
인덱스
인덱스란, 저장공간을 활용해서 DB의 검색 속도를 향샹시키기 위한 자료구조 입니다.
DB의 테이블을 모두 탐색해서 데이터를 검색하는 시간은 오래걸릴 수 있기때문에, 데이터와 위치를 포함한 자료구조(인덱스) 생성합니다.
컬럼에 대한 정보를 정렬
예시) 책 뒤에 있는 색인 생각
- DBMS는 index를 항상 최신의 정렬된 상태를 유지해아합니다.
- 예를들어서, 나이 컬럼을 예시로 들면 테이블에서 가져온 나이에 대한 데이터를 B+ 트리를 만들면서 정렬시킵니다.
where 절을 설정해주면 나이 컬럼에 해당하는 인덱스를 구성하는 B+ 트리를 탐색해서 효율을 올립니다.- 때문에 insert, delete, update가 수행될 경우 다시 연산이 필요합니다(오버헤드 추가 발생)
- ❗데이터가 변경이나 삭제되었을때 인덱스는 제거되는 것이 아닌 사용되지 않음의 상태가 됩니다. 때문에 공간을 계속적으로 차지하기때문에 사용되지 않는 인덱스는 바로 제거해 주어야 합니다.
Index의 자료구조
- Hash Table
- key-value 형태로 데이터를 저장합니다.
- key 값을 이용해 index를 생성하고 index를 통해 값을 가져옵니다.
- 빠른 데이터 검색이 가능하지만, =(등호) 연산에만 특화되어있습니다.
- B Tree
- 모든 노드에 데이터 저장 가능합니다.
- 데이터가 정렬되어있습니다.
- 2개 이상의 자식을 갖는 트리입니다(노드에 들어있는 KEY 값+1개).
- B+ Tree
- B트리를 개선시킨 트리입니다.
- 리프노드에만 인덱스와 데이터를 저장하고 그 밖의 노드들은 인덱스만 갖습니다.
- 리프노드들은 LinkedList로 연결되어있습니다.
장단점
- 장점
- 데이터를 조회하는 속도가 향상되기 때문에 전체적인 성능을 향상시킬수 있습니다.
- 시스템의 부하를 줄일 수 있습니다.
- 단점
- 인덱스를 관리하기위해서는 DB의 약 10%의 공간을 사용합니다.
- 인덱스를 관리하기위한 추가 작업이 필요합니다.
- 인덱스를 잘못사용한다면 오히려 성능이 악화될 수 있습니다.
랜덤엑세스는 순차적엑세스보다 4~5배 정도 느립니다. 때문에 테이블의 20%~25% 이상 정도의 데이터를 인덱스로 저장하고 탐색을 하게된다면 전체를 탐색하는 것보다 느릴 수 있습니다.
🤔그렇다면 인덱스를 어떤 경우에 사용해야될까?
- 규모가 큰 테이블
- 쿼리에서 자주 사용되는 열
- 데이터의 변경이 자주 발생하지 않는 테이블
- 카디널리티가 높고, 선택도가 높은 컬럼(데이터 중복도가 낮은 Column)
- 카디널리티 : 특정 컬럼의 중복 수치 ex) 중복이 많다면 카디널리티는 낮습니다.
- 선택도 : 특정 집합을 얼마나 잘 골라낼 수 있는지를 의미합니다 ex) 모든 값이 unique하다면 선택도는 1이됩니다. 때문에 선택도가 높은 컬럼에 인덱스를 사용하지만, 또 너무 높은 선택도라면 유용하지 않을 수 있습니다.
- JOIN, WHERE, ORDER BY가 자주 사용되는 열
해당 데이터의 DML이 진행되면?
INSERT
인덱스 페이지에 insert된 데이터를 추가
- 만약 인덱스 페이지가 가득차게된다면, 이를 해결하기위해 추가적인 페이지 사용
- 새로운 인덱스 페이지를 할당하고 기존의 데이터를 두개의 페이지에 분할
- 분할하는 과정에서 redo 로그가 대량으로 발생
- 이렇게 분할하는 과정에서는 다른 트랜잭션의 접근 불가 -> 대기상황 발생
DELETE
- 인덱스에 해당하는 데이터를 제거하면 인덱스 페이지에서 해당 데이터는 제거되는 것이 아니라 사용 안함 처리됨
- 추후에 사용 안함 데이터가 특정 비율이 되면 자동으로 해당 공간을 정리
- 즉, 실제 데이터와 해당하는 인덱스의 개수가 다를 수 있음
UPDATE
- 데이터를 update하는 과정은 인덱스에서 두가지 과정을 거침
- 인덱스에서는 해당하는 인덱스를 제거(사용안함 처리) 후, 새로운 데이터(인덱스)를 추가
- 2배의 작업이 소요됨
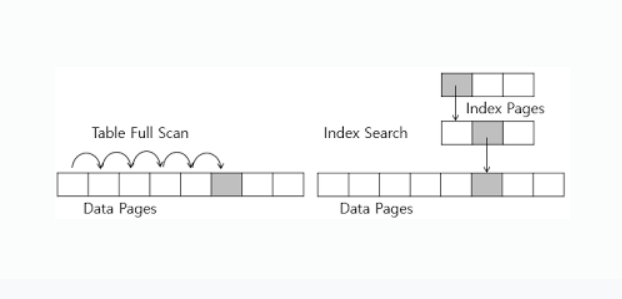
Index Scan vs Full Scan
- Index Scan 방식은 B+Tree 에서 leaf node 까지 찾아 내려간뒤에 데이터를 찾기위해 Disk에 접근한뒤 돌아옵니다..
- Full Scan 방식은 바로 Disk에 접근해서 테이블의 모든 값을 읽은뒤 돌아옵니다.
- 따라서 데이터양이 많아진다면 Full Scan 보다 Index Scan이 유리합니다.
하지만, Index Scan이 효율적으로 설정되지 않거나, Index Scan을 많이 사용하게되면 DISK에 접근하고 돌아오는 과정이 반복되기때문에 추가적인 시간이 추가되기에 비효율적일 수 있습니다.- 따라서 Index Scan으로 탐색하는 데이터가 테이블의 총 데이터의 수와 비슷하다면 Table Scan이 유리할 수 있습니다.
Index Scan이 사용되지 않고 Pull Scan을 하는 경우
- 컬럼의 가공
- ex) where price * 0.9 >10000
- 부정형
- where price != 10000
- like구문의 앞부분이 %인경우
- 첫 글자를 기준으로 정렬하기 때문에 Index를 사용할 수 없습니다.
- 멀티 컬럼에서 두번째 컬럼만 조건으로 사용하는 경우
- 두개 이상의 컬럼으로 만들어진 인덱스를 멀티 컬럼 인덱스라고 합니다.
이때, a,b 컬럼으로 이루어진 인덱스가 존재한다면 a로 정렬한 후 b로 정렬하게 되는데 b로 조건을 걸어주게된다면 Index검색을 할 수 없습니다.
또한 b, a 순으로 조건을 걸어주게되어도 마찬가지입니다.
a 또는 a, b 로 조건을 걸어주게되면 Index 스캔이 가능합니다
하지만, DB의 옵티마이저가 이를 바꿔서 해결해주는 경우가 존재합니다.
- 두개 이상의 컬럼으로 만들어진 인덱스를 멀티 컬럼 인덱스라고 합니다.
인덱스 종류
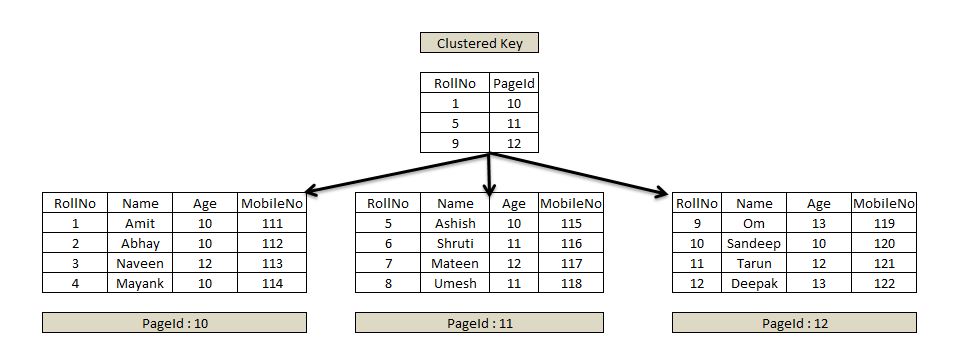
- Clustered Index :
- 테이블의 데이터를 지정된 컬럼에 대해 물리적으로 데이터(데이터 페이지에 있는 실제 데이터)를 재배열
- **Index Page를 키값과 데이터 페이지 번호로 구성하고 검색하고자 하는 데이터의 키값으로 페이지 번호를 검색하여 데이터를 찾는다.
- 개발자가 아닌 MySQL이 자동으로 생성해주는 Index
- 테이블당 1개씩만 허용합니다.
- 때문에, PK가 없다면 Unique 컬럼을 Unique 컬럼이 없다면 Mysql이 내부적으로
Hidden Clustered Index Key(row Id)를 만들어줍니다.
- 때문에, PK가 없다면 Unique 컬럼을 Unique 컬럼이 없다면 Mysql이 내부적으로
- 커버링-인덱스 (커버가능한 인덱스)
쿼리를 만족시킬 수 있는 모든 데이터가 인덱스에 저장되어있는 인덱스를 의미합니다.
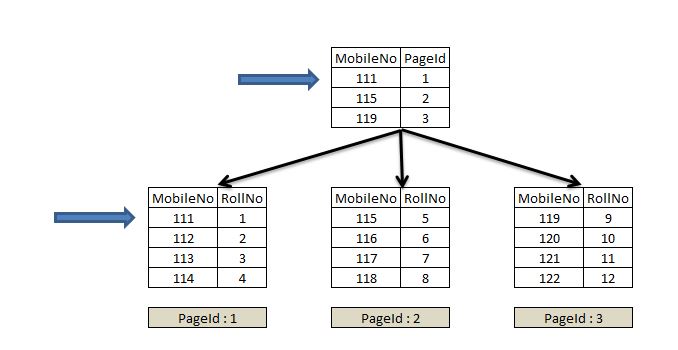
- Non-Clustered Index :
- 데이터 페이지를 건드리지 않고, 별도의 장소에 인덱스 페이지를 생성한후 만들어진 인덱스페이지에서 데이터 페이지로 접근한다.- 개발자가 생성하는 Index
- 멀티 컬럼 Index의 경우 16개의 컬럼이 사용 가능합니다.
- 테이블당 Clustered Index를 제외하고 64개까지 생성 가능합니다.
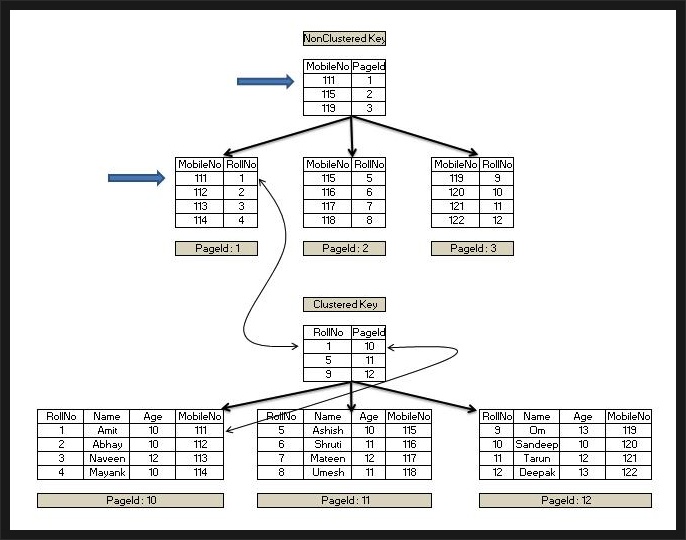
Clustered Index 와 Non-Clustered Index 구조

멋있는 사람 - 일단 하자