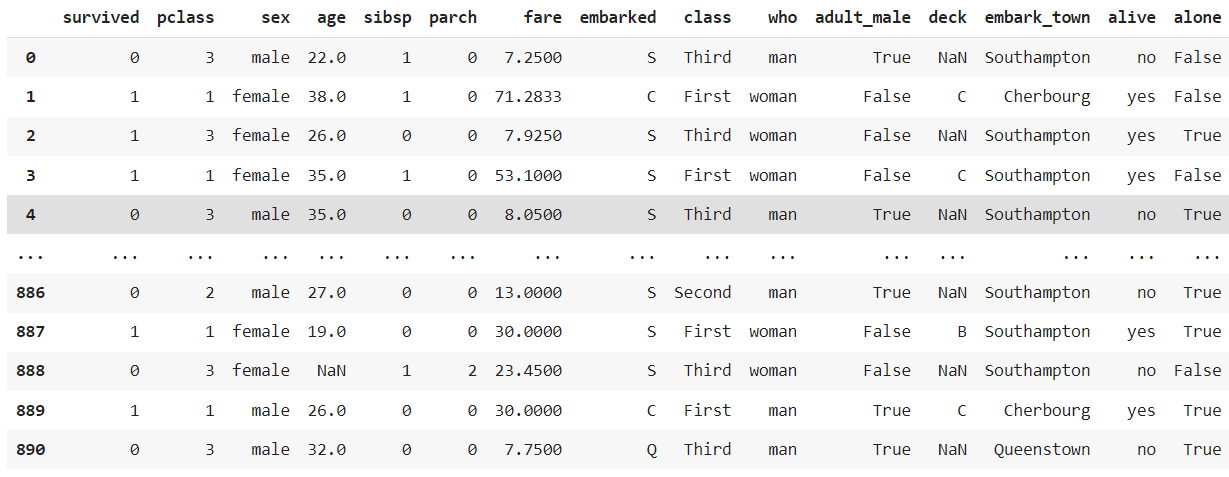
데이터 탐색
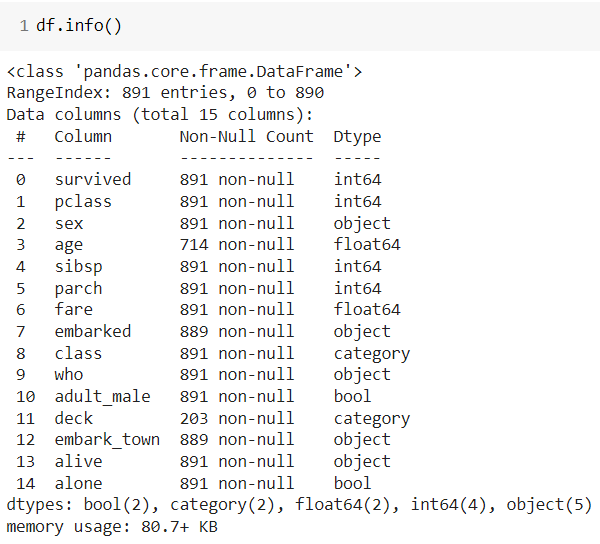
👀 NaN 값이 많은 Column이 많음을 알수 있다.
NaN 값이 많은 deck(객실 데크 위치), embark_town(승선 도시) 열(컬럼) 삭제
rdf = df.drop(['deck', 'embark_town'], axis=1)
rdf.info()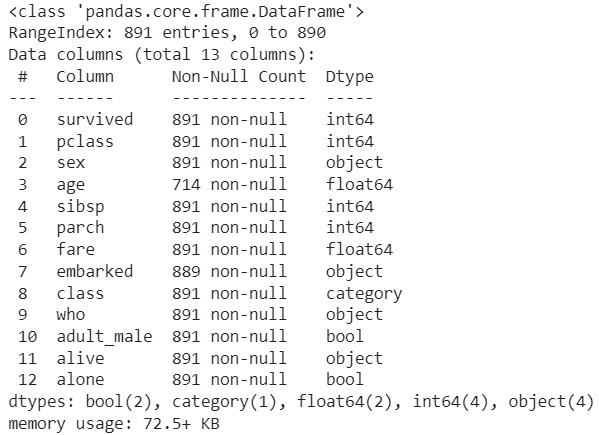
age 컬럼이 NaN인 모든 행(rows) 삭제 891->714(177건 삭제)
# 2) age 컬럼이 NaN인 모든 행(rows) 삭제 891->714(177건 삭제)
rdf = rdf.dropna(subset=['age'], how='any', axis=0)
rdf.info()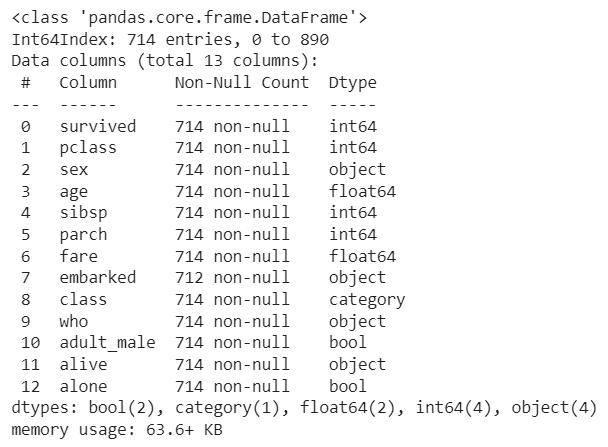
👀 모든 데이터가 714로 맞춰짐
학습에 필요한 컬럼(feature) 추출
생존여부(survived), 객실등급(pclass), 성별(sex), 나이(age), 같이 탑승한 형제/자매수(sibsp), 부모 자녀수(parch)
# 생존여부(survived), 객실등급(pclass), 성별(sex), 나이(age), 같이 탑승한 형제/자매수(sibsp), 부모 자녀수(parch)
rdf = rdf[['survived','pclass','sex','age','sibsp','parch']]
rdf.head()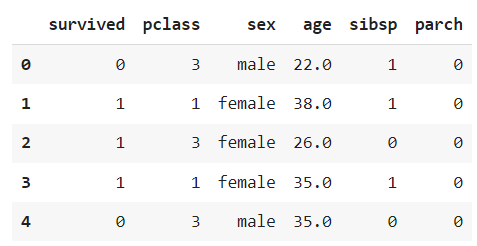
성별(sex)에 원핫인코딩
# 성별 컬럼의 값(범주형)을 모델이 인식할 수 있도록 숫자형으로 변경
# 남성 -> 0, 여성 -> 1 (1에 더 가중치가 부여될 수 있으므로 다른 형태 필요!)
# 원핫인코딩 -> male [1, 0], female [0, 1]
onehot_sex = pd.get_dummies(rdf['sex']) # 컬럼 형태로 제공
onehot_sex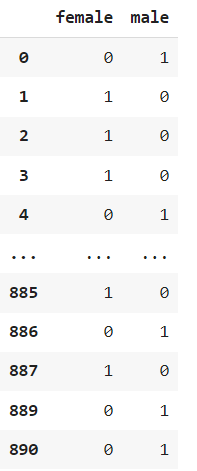
👀 원핫인코딩 결과를 원래의 데이터셋에 합치기 !
ndf = pd.concat([rdf,onehot_sex], axis=1)
ndf.head()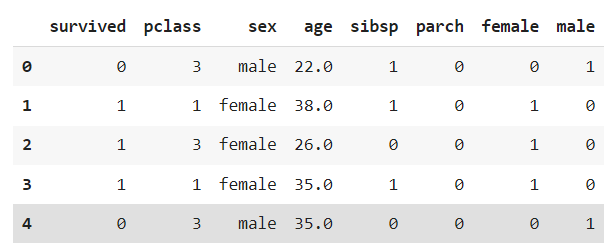
👀 이제 필요 없는 sex 컬럼 삭제
ndf.drop(['sex'], axis=1, inplace=True)
ndf.head()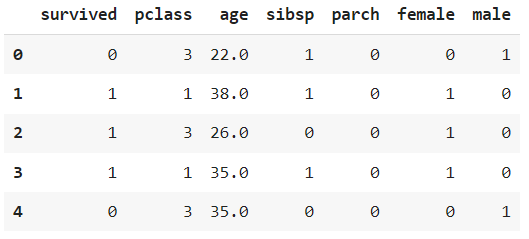
데이터셋 분리하기
# 1) ndf -> 정답지(target, label, 종속변수) y, 문제지(data, feature, 독립변수) X 데이터 분리
# survived -> y , 나머지 6개 feature -> X
X = ndf[['pclass','age','sibsp','parch','female','male']]
y = ndf['survived']
# X.shape -> (714,6)
# y.shape -> (714, )
# 2) train, test 셋으로 분리(70:30)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=7)이웃의 수(결정경계)에 따른 성능평가
from sklearn.neighbors import KNeighborsClassifier
# 이웃의 수에 따른 정확도를 저장할 리스트 변수
train_scores = []
test_scores = []
n_neighbors_settings = range(1,11)
# 1 ~ 10까지 n_neighbors의 수를 증가시켜서 학습 후 정확도 저장
for n_neighbor in n_neighbors_settings:
# 모델 생성 및 학습
clf = KNeighborsClassifier(n_neighbors=n_neighbor)
clf.fit(X_train, y_train)
# 훈련 세트 정확도 저장
train_scores.append(clf.score(X_train, y_train))
# 테스트 세트 정확도 저장
test_scores.append(clf.score(X_test, y_test))
# 예측 정확도 비교 그래프 그리기
plt.figure(dpi=100)
plt.plot(n_neighbors_settings, train_scores, label='훈련정확도')
plt.plot(n_neighbors_settings, test_scores, label='테스트정확도')
plt.ylabel('정확도')
plt.xlabel('이웃의 수')
plt.legend()
plt.show()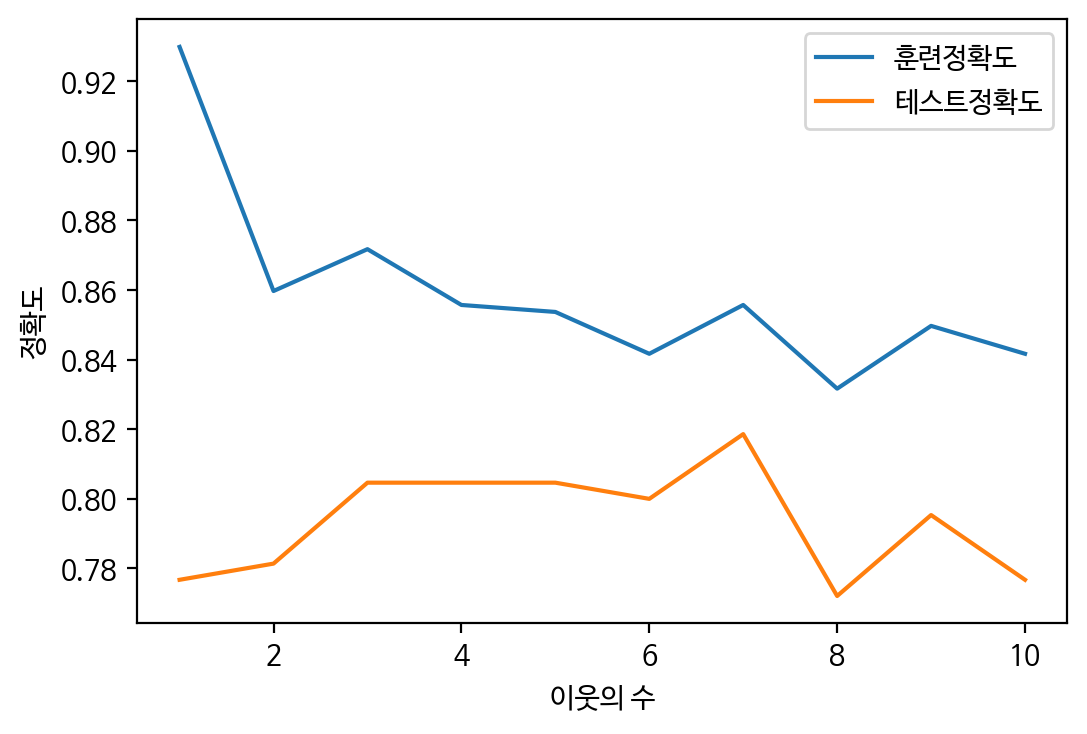
👀 스윗스팟이 7임을 알 수 있다.
모델 성능 평가
# 모델 설정 후 학습하기
clf = KNeighborsClassifier(n_neighbors=7) # 위의 그래프에서 스윗스팟 7이므로
clf.fit(X_train, y_train)
# 예측하기
y_pred = clf.predict(X_test)
# 모델 성능 지표 계산
from sklearn import metrics
# accuracy, precision, recall, f1
print('테스트 성능 평가 n_neighbors=7')
print('accuracy : ', metrics.accuracy_score(y_test, y_pred))
print('precision : ', metrics.precision_score(y_test, y_pred))
print('recall : ', metrics.recall_score(y_test, y_pred))
print('f1 : ', metrics.f1_score(y_test, y_pred))

배고파용.