
SQL - 1970년대 IBM이 Sequel 이란것을 만들었고 이후 SQL이 되었다.
1980년대 SQL표준을 제정하였고 현재까지의 DB들은 이 표준을 일부 따른다.
DDL(data-definition-Language)
- 스키마를 정의/수정/삭제 할때 사용
- 각 Relation의 스키마
- 각 Attribute의 도메인
- 데이터 제약 조건
- not null- primary key
- foreign key
- 보안/ 권한 정보
- 인덱스 집합
- drop, delete, alter
DML(data-manipulation-language)

쿼리 구조
Select
- select를 통한 사칙연산을 통한 결과확인도 가능
Where절
- and, or, not 같은 논리 : 조건식을 생각
- ex) where num=10
From절
- 대상 Relation을 명시, 데이터를 불러올 테이블을 대상
- ex) select id from teaches
DML 연산 종류
Join절
- 두개 이상의 Relation을 함께 사용하여 데이터를 얻기
- from a join b;
- 추가로 natural join 은 겹치는 속성을 합쳐줌
- 하지만 이때 합쳐줄때에는 이름을 기준으로 합쳐주기에 이름은 같지만 의미가 다를때에는 주의해서 사용해야한다.
like
-
문자열 비교를 위한 연산자
-
정확한 단어를 모르거나 특정 단어를 포함하는 단어를 찾을때
-
대소문자 구분
-
%, _ 기호 사용
- % 는 임의의 문자열을 의미, _ 는 한글자를 의미
- ex) where name like '%박세건' -> 박박박세건 찾아짐, 박박세건 찾아짐
- ex) where name like '_박세건' -> 박박박세건 못찾음, 박박세건 찾음
집계 함수 (Aggregate Functions)
- 계산 결과가 릴레이션으로 나온는 것이 아닌 값으로 나오는 것을 이야기 합니다.
- avg,min, max 등
- where 절에서 사용하는 것이 아닌 select나 having 절에서 사용됩니다.
- count는 튜플의 개수를 세는 기능 : distinct와 사용되는 것을 금지한다.
Group By
- 이름 그대로 속성별로 그룹을 만들어 줍니다.
- 주로 집계함수를 사용합니다.
- 예를들어서 반별로 점수의 평균을 확인하고 싶다면 : select class, avg(score) from student group by class;
- group by에 명시된 attribute만이 select 절에서 Aggregate Function 없이 명시될 수 있다
- 예를 들어, 과목을 그룹으로 성적의 평균을 구하려고할때 select절에 학번의 속성이 들어있다면 그룹의 성적의 평균을 나타낼때의 학번은 표시할 수 가 없게되기때문에 사용할 수 없다.
Having
- Group By로 만들어진 그룹에 대한 조건을 명시합니다.
- ex) ~~group by class having avg(score)> 80;
기타
중복된 튜플이 Relation에 존재하는 것을 Duplicate라 하고 이를 허용하는 집합을 Multiset이라 한다
NULL이 포함되는 산술연산의 결과는 항상 NULL이다, select 가능
산술 연산 결과는 항상 NULL, 비교 연산 결과는 Unknown 이지만 경우에 따라 true, false 가능
Rename절 (as)
- SQL 쿼리 작성이나 출력 결과의 relationi/attribute의 이름을 정할 수 있음
- ex) select saraly/12 as monthly_salary from instuctor
- as 는 생략 가능
SubQuery
- 하나의 쿼리 안에 또 다른 쿼리가 있는 것을 말합니다, where절 혹은 from 절에 설정할 수 있다.
Set Membership(in, not in)
- subquery의 결과 relation에 해당 튜플이 속하는지를 확인
- not in 과 in 이 활용됩니다.
- ex) select name from student where name in ('박세건');
- 위처럼 열거형으로 조건을 설정할 수 도 있습니다.
- ex) select id from student where class=5 and id not in(select id from student where score>80);
Set Comparison(some, all)
-
subquery의 결과 relation과 바깥 query를 비교하는 것입니다.
-
some뒤에 오는 subquery의 결과중 하나라도 만족하는 것이 있다면 참을 반환합니다.
- ex) ~~where score < some (subquery) 가 있고
some뒤에 오는 결과 relation의 모든 점수가 1,2,3,4,5,6 이라면 점수가 5이하인 결과는 찾아올 수 있지만 6인 결과를 찾아오지 못한다. -> 6 은 some뒤에있는 어떠한 결과보다 작지 않기때문입니다.
- ex) ~~where score < some (subquery) 가 있고
-
all 뒤에 오는 subquery의 모든 결과를 만족해야 참을 반환합니다.
- ex) ~~where score < all (subquery) 가 있고
all뒤에 오는 결과 relation의 모든 점수가 1,2,3,4,5,6 이라면 점수가 0이하인 결과만 찾아올 수 있습니다.
값이 비어있는지에 대한 확인은 exists와 not exists를 통해 확인할 수 있다.
unique 절을 통해서 결과의 relation에 중복이 존재하는지 확인할 수 있다.
- 결과 튜플이 딱 한개있을때 true return;
- 주의할점은 아예 결과 튜플이 존재하지 않아도 true를 리턴한다는 점입니다.
From절 subquery
- ex) ~~where score < all (subquery) 가 있고
-
from절 또한 relation을 이용하기때문에 subquery를 이용할 수 있습니다.
ex) ~~from(select avg(score) as avg_score from student group by student_number);임시 relation (with - as)
-
query에서 사용할 수 있는 임시 뷰를 정의해 줍니다.
-
많은 조건을 거쳐서 추출한 relation이 여러개 있다면 이 많은 relation에 대해서 탐색을 하여 원하는 결과를 얻는 것은 매우 복잡하고 귀찮은 일이 될 것입니다.
-
이를 좀 더 다루기 쉽게 하기위해서 사용합니다.
-
sql) with (임시 relation 이름) ((임시 relation의 속성들)) as ((relation을 추출할 subquery))
사용할 때에는 ~from (임시 relation 이름) where~ 사용합니다.Scalar Subquery는 하나의 값이 필요한 곳에 사용되는 것으로, 결과 relation이 하나의 Attribute에 하나의 튜플만을 가집니다
-
select절에서 subquery : 스칼라subquery
-
from절에서 subquery : 인라인(inline)subquery
-
where 절에서 subquery : 중첩 subquery
Set Operation(집합 연산자)
- UNION(합집합)
- UNION ALL(중복 포함 합집합)
- INTERSECT(교집합)
- EXCEPT(차집합)
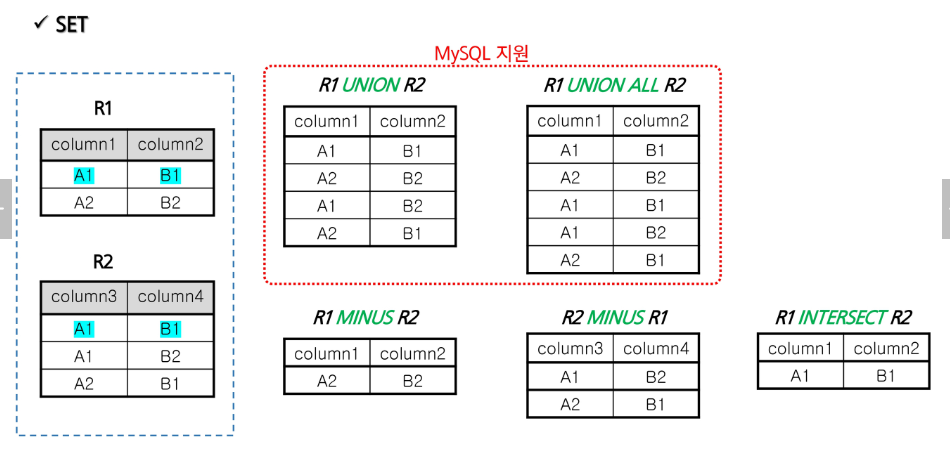
Set Operation(집합 연산자) vs Join
Join
- 적어도 하나의 속성이 공통인 두 테이블을 결합할때 사용합니다.
- join한 테이블을 옆으로 붙여서 반환합니다.
- 새로운 열로 결합합니다(수평결합)
Set Operation(집합 연산자)
- 각 컬럼의 수가 같아야 하고, 각 컬럼의 타입이 같아야합니다.
- 하나의 결과 세트로 나타납니다.
- 새로운 행으로 결합합니다(수직결합)
데이터베이스 수정
삭제
- delete from r where P;
- P의 조건에 해당하는 모든 튜플 삭제
- 튜플단위로 삭제 가능
삽입
- insert into 절
- insert into (relation 이름) ((속성1, 속성2, ...)) values ((값1,값2, ...));
- 삽입할 튜플을 생성하는 query를 작성하는 방법도 있습니다.
- insert into (relation 이름) (select 절)
- 삽입절에 중복확인이 필요하기때문에 PK가 반드시 존재해야합니다. 그렇지 않으면 무한루프가 발생하게됩니다.
갱신
- update-set-where 절로 수행
- where로 대상 튜플을 선택하고 set으로 갱신할 값을 지정합니다.
