
본 논문에서는 에지 요소 감지 및 지각 그룹화 프로세스에 대한 표준 휴리스틱 설계를 생략하고 토큰화된 쿼리, 자체 메커니즘 및 인코딩 디코딩 전략을 transformer내에 통합했다.
-->transformer 기반 공동 end to end 라인을 설계하여 기존의 edge/junction/region detection+proposals+perceptual 그룹화 파이프라인을 skip한다.
(a)holistically-attracted wireframe parsing (HAWP)
(b)proposed LinE segment TRansformers (LETR)
(LETR은 현재 논문에서 제시하고 있는 구조이다.)

-
기존의 접근 방식
일반적으로 라인 감지는 에지 감지를 수행한 후 그룹화 프로세스를 수행한다. 기존의 그룹화 프레임워크는 낮은 수준의 단서를 취합하여 상향식으로 라인 세그멘트를 형성한다. 이미지는 유사한 픽셀 단위 특징을 그룹화하여 line-support 영역으로 분할된다. 그런 다음 라인 세그먼트는 line-support 영역에서 근사치를 계산하고 false positive를 제거하기 위해 검증 단계를 통해 필터링 된다. 또 다른 방법은 파라미터 공간에서 표를 수집하여 허프(hough) 변환을 기반으로 한다. -
딥러닝 기반 접근 방식
L-CNN은 junction proposal 모듈이 junction heatmap을 생성하고 탐지된 junction에 대하여 line proposal로 변환한다. 그리고 라인 검증 모듈은 false-positive 라인들을 제거한다.
AFM은 관련 line을 가리키며 2D 투영 벡터를 포함하는 attraction field 맵을 제안한다. 그런 다음 스퀴즈 모듈이 attraction field 맵에서 벡터화된 라인 세그멘트를 복구한다.
(a)와 같이 HAWP는 AFM과 L-CNN의 하이브리드 모델을 구축한다.

LETR 파이프라인의 구조: 이미지는 백본 네트워크(ResNet 구조에) 공급되고 두 개의 feature맵을 생성하며, 그 다음 각각 coarse 및 fine 인코더에서 사용된다. 그런 다음, coarse 디코더에 의해 초기 coarse 인코더로 부터 나온 feature들을 정제된다. 그 feature들은 다시 fine 디코더로 들어가며 좋은 feature들이 나온다. 마지막으로 라인 세그먼트들은 feed-forward networks(FFNs)에 의해 감지된다.
Bounding box representation: 바운딩 박스 대각선을 사용하여 line 세그멘트를 나타내기 어려운 세가지의 경우
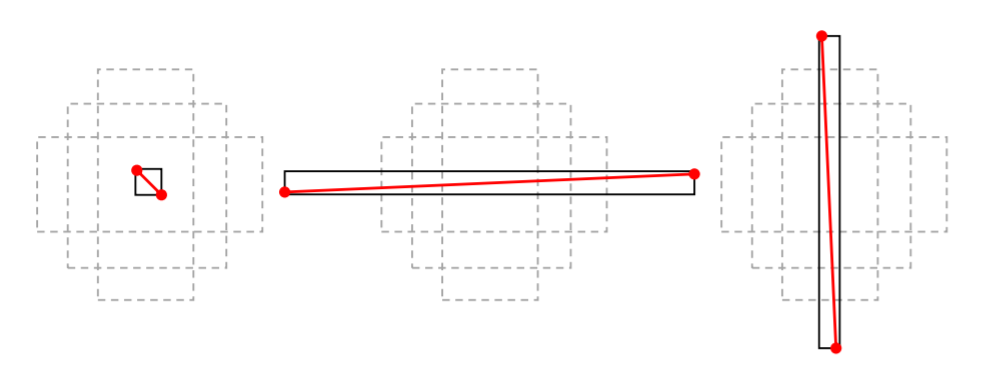
- 모든 벡터화된 라인 세그멘트를 신경망으로 직접 모델링할 수 있는가?
단순한 해결책은 라인 세그멘트를 객체로 간주하고 표준 장애물 감지 접근법에 따라 파이프라인을 구축하는 것이다. 2D 개체의 위치는 일반적으로 경계 상자로 파라미터 처리되므로 벡터화된 라인 세그멘트는 라인 세그멘트 개체와 연결된 바운딩 박스의 대각선에서 직접 읽을 수 있다. 그러나 앵커의 제한된 선택은 표준 2단계 장애물 감지기가 축에 거의 평행한 매우 짧은 라인 세그멘트 또는 라인 세그멘트를 예측하기 어렵게 만든다.
Coarse-to-Fine Strategy
- Coarse Decoding
coarse 디코더 단계에서는 이미지 기능 및 라인 개체를 인코더-디코더 변환 아키텍처로 전달한다. 인코더는 ResNet의 Conv5 (original resolution의 1/32)로 부터 coarse feature를 받는다. 그런 다음, 라인 개체 임베딩들은 각 레이어에 있는 cross-attention 모듈으로부터 coarse feature이 적용된다. fine decoding 단계에서의 높은 효율과 함께 메모리 및 연산 비용을 줄이기 위해 coarse decoding 단계가 필요하다. - Fine Decoding
fine 디코더는 coarse 디코더에서 라인 개체를 상속하고 fine 인코더에서 고해상도 기능을 상속한다. fine 인코더에 대한 특징들은 ResNet의 Conv4출력의 1/16 만큼을 받는다. 라인 개체 임베딩은 coarse 디코딩 단계와 동일한 방식으로 특징 정보를 디코딩 한다.
Line Segment Losses
- Classification Loss
binary cross entropy loss를 기반으로
{ } 항은 positive 예측 지수를 나타낸다.

- Distance Loss
d( , ) 항은 예측 좌표와 대상 좌표 사이의 L1거리의 합을 나타낸다. distance loss는 positive 예측에만 적용된다.
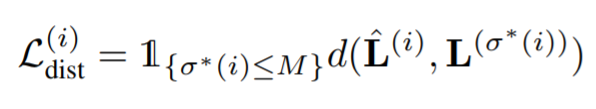
- Total Loss

성능

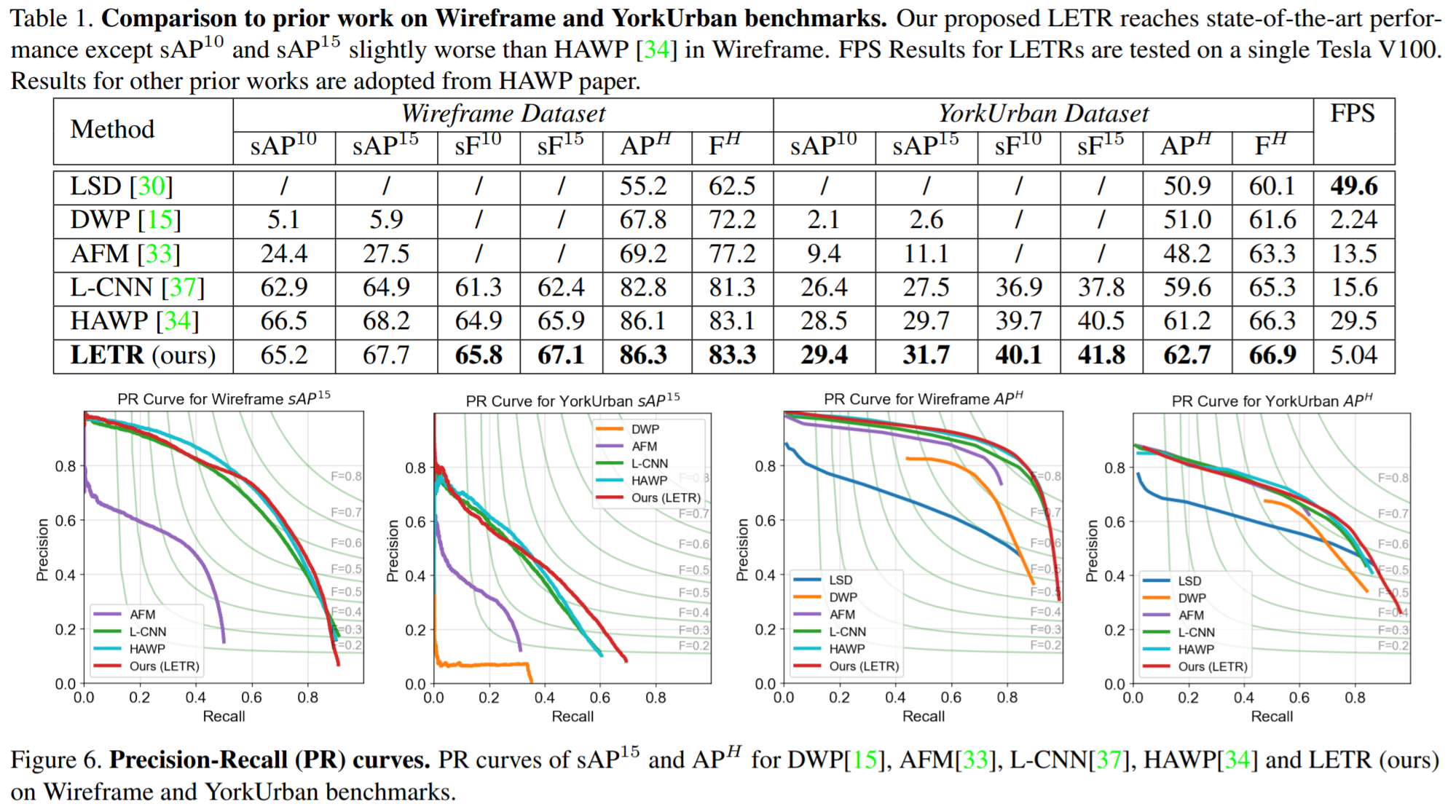
좀 더 공부를 해봐야겠다...아직 이해가 되질 않는다...
