
Abstract
본 논문은 비디오 압축을 학습하는 것에 대한 논문이다. 이전의 하이브리드 코딩 접근법은 공간 및 시간 중복을 줄이기 위해 픽셀 공간 연산에 의존하며, 이는 부정확한 모션 추정이나 덜 효과적인 모션 보정이 발생할 수 있다. 본 논문은 피처 공간에서 모든 주요 작업(모션 추정, 모션 압축, 모션 보정 및 잔여 압축 등)을 수행하여 Feature-space Video Coding network(FVC)를 제안한다. 특히, 제안된 변형 가능한 보정 모듈(deformable compensation)에서는 먼저 feature 공간에서 움직임 추정을 적용하며, auto encoder style-network를 사용하여 압축되는 모션 정보(offset maps)를 생성한다. 그런 다음 변형 가능한 컨볼루션(deformable convolution)을 사용하여 움직인 보정을 하고, 예측된 피쳐들을 생성한다. 그 다음 현재 프레임에서 나온 피쳐와 변형 보정 모듈로부터 나온 예측된 피쳐들 사이의 잔여 피쳐를 압축한다. 더 나은 프레임 재구성을 위해 이전에 구성된 여러 프레임의 기준 피쳐는 멀티 프레임 피쳐 퓨젼 모듈의 non-local attention 메커니즘을 사용하여 퓨전된다.
Introduction
현재 대부분의 작업은 중복성을 줄이기 위해 픽셀 수준의 작업(모션 추정 또는 모션 보정)에만 의존한다. 예를 들어, 시간적 중복을 줄이기 위해 픽셀 레벨에서 optical flow 추정과 움직임 보정이 사용된다. 픽셀 수준의 잔차는 auto encoder style network를 사용하여 추가로 압축된다. 그러나 이 픽셀 레벨 패러다임에는 세 가지 한계가 존재한다.
- 픽셀 레벨의 optical flow 정보를 정확하게 생성하는 것이 어려우며, 특히 비정형(non-rigid) 모션 패턴이 복잡한 비디오의 경우에 더 어렵다.
- 충분히 정확한 모션 정보를 추출할 수 있더라도 픽셀 레벨의 모션 보정 프로세스에서 추가 아티팩트가 발생할 수 있다.
- 픽셀 레벨의 잔여 정보를 압축하는 것도 쉬운 일이 아니다.
구조
- F=피쳐 / O=offset Map(원래 픽셀을 다음 픽셀로 얼마나 이동하는지에 대한 지표) / R=잔여 피쳐
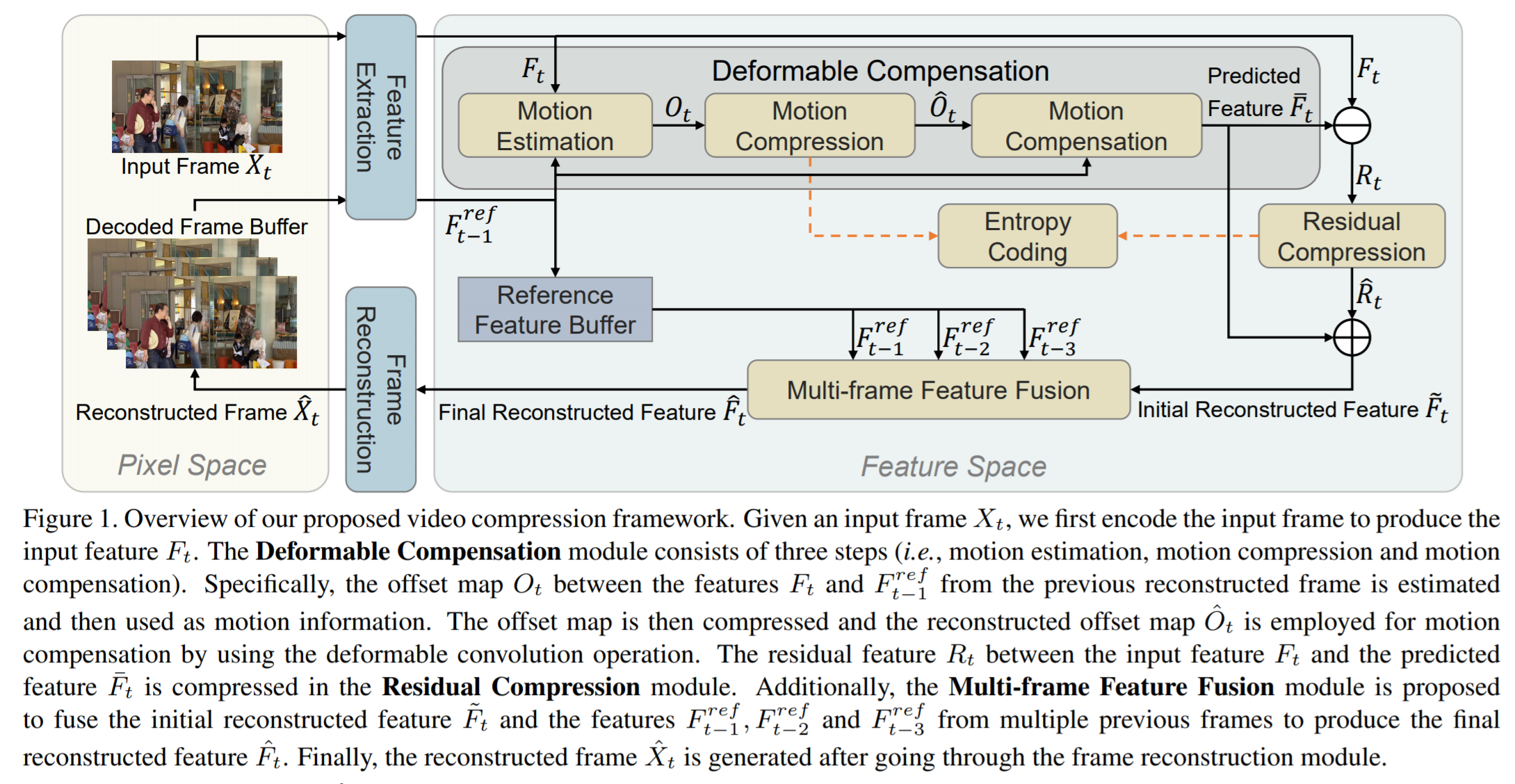

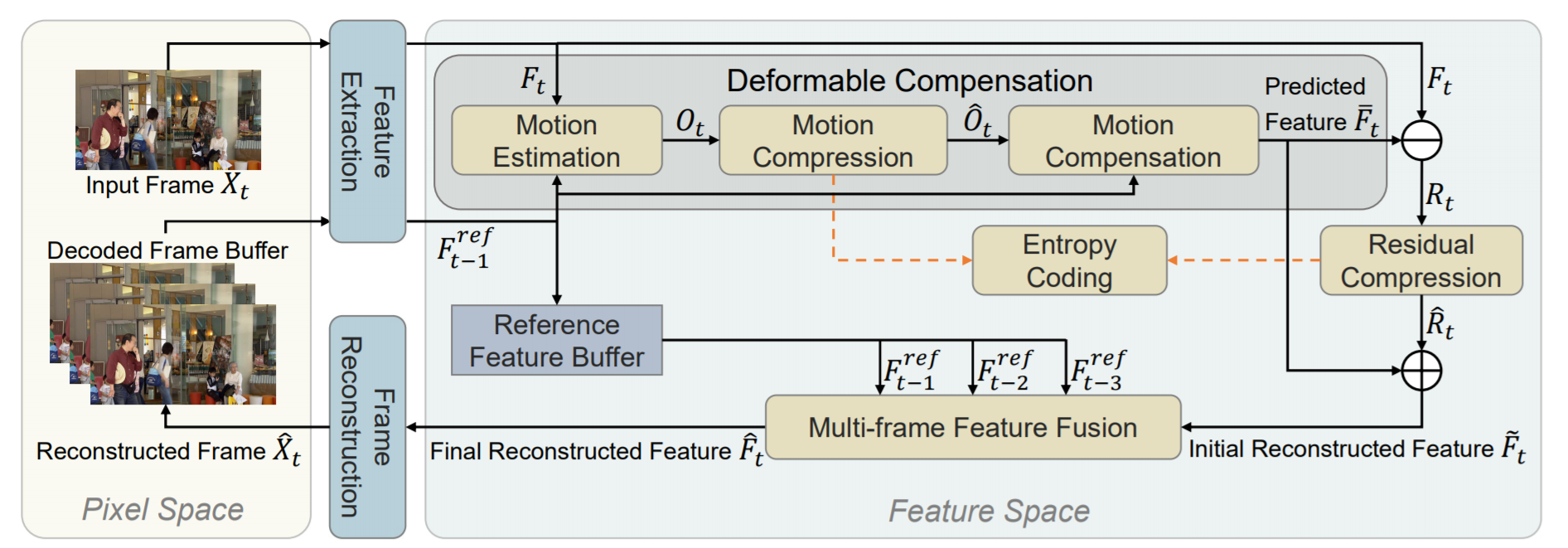
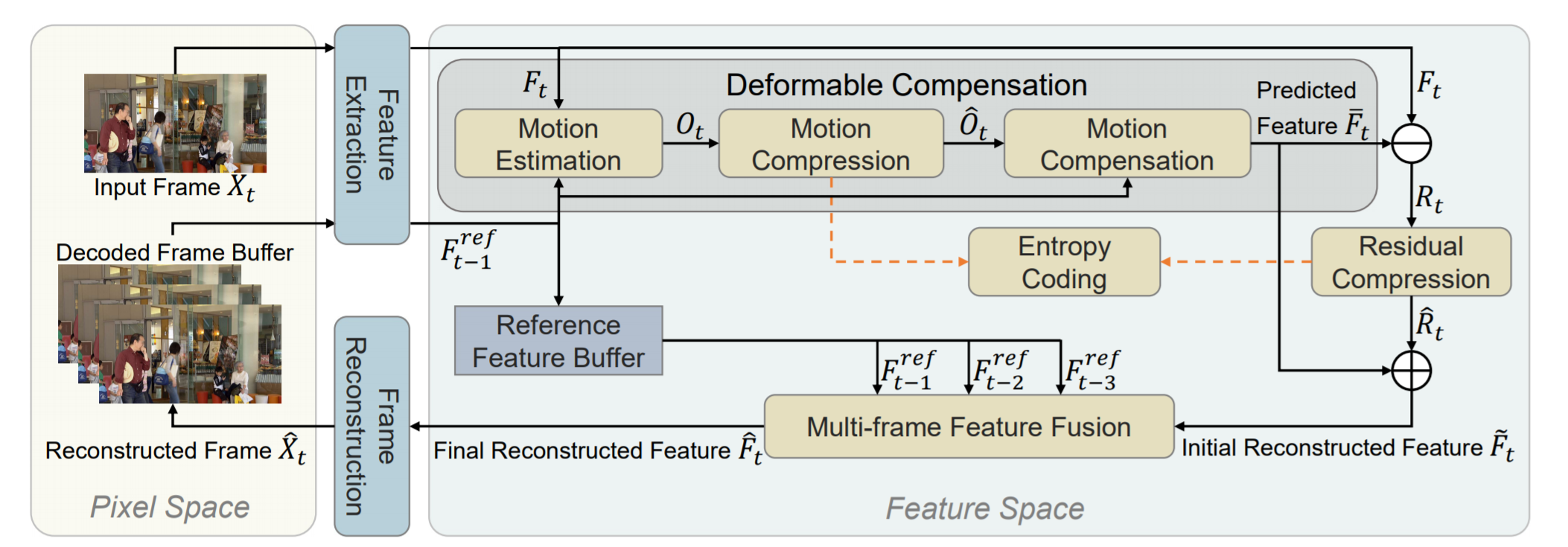
본 연구에서는, 기존의 비디오 코덱에서처럼 픽셀 수준의 연산을 채택하기 위해 기존의 작업을 따르는 대신, 피쳐 공간에서 공간-시간 중복성을 줄임으로써 새로운 FVC를 제안한다. 구체적으로, 먼저 두 개의 연속 프레임에서 추출된 representation들을 기반으로 모션 정보(deformable convolution에 있는 컨볼루젼 커널에서 얻어지는 offset map)을 추정한다. 그런 다음 auto encoder style 네트워크를 사용하여 오프셋 맵을 압축하고 재구성된 오프셋 맵을 이후의 deformable 컨볼루션 작업에 사용하여 보다 정확한 모션 보정을 위해 예측된 피쳐를 생성한다. 그 후 또 다른 auto encoder style 네트워크를 채택하여 원래 입력 피쳐와 예측 피쳐 사이의 잔여 피쳐를 압축한다. 마지막으로, 더 나은 프레임 재구성을 위해 여러 이전 프레임의 기준 피쳐 집합을 결합하기 위해 멀티 프레임 피쳐 퓨젼 모듈을 제안한다.
Methodology
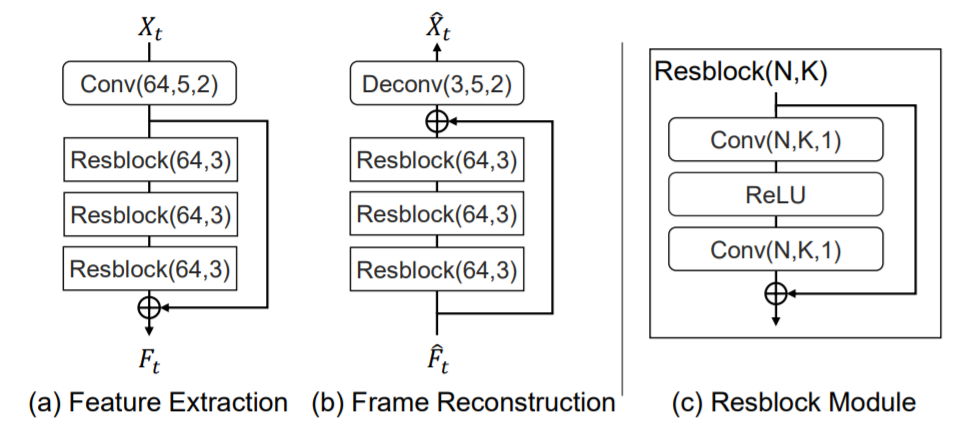
- Feature Extraction
각 프레임의 피쳐를 추출하는 부분 - Deformable Compensation
모션 추청, 모션 압축 및 모션 보정의 세단계로 구성된다. 특히 Feature Extraction에서 나온 피쳐 정보를 기반으로 경량 네트워크를 이용하여 모션 추정을 수행하며, 출력으로 나오는 O(offset map)는 새롭게 제안된 모션 압축 네트워크를 사용하여 압축된 후 디코더에 전달된다. 마지막으로, 재구성된 offset map과 F_t-1이 주어지면 움직임 보정 모듈에서 Deformable convolution을 사용하여 예측된 피쳐를 생성한다.(자세한 내용은 밑 부분 참조) - Residual Compression
보다 나은 재구성을 위해 auto encoding style 네트워크를 사용하여 입력 피쳐 F와 예측 피쳐 F 사이의 잔여 피쳐 R이 압축된다. 재구성된 잔여 피쳐를 예측된 피처 F에 더해준 후, 초기 재구성된 피쳐 F햇를 생성한다. - Frame Reconstruction
(b)와 같이 여러개의 Resblock과 deconv 레이어가 있는 frame decoder는 최종적으로 재구성된 피쳐를 재구성된 frame X로 변환 한다. - Entropy Coding
모션 압축 및 잔여 압축 모듈에서 나온 피쳐들은 엔트로피 코딩을 수행하여 비트 스트림으로 변환된다. 학습하는 동안에, 비트 추정 네트워크를 사용하여 비트수를 추정한다.
- deformable convoultion
기존의 convolution 연산은 고정된 filter를 가지고 있지만, 위의 그림과 같이 이 방법은 고정되지 않고 다양한 사이즈의 filter를 가진다.
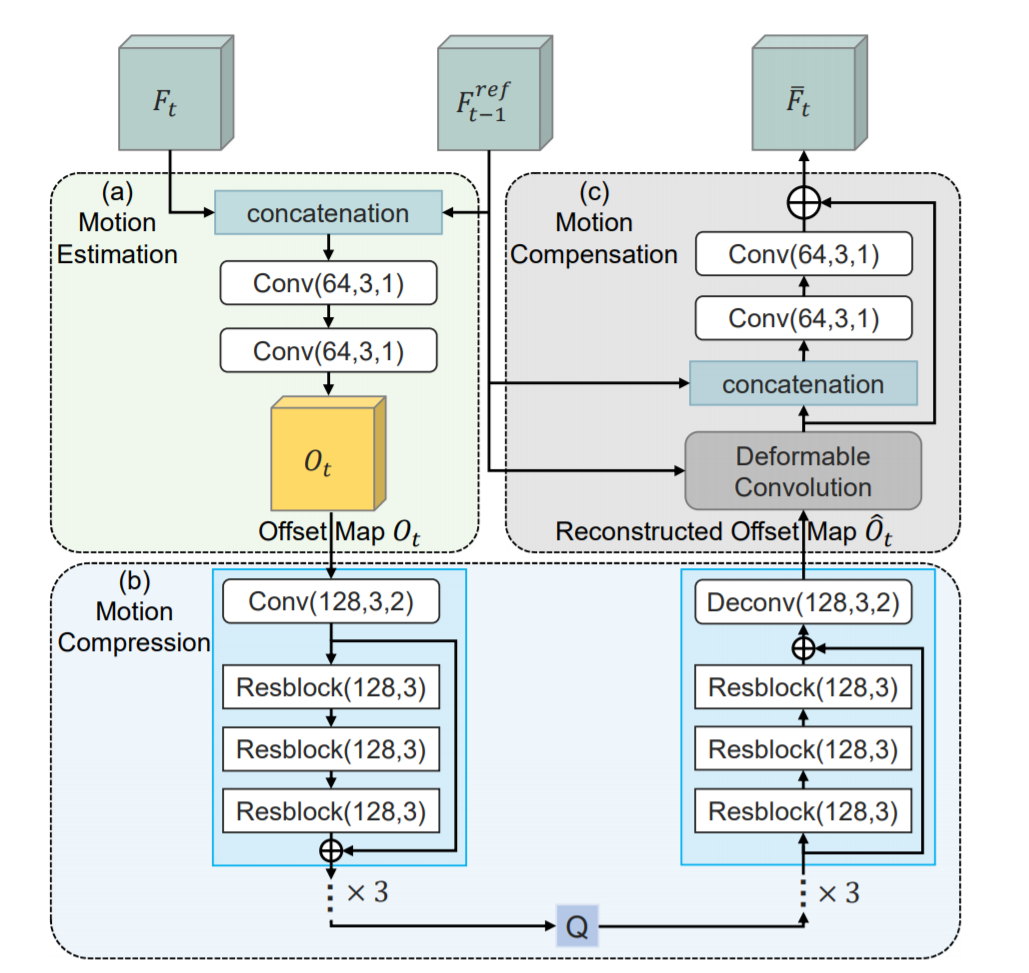

- Deformable Compensation
이전의 비디오 압축 프레임워크는 optical flow 추정 네트워크 및 픽셀 레벨 움직임 보정 네트워크에 의존하였고, 이는 부정확한 프레임 예측 결과로 이어져 뒤에 있는 잔여 압축 모듈에 추가적인 중복성을 가져올 수 있다.- (a) 모듈에서 2개의 conv 블럭을 지나 offset map을 생성한다.
- offset map은 Resblock들을 지나 재구성된 offset
map으로 변환된다. - (c) 모둘에서 deformable convolution 레이어는 피쳐와 offset map을 입력으로 받아 convolution 연산을 진행한다. 이렇게 하면 학습된 동적 offset 커널을 사용하여 복잡한 non-rigid motion pattern들로 비디오를 더 잘 압축하고 보다 정확한 warped 피쳐를 얻을 수 있다.
보다 정확한 예측 피쳐를 생성하기 위해, 두 개의 conv 블럭을 사용하여 최종 피쳐를 출력한다.
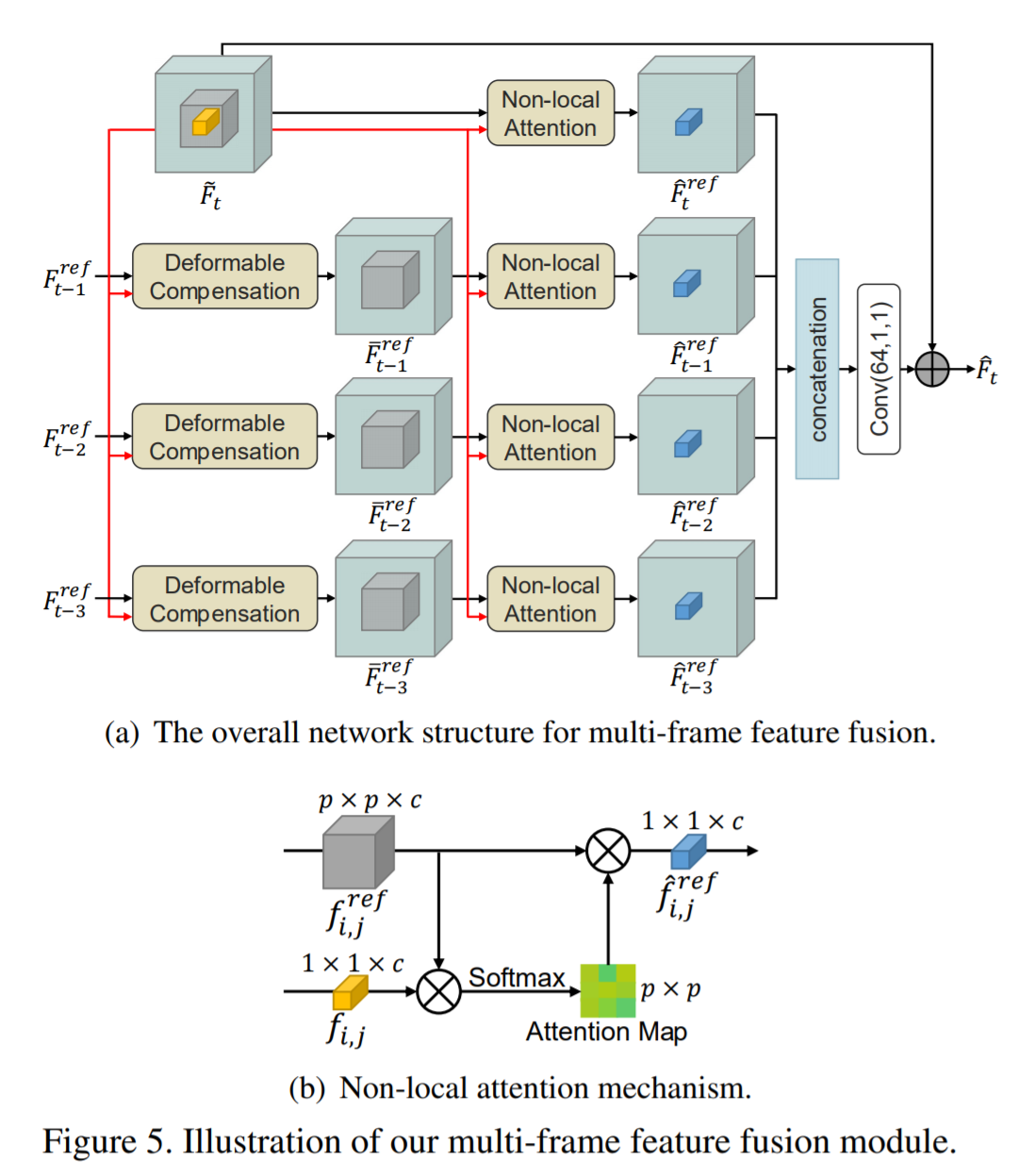
- Multi-frame Feature Fusion
deformable compensation 및 잔여 압축 절차 후에는 예측된 피쳐와 재구성된 잔여 피쳐를 결합하여 초기 재구성된 피쳐를 생성한다. 보다 정확한 최종 재구성 피쳐를 생성하기 위해, (a)와 같이 3개의 이전 프레임에 대한 정보를 활용하기 위해 멀티프레임 피쳐 퓨젼을 제안했다.
Loss Function
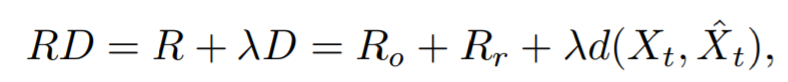
Rate Distortion을 최소화 하는 방향으로 학습한다. Ro와 Rr은 offset map을 인코딩하는데에 사용되는 비트 수와 잔여 피쳐 맵 Rt를 나타낸다. d(Xt,X^t)는 입력 프레임 Xt와 재구성된 프레임 X^t 사이의 차이를 나타내며, 여기서 d()는 평균 제곱 오차 또는 MS-SSIM을 나타낸다. 감마는 rate distortion의 trade-off를 제어하기 위해 사용되는 하이퍼 파라미터이다.
Training Dataset
7프레임 정도의 영상 사용
성능


