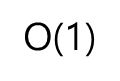
06. 주요 라이브러리의 문법과 유의점
1. 표준라이브러리
(1) 표준 라이브러리
- 특정한 프로그래밍 언어에서 자주 사용되는 표준 소스코드를 미리 구현해 놓은 라이브러리
- 코딩테스트에서는 대부분 표준 라이브러리를 사용할 수 있도록 허용하므로 표준 라이브러리를 사용하면 소스코드 작성량에 대한 부담을 줄일 수 있음
- 파이썬 표준 라이브러리는 다음 공식문서에서 자세히 확인할 수 있음
→ http://docs.python.org/ko/3/library/index.html - 파이썬에서 지원하는 표준 라이브러리는 굉장히 다양하지만 코딩테스트를 준비하며 반드시 알아야 하는 라이브러리는 6가지 정도
☑ 내장함수 : print(), input()과 같은 기본 입출력 기능부터 sorted()와 같은 정렬 기능을 포함하고 있는 기본 내장 라이브러리, 파이썬 프로그램을 작성할 때 없어서는 안되는 필수적인 기능을 포함하고 있음
☑ itertools : 파이썬에서 반복되는 형태의 데이터를 처리하는 기능을 제공하는 라이브러리, 순열과 조합 라이브러리를 제공
☑ heapq : 힙(Heap) 기능을 제공하는 라이브러리, 우선순위 큐 기능을 구현하기 위해 사용
☑ bisect : 이진 탐색 기능을 제공하는 라이브러리
☑ collections : 덱, 카운터 등의 유용한 자료구조를 포함하고 있는 라이브러리
☑ math : 필수적인 수학적 기능을 제공하는 라이브러리, 팩토리얼, 제곱근, 최대공약수, 삼각함수 관련 함수부터 파이와 같은 상수를 포함
2. 자주 사용되는 주요 라이브러리의 문법과 유의할 점
(1) 내장 함수
- 별도의 import 명령어 없이 바로 사용할 수 있는 내장함수가 존재
- 프로그램 작성에 있어 가장 기본적이면서 필수적인 기능을 포함하고 있음
- 대표적인 내장함수 : input(), print()
- sum()함수 : 리스트와 같은 iterable 객체가 입력으로 주어졌을 때 모든 원소의 합은 반환
✎ 파이썬에서 iterable 객체는 반복 가능한 객체를 말함
→ 리스트, 사전 자료형, 튜플 자료형 등이 이에 해당함 - min()함수 : 파라미터가 2개 이상 들어왔을 때 가장 작은 값을 반환
- max()함수 : 파라미터가 2개 이상 들어왔을 때 가장 큰 값을 반환
- eval()함수 : 수학 수식이 문자열 형식으로 들어오면 해당 수식을 계산한 결과를 반환
<입력>
result = eval("(3 + 5) * 7")
print(result)
<출력>
56- sorted() : iterable 객체가 들어왔을 때 정렬된 결과를 반환, key 속성으로 정렬 기준을 명시할 수 있으며, reverse 속성으로 정렬된 결과 리스트를 뒤집을지의 여부를 설정할 수 있음
- 파이썬에서는 리스트의 원소로 리스트나 튜플이 존재할 때 특정한 기준에 따라서 정렬을 수행할 수 있음, 정렬 기준은 key 속성을 이용해 명시할 수 있음
예) 원소를 튜플의 두번째 원소(수)를 기준으로 내림차순으로 정렬
<입력>
result = sorted([('홍길동', 35), ('이순신', 75), ('아무개', 50)], key = lambda x: x[1], reverse = True)
print(result)
<출력>
[('이순신', 75), ('아무개', 50), ('홍길동', 35)]- 리스트와 같은 iterable 객체는 기본적으로 sort()함수를 내장하고 있어서 굳이 sorted()함수를 사용하지 않고도 sort()함수를 사용해서 정렬할 수 있음
→ 리스트 객체의 내부 값이 정렬된 값으로 바로 변경됨
<입력>
data = [9, 1, 8, 5, 4]
data.sort()
print(data)
<출력>
[1, 4, 5, 8, 9](2) itertools
- 파이썬에서 반복되는 데이터를 처리하는 기능을 포함하고 있는 라이브러리
- 제공하는 클래스는 매우 다양하지만, 코딩 테스트에서 가장 유용하게 사용할 수 있는 클래스는 permutations, combinations임
- permutations : 리스트와 같은 iterable 객체에서 r개의 데이터를 뽑아 일렬로 나열하는 모든 경우(순열)를 계산해줌
→ 클래스이므로 객체 초기화 이후에는 리스트 자료형으로 변환하여 사용
<리스트 ['A', 'B', 'C']에서 3개(r = 3)를 뽑아 나열하는 모든 경우를 출력>
from itertools import permutations
data = ['A', 'B', 'C'] # 데이터 준비
result = list(permutations(data, 3)) # 모든 순열 구하기
print(result)
<출력>
[('A', 'B', 'C'), ('A', 'C', 'B'), ('B', 'A', 'C'), ('B', 'C', 'A'), ('C', 'A', 'B'), ('C', 'B', 'A')]combinations : 리스트와 같은 iterable 객체에서 r개의 데이터를 뽑아 순서를 고려하지 않고 나열하는 모든 경우(조합)를 계산
→ 클래스이므로 객체 초기화 이후에는 리스트 자료형으로 변환하여 사용
<리스트 ['A', 'B', 'C']에서 2개(r = 2)를 뽑아 순서에 상관없이 나열하는 모든 경우를 출력>
from itertools import combinations
data = ['A', 'B', 'C'] # 데이터 준비
result = list(combinations(data, 2)) # 2개를 뽑는 모든 조합 구하기
print(result)
<출력>
[('A', 'B'), ('A', 'C'), ('B', 'C')]- product : permutations와 같이 리스트와 같은 iterable 객체에서 r개의 데이터를 뽑아 일렬로 나열하는 모든 경우(순열)를 계산
→ 다만 원소를 중복하여 뽑음, 객체를 초기화할 때는 뽑고자 하는 데이터의 수를 repeat 속성값으로 넣어줌
→ 클래스이므로 객체 초기화 이후에는 리스트 자료형으로 변환하여 사용
<리스트 ['A', 'B', 'C']에서 중복을 포함하여 2개(r = 2)를 뽑아 나열하는 모든 경우를 출력>
from itertools import product
data = ['A', 'B', 'C'] # 데이터 준비
result = list(product(data, repeat=2)) # 2개를 뽑는 모든 순열 구하기(중복 허용)
print(result)
<출력>
[('A', 'A'), ('A', 'B'), ('A', 'C'), ('B', 'A'), ('B', 'B'), ('B', 'C'), ('C', 'A'), ('C', 'B'), ('C', 'C')]- combinations_with_replacement : combinations와 같이 리스트와 같은 iterable 객체에서 r개의 데이터를 뽑아 순서를 고려하지 않고 나열하는 모든 경우(조합)를 계산
→ 다만 원소를 중복하여 뽑음
→ 클래스이므로 객체 초기화 이후에는 리스트 자료형으로 변환하여 사용
<리스트 ['A', 'B', 'C']에서 중복을 포함하여 2개(r = 2)를 뽑아 순서에 상관없이 나열하는 모든 경우를 출력>
from itertools import combinations_with_replacement
data = ['A', 'B', 'C'] # 데이터 준비
result = list(combinations_with_replacement(data, 2)) # 2개를 뽑는 모든 조합 구하기(중복 허용)
print(result)
<출력>
[('A', 'A'), ('A', 'B'), ('A', 'C'), ('B', 'B'), ('B', 'C'), ('C', 'C')](3) heapq
- 파이썬에서 힙 기능을 위해 heapq 라이브러리를 제공
- 다익스트라 최단 경로 알고리즘을 포함해 다양한 알고리즘에서 우선순위 큐 기능을 구현하고자 할 때 사용됨
- 파이썬의 힙은 최소 힙으로 구성되어 있으므로 단순히 원소를 힙에 전부 넣었다가 빼는 것만으로도 시간복잡도 O(NlogN)에 오름차순 정렬이 완료됨
→ 보통 최소 힙 자료구조의 최상단 원소는 항상 가장 작은 원소이기 때문임 - 힙에 원소를 삽입할 때는 heapq.heappush() 메서드를 이용
- 힙에서 원소를 꺼내고자 할 때는 heapq.heappop() 메서드를 이용
<힙 정렬을 heapq로 구현>
import heapq
def heapsort(iterable):
h = []
result = []
# 모든 원소를 차례대로 힙에 삽입
for value in iterable:
heapq.heappush(h, value)
# 힙에 삽입된 모든 원소를 차례대로 꺼내어 담기
for_in range(len(h)):
result.append(heapq.heappop(h))
return result
result = heapsort([1, 3, 5, 7, 9, 2, 4, 6, 8, 0])
print(result)
<출력>
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]- 파이썬에서는 최대 힙(Max Heap)을 제공하지 않음
∴ heapq 라이브러리를 이용하여 최대 힙을 구현해야 할 때는 원소의 부호를 임시로 변경하는 방식을 사용함
→ 힙에 원소를 삽입하기 전에 잠시 부호를 반대로 바꾸었다가 힙에서 원소를 꺼낸 뒤에 다시 원소의 부호를 바꾸면 됨
<최대 힙을 구현하여 내림차순 힙 정렬 구현>
import heapq
def heapsort(iterable):
h = []
result = []
# 모든 원소를 차례대로 힙에 삽입
for value in iterable:
heapq.heappush(h, -value)
# 힙에 삽입된 모든 원소를 차례대로 꺼내어 담기
for_in range(len(h)):
result.append(-heapq.heappop(h))
return result
result = heapsort([1, 3, 5, 7, 9, 2, 4, 6, 8, 0])
print(result)
<출력>
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0](4) bisect
- 파이썬에서는 이진 탐색을 쉽게 구현할 수 있도록 bisect 라이브러리를 제공
- 정렬된 배열에서 특정한 원소를 찾아야 할 때 매우 효과적으로 사용됨
- bisect_left(), bisect_right() 함수가 가장 중요하게 사용되며, 이 두 함수는 시간복잡도 O(logN)에 동작
- bisect_left(a, x) : 정렬된 순서를 유지하면서 리스트 a에 데이터 x를 삽입할 가장 왼쪽 인덱스를 찾는 메서드
- bisect_right(a, x) : 정렬된 순서를 유지하도록 리스트 a에 데이터 x를 삽입할 가장 오른쪽 인덱스를 찾는 메서드
<정렬된 리스트 [1, 2, 4, 4, 8]이 있을 때 새롭게 데이터 4를 삽입하려 한다는 가정>
from bisect import bisect_left, bisect_right
a = [1, 2, 4, 4, 8]
x = 4
print(bisect_left(a, x))
print(bisect_right(a, x))
<출력>
2
4- bisect_left(), bisect_right() 함수는 정렬된 리스트에서 값이 특정 범위에 속하는 원소의 개수를 구하고자 할 때 효과적으로 사용될 수 있음
- count_by_range(a, left_value, right_value)함수 : 정렬된 리스트에서 값이 [left_value, right_value]에 속하는 데이터의 개수를 반환
→ 원소의 값이 x라고 할 때 left_value ≤ x ≤ right_value인 원소의 개수를 O(logN)으로 빠르게 계산할 수 있음
(5) collections
- 유용한 자료구조를 제공하는 표준 라이브러리
- collections 라이브러리의 기능 중 코딩테스트에서 유용하게 사용되는 클래스 : depue, Counter
- 보통 파이썬에서는 depue를 사용해 큐를 구현
- 별도로 제공되는 Queue 라이브러리가 있는데 일반적인 큐 자료구조를 구현하는 라이브러리는 아님
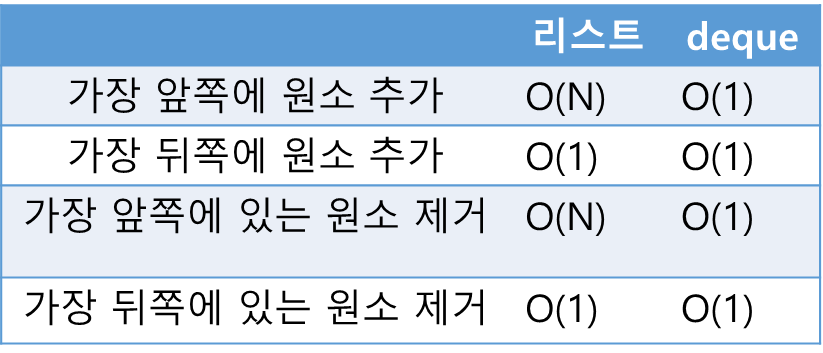
✓ 따라서 depue를 이용해 큐를 구현해야 한다는 점을 기억하자 - 기본 리스트 자료형은 데이터 삽입, 삭제 등의 다양한 기능을 제공
- 리스트가 있을 때 중간에 특정한 원소를 삽입하는 것도 가능
→ 하지만 리스트 자료형은 append() 메서드로 데이터를 추가하거나 pop() 메서드로 데이터를 삭제할 때 가장 뒤쪽 원소를 기준으로 수행됨
∴ 앞쪽에 있는 원소를 처리할 때는 리스트에 포함된 데이터의 개수에 따라서 많은 시간이 소요될 수 있음
→ 리스트에서 앞쪽에 있는 원소를 삭제하거나 앞쪽에 새 원소를 삽입할 때의 시간복잡도는 O(N)임
O(1)
- deque에서는 리스트 자료형과 다르게 인덱싱, 슬라이싱 등의 기능은 사용할 수 없음
→ 다만 연속적으로 나열된 데이터의 시작 부분이나 끝부분에 데이터를 삽입하거나 삭제할 때는 매우 효과적으로 사용될 수 있음 - 스택이나 큐의 기능을 모두 포함한다고도 볼 수 있기 때문에 스택 혹은 큐 자료구조의 대용으로 사용될 수 있음
- 첫번째 원소를 제거할 때 popleft() 사용
- 마지막 원소를 제거할 때 pop() 사용
- 첫번째 인덱스에 원소 x를 삽입할 때 appendleft(x) 사용
- 마지막 인덱스에 원소를 삽입할 때 append(x) 사용
∴ deque를 큐 자료구조로 이용할 때 원소를 삽입할 때는 append()를 사용하고, 원소를 삭제할 때는 popleft()를 사용하면 됨
→ 먼저 들어온 원소가 항상 먼저 나가게 됨
<리스트 [2, 3, 4]의 가장 앞쪽과 뒤쪽에 원소 삽입>
from collections import deque
data = deque([2, 3, 4])
data.appendleft(1)
data.append(5)
print(data)
print(list(data)) # 리스트 자료형으로 변환
<출력>
deque([1, 2, 3, 4, 5])
[1, 2, 3, 4, 5]- Counter : 등장 횟수를 세는 기능을 제공
→ 구체적으로 리스트와 같은 iterable 객체가 주어졌을 때 해당 객체 내부의 원소가 몇 번씩 등장했는지를 알려줌
<원소별 등장 횟수를 세는 기능>
from collections import Counter
counter = Counter(['red', 'blue', 'red', 'green', 'blue', 'blue'])
print(counter['blue']) # 'blue'가 등장한 횟수 출력
print(counter['green']) # 'green'이 등장한 횟수 출력
print(dict(counter)) # 사전 자료형으로 변환
<출력>
3
1
{'red':2, 'blue':3, 'green':1}(6) math
- 자주 사용되는 수학적인 기능을 포함하고 있는 라이브러리
- 팩토리얼, 제곱근, 최대공약수 등을 계산해주는 기능을 포함하고 있으므로 수학 계산을 요구하는 문제를 만났을 때 효과적으로 사용될 수 있음
- factorial(x) 함수 : x! 값을 반환
<5!를 출력>
import math
print(math.factorial(5)) # 5 팩토리얼을 출력
<출력>
120- sqrt(x) 함수 : 제곱근을 반환
<7의 제곱근을 출력>
import math
print(math.sqrt(7)) # 7의 제곱근을 출력
<출력>
2.6457513110645907- gcd(a, b) 함수 : 최대공약수를 구해야 할 때 이용할 수 있음
→ a와 b의 최대공약수를 반환
<21과 14의 최대공약수를 출력>
import math
print(math.gcd(21, 14))
<출력>
7- 수학공식에서 자주 등장하는 상수가 필요할 때에도 math 라이브러리를 사용할 수 있음
- math 라이브러리는 파이(pi)나 자연상수 e를 제공함
import math
print(math.pi) # 파이(pi) 출력
print(math.e) # 자연상수 e 출력
<출력>
3.141592653589793
2.718281828459045<reference(참조)>
나동빈(2020).<이것이 취업을 위한 코딩 테스트다 with 파이썬>.서울: 한빛미디어(주)
