
본 글은 주변 쓰레기통을 찾아주는 서비스 binder를 개발하며 발생한 이슈를 서술하였습니다.
욕설 필터링과 관련된 내용이므로 예시에 욕설이 포함될 수 있다는 점 양해 부탁드립니다.
요구사항
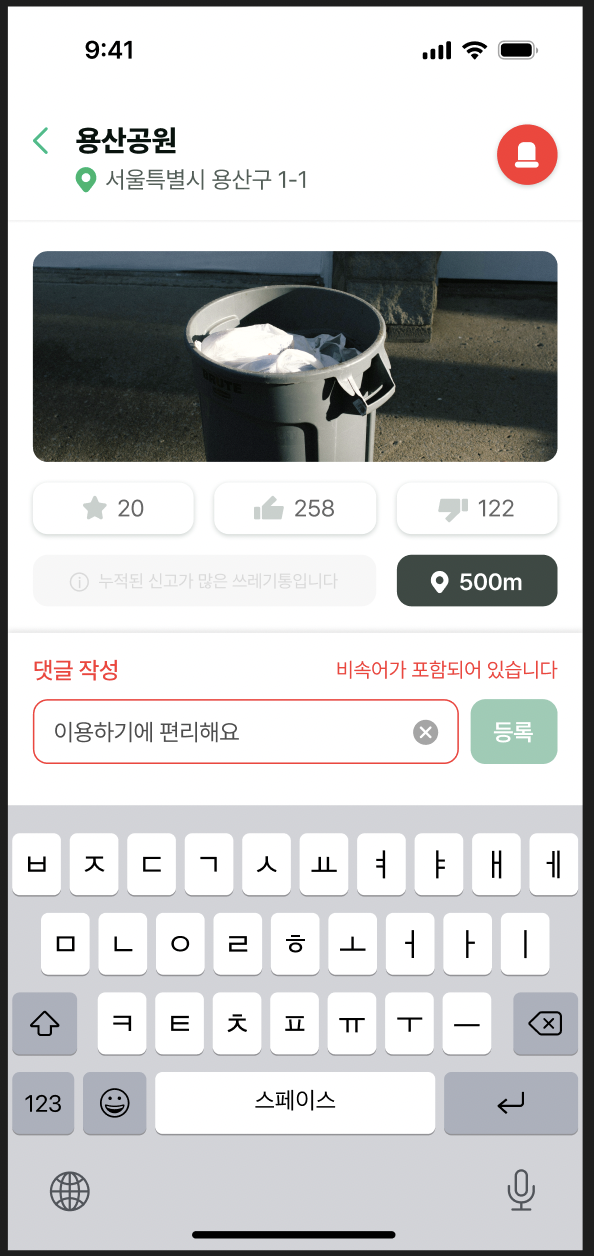
주변 쓰레기통 찾아주기(이하 Binder) 프로젝트를 진행하면서 댓글 작성 기능에 필터링을 수행하는 요구사항이 주어졌다. (디자인 이미지 상에는 욕설이 포함되어 있지는 않다.)
필터링을 도입하게 된 배경은 관리자의 부담을 덜어내기 위함이었다. 만약 관리자가 일일이 댓글에 욕설이 포함되어 있는지 확인하고 제재를 가하려면 많은 인적 자원이 소모될 것이다. 그러므로 필터링을 통해 문제가 될 수 있는 댓글의 생성을 사전에 차단하기로 하였다.
Contains 방식의 한계
만약 아래처럼 단순히 욕설이 포함 되어있는지 확인하는 것은 단순하다. 서버에서 Map, Enum, DB 등으로 욕설 데이터를 관리하다가 사용자의 댓글 작성 요청이 들어오면 Contains나 정규표현식 등으로 확인하면 되기 때문이다.
멍청이 - O하지만 단순한 방식으로 잡아낼 수 없는 경우는 어떨까? LOL, 오버워치와 같은 온라인 게임을 많이 해본 유저라면 아래와 같은 상황을 많이 접해봤을 것이다. 많은 유저들이 이와 같은 방법으로 욕설 필터링을 우회하고 있기에 Contains 방식에는 결국 한계가 있다는 것을 깨닫게 되었다.
멍1청1이 - O
멍청1이 - O OpenAI
그러다가 떠오른 것이 OpenAI API를 사용하는 것이었다. 그동안 프로젝트에서 AI를 사용해본적이 한번도 없었는데, 이번에 기회에 사용해보면 정말 좋을것 같았다.
https://platform.openai.com/settings/organization/billing/overview 에서 카드를 등록한 다음,
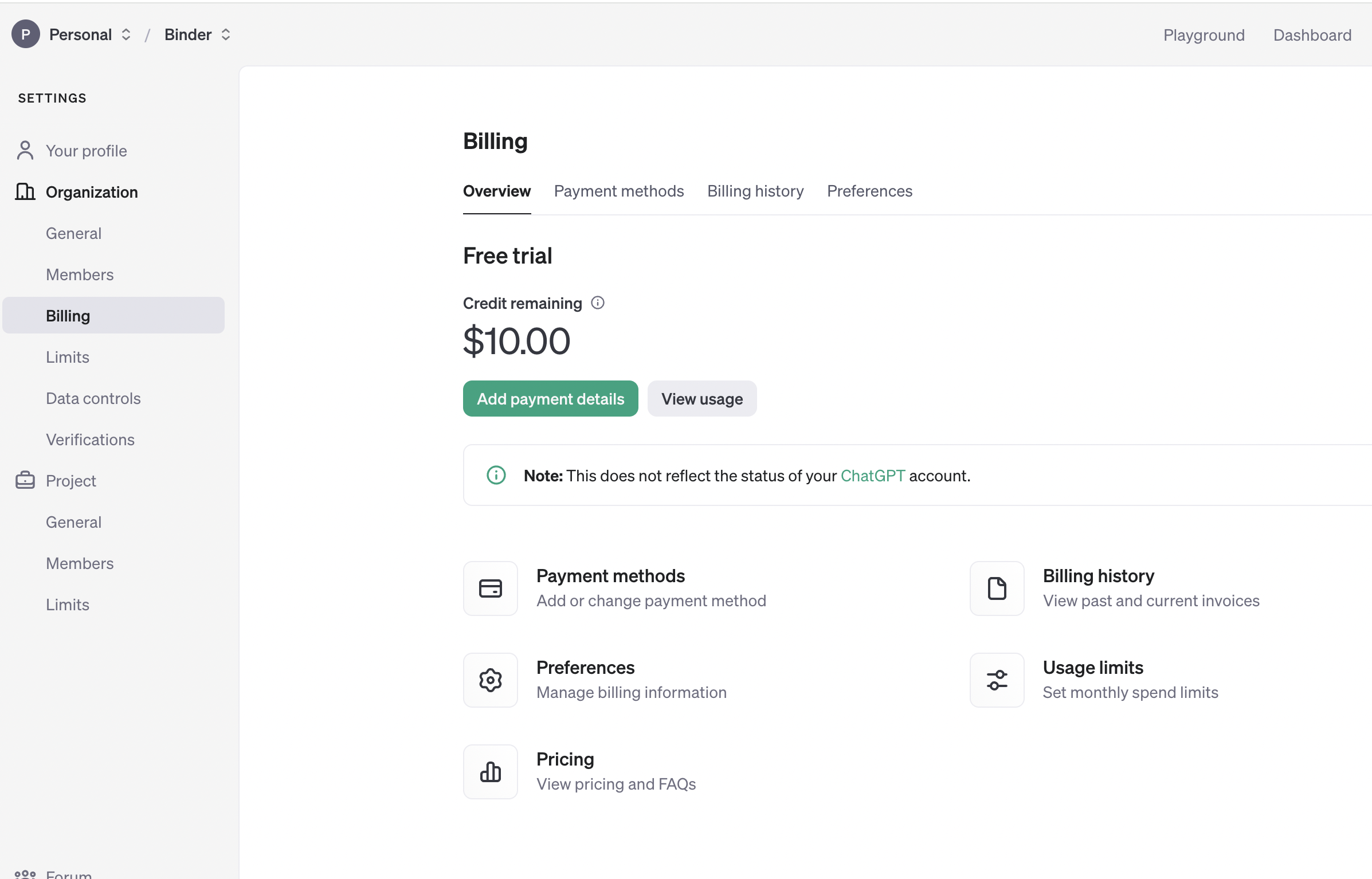
https://platform.openai.com/api-keys 에서 API 키를 발급하면 준비 완료이다.
그리고 터미널에서 테스트를 해보면 다음과 같이 결과가 나온다. isCurse는 욕설이 포함되어 있는지 여부, words는 욕으로 판단되는 단어 목록이다.
요청을 생성하는 방법은 https://platform.openai.com/docs/api-reference/chat/create 에서 확인할 수 있다.
// 요청
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer 토큰" \
-d '{
"model": "gpt-4o-mini",
"messages": [
{
"role": "user",
"content": "\"너는 진짜 개1x퀴야\" 큰따옴표 안에 비속어가 포함되어 있는지 여부(isCurse), 해당 문장 내에서 욕으로 판단한 단어목록(words) 원본(욕 사이에 1이나 다른 문자가 포함되어 있다면 그대로 포함)을 json형식으로 답해줘"
}
]
}'
// 응답
{
"id": "chatcmpl-AD8VxeZSWfryPWHNKghpIxiRVDyoE",
"object": "chat.completion",
"created": 1727694357,
"model": "gpt-4o-mini-2024-07-18",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "{\n \"isCurse\": true,\n \"words\": [\"개1x퀴\"]\n}",
"refusal": null
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 75,
"completion_tokens": 26,
"total_tokens": 101,
"completion_tokens_details": {
"reasoning_tokens": 0
}
},
"system_fingerprint": "fp_f85bea6784"
}추가로 여러가지 모델로 테스트를 해보았는데, 가장 성능이 좋은 4o 모델로 검증하는것과 비용이 가장 저렴한 4o mini 모델로 검증하는 것은 차이가 매우 컸다.
특히 4o mini의 경우에는 욕설이 포함되어 있지 않은데도 욕설로 취급하는 경우가 상당히 많았다. (자세한 가격 정보는 여기서 확인하자 https://openai.com/api/pricing/)
- 역시 돈이 좋다...

코드에 적용하기
이제 API를 코드에 적용해보자.
model(예: gpt-4o)과 target을 입력받아 적절히 파싱 후 OpenAiRequest로 만들어준다. 이때 getContent()는 GPT에게 전달될 메시지를 작성하는 로직이다. 이 내용을 잘 구성해야 GPT가 일관된 응답을 반환하므로 반드시 신경써주자!
@Getter
public class OpenAiRequest {
private final String model;
private final List<OpenAiMessage> messages;
public OpenAiRequest(String model, String target) {
this.model = model;
this.messages = new ArrayList<>();
this.messages.add(new OpenAiMessage("user", target));
}
}
@Getter
public class OpenAiMessage {
private final String role;
private final String content;
public OpenAiMessage(String role, String target) {
this.role = role;
this.content = getContent(target);
}
private String getContent(String target) {
return String.format(
"\"%s\" 큰따옴표 안에 비속어가 포함되어 있는지 여부(isCurse), 해당 문장 내에서 욕으로 판단한 단어목록(words) 원본(욕 사이에 1이나 다른 문자가 포함되어 있다면 그대로 포함)을 json형식으로 답해줘. 응답 시 백틱이나 다른 문자를 포함하지 말고, 순수한 JSON 형식으로만 응답해줘.",
target);
}
}마지막에 백틱 메시지를 넣지 말아달라고 한 이유는 종종 응답이 아래와 같이 오는 경우가 있었기 때문이다.

이제 RestTemplate을 사용해서 OpenAI API를 호출하는 로직을 작성하면 된다. 응답은 objectMapper를 통해 적절히 파싱해주자.
public CurseCheckResult checkCurse(String target) throws JsonProcessingException {
RequestEntity<OpenAiRequest> request = RequestEntity
.post(openAiUrl)
.header("Authorization", "Bearer " + openAiKey)
.body(new OpenAiRequest(openAiModel, target));
String body = restTemplate.exchange(request, String.class).getBody();
JsonNode root = objectMapper.readTree(body);
String content = root.path("choices")
.path(0)
.path("message")
.path("content")
.asText();
return objectMapper.readValue(content, CurseCheckResult.class);
}
@RequiredArgsConstructor
@Getter
public class CurseCheckResult {
private final Boolean isCurse;
private final List<String> words;
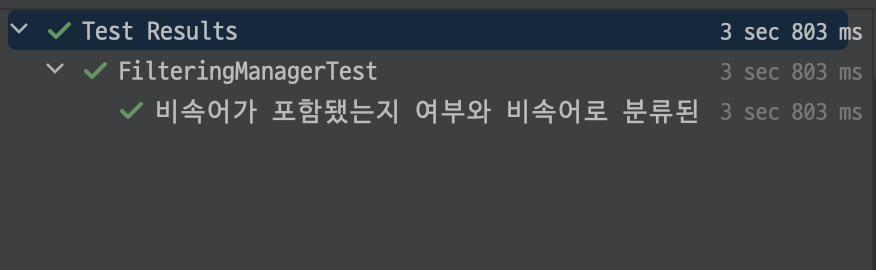
}그리고 욕설 필터링 기능에 대한 단위 테스트를 진행해보자.
(주의: 욕설이 포함되어 있습니다.)

테스트 결과는 성공이다. 1번, 2번에 대해서는 욕설로 판단하였고. 3번에 대해서는 욕설이 아닌 것으로 판단하며 기능이 예상대로 잘 동작하는 것을 확인할 수 있다.
이제 댓글 생성 로직에 해당 기능을 추가해보자. commentService는 FilteringManager의 checkCurse()를 호출하여 비속어가 있는지 검증하고, 만약 비속어가 존재한다면 예외를 발생시킨다.
//CommentService.class
public Long createComment(String email, Long binId, String content) throws JsonProcessingException {
Member member = memberService.findByEmail(email);
Bin bin = binService.findById(binId);
Comment comment = new Comment(member, bin, content); // 60자 이내인지 검사
validateIsCurse(content);
commentRepository.save(comment);
return comment.getId();
}
private void validateIsCurse(String content) throws JsonProcessingException {
CurseCheckResult curseCheckResult = filteringManager.checkCurse(content);
if (curseCheckResult.getIsCurse()) {
throw new BadRequestException("댓글 내용에 비속어가 포함되어 있습니다.");
}
}이제 통합 테스트를 진행해보자.
(주의: 욕설이 포함되어 있습니다.)
예상대로 테스트가 잘 성공한다!


해결해야할 과제
하지만 아직 해결해야할 과제들이 남아있다. 앞으로는 문제들을 차근차근 해결해보고자 한다.
- GPT가 일관된 응답을 주지 않는다.
- 본문에 욕설이 포함되어 있지 않는데 욕설이 포함되어 있다고 하는 경우
- OpenAI API에 지나치게 의존적이다.
- API를 호출해야지만 욕설이 포함되었는지 알 수 있다.
- 사용량에 따라 응답시간이 느려질 수 있다.
- 사용량에 따라 비용 문제가 발생할 수 있다.
- OpenAI에 장애가 발생하면 애플리케이션에도 장애가 발생한다.
- 욕설이 아닌 댓글이 더 많을 가능성이 높음에도 항상 욕설 필터링을 해야한다.
참고 문서
https://duklook.tistory.com/467
