OS : Rocky Linux 8.8 64bit
MySQL : Percona for MySQL 8.0.34
Replica Set : 1(Soure), 2(Replica)
Server (VIP : 10.64.70.17)
node1(DB) : 10.64.70.21
node2(DB) : 10.64.70.22
node3(DB) : 10.64.70.23
node3(Orchestrator DB) : 10.64.70.11
이번 포스팅은 지난 [InnoDB ReplicaSet 소개](https://velog.io/@parrineau/MySQL-MySQL-InnoDB-ReplicaSet)에서 기술했듯이, ReplicaSet의 단점인 HA 미구현을 Orchestrator로 구현해보도록 하겠습니다.
Orchestrator 포스팅, 특히 Hook 메소드를 구현한 포스팅 위주로 응용 예정이니 참고 부탁드립니다.

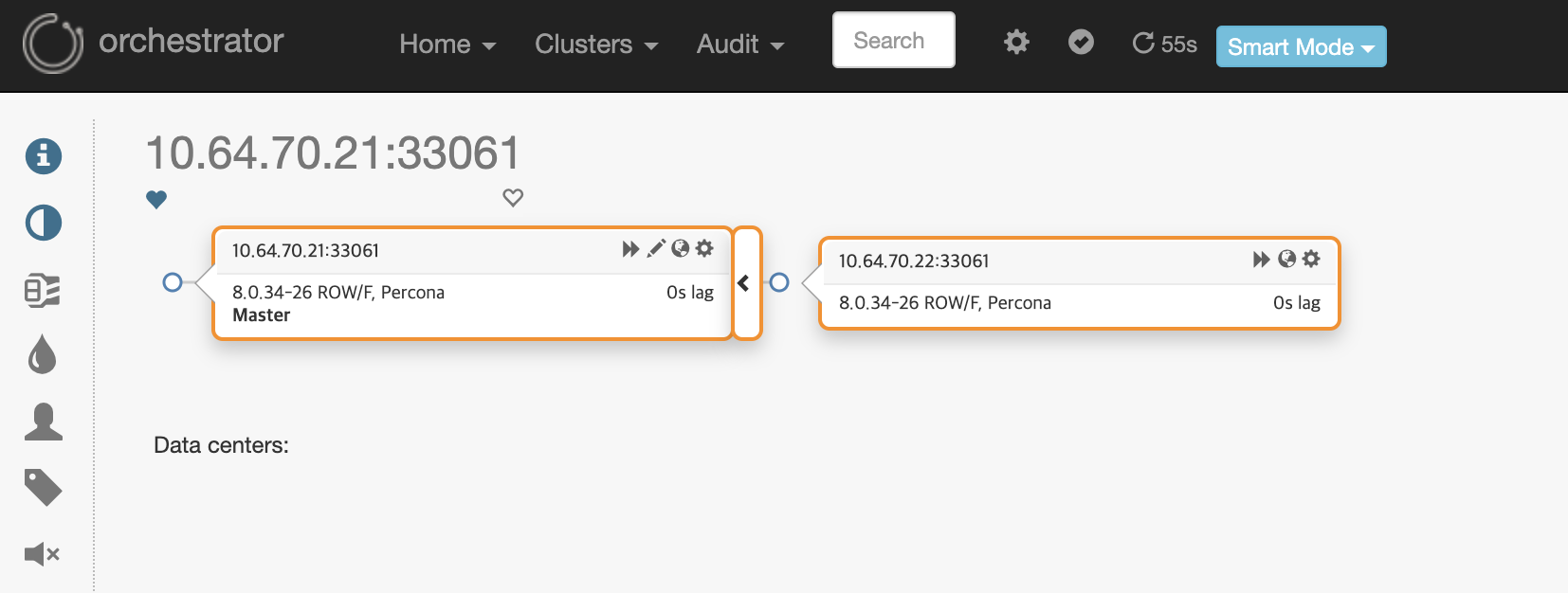
위 이미지와 같이 1P <-> 2S 형태의 구조로 이루어져 있습니다.
현재 실제 IP(RIP)로 복제가 구성되어 있으며, 윗 단에서는 VIP로 접속합니다.
VIP는 Keepalived로 Primary Node만 기동하여 컨트롤 합니다.
### Keepalived.conf (node1, node2, node3 동일)
global_defs {
router_id DB_CLUSTER_0
}
vrrp_instance VI_1 {
state MASTER
interface enp0s3
virtual_router_id 51
priority 100 ## Master&Slave 값 동일하게 설정
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.64.70.17/24
}
}orc.conf pre-setting
Keepalived를 이용하여 Primary Node에만 Keepalived를 구동해야하기에, Orchestrator에서의 Hook Function에 적절한 행동이 필요합니다.
아래는, Keepalived 컨트롤 스크립트 예시입니다.
### Keepalived_control.sh
#!/bin/bash
failed_host=$1
successor_host=$2
echo "##### DEADMASTER (UNREACHABLEMASTER) Server will be stooped Keepalived #####"
expect << EOF
spawn ssh -o StrictHostKeyChecking=no root@${failed_host}
expect "password:" {send "rplinux\r"}
expect "#" {send "systemctl stop keepalived\r"}
expect "#" {send "exit\r"}
EOF
echo "##### NEWMASTER Server will be started Keepalived #####"
expect << EOF
spawn ssh -o StrictHostKeyChecking=no root@${successor_host}
expect "password:" {send "rplinux\r"}
expect "#" {send "systemctl start keepalived\r"}
expect "#" {send "exit\r"}
EOF
echo "$(date +'%Y-%m-%d %H:%M:%S') ${failed_host} -> ${successor_host} Switched..." >> /usr/local/orchestrator/switched.logOrchestrator에서 PostFailoverProcesses의 훅에서 위 스크립트를 실행하기 위해 수정합니다.
### Orchestrator.conf.json
],
"PreFailoverProcesses": [
"echo 'Will recover from {failureType} on {failureCluster}' >> /tmp/recovery.log"
],
"PostFailoverProcesses": [
"echo '(for all types) Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Successor: {successorHost}:{successorPort}' >> /tmp/recovery.log",
"/usr/local/orchestrator/keepalived_control.sh {failedHost} {successorHost}" ## 해당 구문 추가
],Failover (1)
Primary Node 중단 후 ReplicaSet의 변화 및 Orchestrator 관제의 변화를 살펴보겠습니다.
### node1
[root@vm2-1 /]# mysqladmin -uroot -p -S /tmp/mysql_8.0.sock shutdown### Orchestrator log
...
[mysql] 2023/10/30 08:55:06 packets.go:123: closing bad idle connection: EOF
2023-10-30 08:55:06 INFO topology_recovery: detected UnreachableMaster failure on 10.64.70.21:33061
2023-10-30 08:55:06 INFO topology_recovery: Running 1 OnFailureDetectionProcesses hooks
2023-10-30 08:55:06 INFO topology_recovery: Running OnFailureDetectionProcesses hook 1 of 1: echo 'Detected UnreachableMaster on 10.64.70.21:33061. Affected replicas: 2' >> /tmp/recovery.log
2023-10-30 08:55:06 INFO auditType:emergently-read-topology-instance instance:10.64.70.21:33061 cluster:10.64.70.21:33061 message:UnreachableMaster
2023-10-30 08:55:06 INFO CommandRun(echo 'Detected UnreachableMaster on 10.64.70.21:33061. Affected replicas: 2' >> /tmp/recovery.log,[])
...
2023-10-30 08:55:06 INFO topology_recovery: Completed OnFailureDetectionProcesses hook 1 of 1 in 34.512634ms
2023-10-30 08:55:07 INFO topology_recovery: done running OnFailureDetectionProcesses hooks
2023-10-30 08:55:07 INFO executeCheckAndRecoverFunction: proceeding with UnreachableMaster recovery on 10.64.70.21:33061; isRecoverable?: false; skipProcesses: false
2023-10-30 08:55:07 INFO auditType:emergently-read-topology-instance instance:10.64.70.23:33061 cluster:10.64.70.21:33061 message:UnreachableMaster
2023-10-30 08:55:07 INFO auditType:emergently-read-topology-instance instance:10.64.70.22:33061 cluster:10.64.70.21:33061 message:UnreachableMaster
2023-10-30 08:55:07 INFO checkAndExecuteFailureDetectionProcesses: could not register UnreachableMaster detection on 10.64.70.21:33061
...
2023-10-30 08:55:12 INFO topology_recovery: Completed PreFailoverProcesses hook 1 of 1 in 831.405µs
2023-10-30 08:55:12 INFO topology_recovery: done running PreFailoverProcesses hooks
2023-10-30 08:55:12 INFO topology_recovery: RecoverDeadMaster: will recover 10.64.70.21:33061
2023-10-30 08:55:12 INFO topology_recovery: RecoverDeadMaster: masterRecoveryType=MasterRecoveryGTID
2023-10-30 08:55:12 INFO topology_recovery: RecoverDeadMaster: regrouping replicas via GTID
2023-10-30 08:55:12 DEBUG Stopping 2 replicas via StopReplicationNice
...
2023-10-30 08:55:13 INFO CommandRun(/usr/local/orchestrator/keepalived_control.sh 10.64.70.21 10.64.70.23,[])
2023-10-30 08:55:13 INFO CommandRun/running: bash /tmp/orchestrator-process-cmd-3208404365
2023-10-30 08:55:14 INFO CommandRun: ##### DEADMASTER (UNREACHABLEMASTER) Server will be stooped Keepalived #####
spawn ssh -o StrictHostKeyChecking=no root@10.64.70.21
root@10.64.70.21's password:
Activate the web console with: systemctl enable --now cockpit.socket
Last login: Mon Oct 30 08:53:43 2023 from 10.0.9.46
[root@vm2-1 ~]# systemctl stop keepalived
[root@vm2-1 ~]# ##### NETMASTER Server will be started Keepalived #####
spawn ssh -o StrictHostKeyChecking=no root@10.64.70.23
root@10.64.70.23's password:
Activate the web console with: systemctl enable --now cockpit.socket
Last login: Mon Oct 30 08:40:31 2023 from 10.0.9.46
[root@vm2-3 ~]# systemctl start keepalived
...
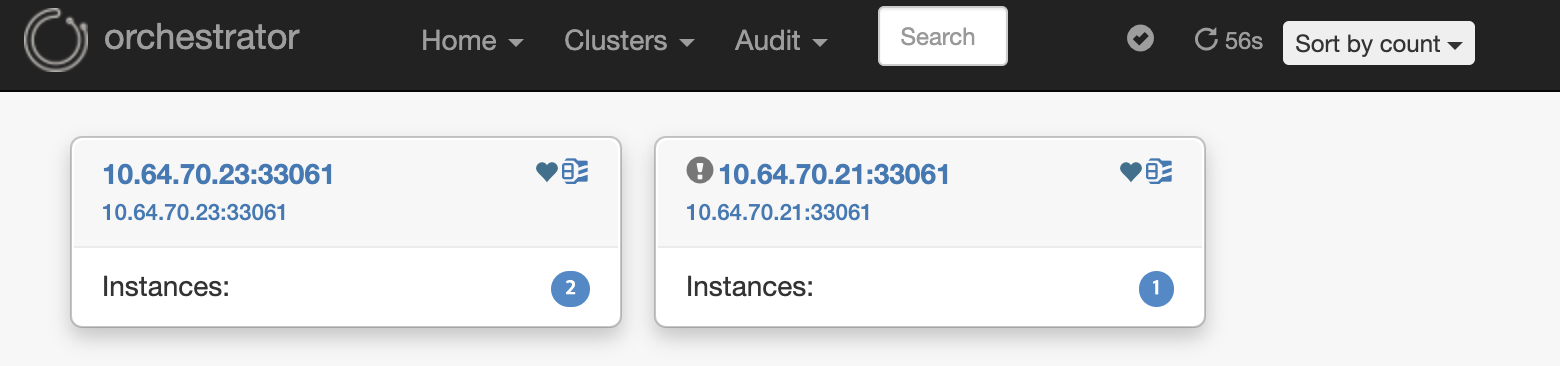

해당 프로세스 후 Orchestrator는 두개의 그룹이 관제되는것을 볼 수 있습니다.
node1(10.64.70.21) 노드는 분리되었으며, Orchcestrator가 node3(10.64.70.23)으로 승격되었고, node2(10.64.70.22)노드가 Secondary로 승격됐음을 알 수 있습니다.
Failover (2)
이렇게만 끝난다면 가장 이상적인 시나리오 일 것 같은데요...
하지만 Shell에서 ReplicaSet의 Status는 처참합니다.
MySQL localhost:33060+ ssl JS > rs = dba.getReplicaSet()
You are connected to a member of replicaset 'replicaSet'.
<ReplicaSet:replicaSet>
MySQL localhost:33060+ ssl JS > rs.status()
WARNING: Unable to connect to the PRIMARY of the ReplicaSet replicaSet: MYSQLSH 51118: Could not open connection to 'vm2-1:33061': Can't connect to MySQL server on 'vm2-1:33061' (111)
Cluster change operations will not be possible unless the PRIMARY can be reached.
If the PRIMARY is unavailable, you must either repair it or perform a forced failover.
See \help forcePrimaryInstance for more information.
{
"replicaSet": {
"name": "replicaSet",
"primary": "vm2-1:33061",
"status": "UNAVAILABLE",
"statusText": "PRIMARY instance is not available, but there is at least one SECONDARY that could be force-promoted.",
"topology": {
"vm2-1:33061": {
"address": "vm2-1:33061",
"connectError": "Could not open connection to 'vm2-1:33061': Can't connect to MySQL server on 'vm2-1:33061' (111)",
"fenced": null,
"instanceRole": "PRIMARY",
"mode": null,
"status": "UNREACHABLE"
},
"vm2-2:33061": {
"address": "vm2-2:33061",
"fenced": true,
"instanceErrors": [
"ERROR: Replication source misconfigured. Expected vm2-1:33061 but is 10.64.70.23:33061."
],
"instanceRole": "SECONDARY",
"mode": "R/O",
"replication": {
"applierStatus": "APPLIED_ALL",
"applierThreadState": "Waiting for an event from Coordinator",
"applierWorkerThreads": 4,
"expectedSource": "vm2-1:33061",
"receiverStatus": "ON",
"receiverThreadState": "Waiting for source to send event",
"replicationLag": null,
"replicationSsl": null,
"source": "10.64.70.23:33061"
},
"status": "ERROR",
"transactionSetConsistencyStatus": null
},
"vm2-3:33061": {
"address": "vm2-3:33061",
"fenced": false,
"instanceErrors": [
"ERROR: Instance is NOT a PRIMARY but super_read_only option is OFF. Accidental updates to this instance are possible and will cause inconsistencies in the replicaset.",
"ERROR: Replication source channel is not configured, should be vm2-1:33061."
],
"instanceRole": "SECONDARY",
"mode": "R/W",
"replication": {
"applierStatus": null,
"expectedSource": "vm2-1:33061",
"receiverStatus": null,
"replicationSsl": null
},
"status": "ERROR",
"transactionSetConsistencyStatus": null
}
},
"type": "ASYNC"
}
}ReplicaSet은 여전히 node1(vm2-1)을 Primary로 간주하고 있고, 승격된 node3 또한 어딘가가 문제가 있어보입니다.
해당 문제는 아래 도큐먼트에서 알 수 있습니다.
(https://dev.mysql.com/doc/mysql-shell/8.0/en/replicaset-adopting.html)
''' As an alternative to creating a ReplicaSet from scratch, you can adopt an existing replication setup using the adoptFromAR option with dba.createReplicaSet(). The replication setup is scanned, and if it is compatible with the InnoDB ReplicaSet Limitations, AdminAPI creates the necessary metadata. Once the replication setup has been adopted, you can only use AdminAPI to administer the InnoDB ReplicaSet. '''
해당 설명으로 예상하건대, 위 오류와 같이 ReplicaSet은 구성 시 각 노드에 생성되는 'mysql_innodb_cluster_metadata' 스키마에서 메타 정보를 가져와 정보를 뿌려줍니다.
위 오류에서 나온 것과 같이 replicaSet은 기본적으로 Primary는 super_read_only (root 등 슈퍼 계정에서의 조작 조차 막음) 값이 꺼져있어야 하며, Secondary는 반대로 켜져있어야 합니다.
Failover (3)
이렇다면 제대로 기능을 쓸 수 있을까요?
Orchestrator가 Failover 될 경우 자동으로 CHANGE MASTER TO~ 구문을 이용하고 (기존 복제 방식을 채택하고), super_read_only를 조작하여 (node의 ReplicaSet 메타데이터와 다르고) 결국 1회성 HA밖에 지원할 수 없습니다.
그리하여, 우리는 ReplicaSet의 옵션을 적절히 사용하여 이를 해결해야 합니다.
MySQL localhost:33060+ ssl JS > rs.forcePrimaryInstance('10.64.70.23:33061')
* Connecting to replicaset instances
** Connecting to vm2-2:33061
** Connecting to vm2-3:33061
* Waiting for all received transactions to be applied
vm2-3:33061 will be promoted to PRIMARY of the replicaset and the former PRIMARY will be invalidated.
* Checking status of last known PRIMARY
NOTE: vm2-1:33061 is UNREACHABLE
* Checking status of promoted instance
NOTE: vm2-3:33061 has status ERROR
* Checking transaction set status
* Promoting vm2-3:33061 to a PRIMARY...
* Updating metadata...
vm2-3:33061 was force-promoted to PRIMARY.
NOTE: Former PRIMARY vm2-1:33061 is now invalidated and must be removed from the replicaset.
* Updating source of remaining SECONDARY instances
** Changing replication source of vm2-2:33061 to vm2-3:33061
Failover finished successfully.
MySQL localhost:33060+ ssl JS > rs.status()
{
"replicaSet": {
"name": "replicaSet",
"primary": "vm2-3:33061",
"status": "AVAILABLE_PARTIAL",
"statusText": "The PRIMARY instance is available, but one or more SECONDARY instances are not.",
"topology": {
"vm2-1:33061": {
"address": "vm2-1:33061",
"connectError": "Could not open connection to 'vm2-1:33061': Can't connect to MySQL server on 'vm2-1:33061' (111)",
"fenced": null,
"instanceRole": null,
"mode": null,
"status": "INVALIDATED"
},
"vm2-2:33061": {
"address": "vm2-2:33061",
"instanceRole": "SECONDARY",
"mode": "R/O",
"replication": {
"applierStatus": "APPLIED_ALL",
"applierThreadState": "Waiting for an event from Coordinator",
"applierWorkerThreads": 4,
"receiverStatus": "ON",
"receiverThreadState": "Waiting for source to send event",
"replicationLag": null,
"replicationSsl": "ECDHE-RSA-AES128-GCM-SHA256 TLSv1.2"
},
"status": "ONLINE"
},
"vm2-3:33061": {
"address": "vm2-3:33061",
"instanceRole": "PRIMARY",
"mode": "R/W",
"status": "ONLINE"
}
},
"type": "ASYNC"
}
}무서운 오류 내용이 사라졌습니다.
(forcePrimaryInstance를 이용하려면 기존 Primary 노드가 OFF 상태여야하기에, 기동 전 해당 커맨드를 수행합니다.)
-> 'force' 옵션이 무언가 위험할 수 있는데, 이것은 차후 부하 테스트를 이용하여 검증하도록 하겠습니다. (여기서 ReplicaSet의 강력한 기능인 Incremental 기능을 이용합니다.)
해당 작업 후 다시 DeadMaster를 기동 후 Rejoin 합니다.
[root@vm2-1 /]# mysqld_safe --defaults-file=/etc/my.cnf_8.0 --user=mysql &
[1] 258959
[root@vm2-1 /]# mysqld_safe Adding '/mysql/Percona-Server-8.0.34-26-Linux.x86_64.glibc2.17/lib/mysql/libjemalloc.so.1' to LD_PRELOAD for mysqld
2023-10-30T13:15:48.344498Z mysqld_safe Logging to '/mysql/mysql_log/mysql.err'.
2023-10-30T13:15:48.365866Z mysqld_safe Starting mysqld daemon with databases from /mysql/mysql_data MySQL localhost:33060+ ssl JS > rs.rejoinInstance('10.64.70.21:33061')
* Validating instance...
This instance reports its own address as vm2-1:33061
vm2-1:33061: Instance configuration is suitable.
** Checking transaction state of the instance...
The safest and most convenient way to provision a new instance is through automatic clone provisioning, which will completely overwrite the state of 'vm2-1:33061' with a physical snapshot from an existing replicaset member. To use this method by default, set the 'recoveryMethod' option to 'clone'.
WARNING: It should be safe to rely on replication to incrementally recover the state of the new instance if you are sure all updates ever executed in the replicaset were done with GTIDs enabled, there are no purged transactions and the new instance contains the same GTID set as the replicaset or a subset of it. To use this method by default, set the 'recoveryMethod' option to 'incremental'.
Incremental state recovery was selected because it seems to be safely usable. ## Deadmaster에서의 수행본이 없기에 incremental 수행
* Rejoining instance to replicaset...
** Changing replication source of vm2-1:33061 to vm2-3:33061
** Checking replication channel status...
** Waiting for rejoined instance to synchronize with PRIMARY...
** Transactions replicated ############################################################ 100%
* Updating the Metadata...
The instance 'vm2-1:33061' rejoined the replicaset and is replicating from vm2-3:33061.
MySQL localhost:33060+ ssl JS > rs.status()
{
"replicaSet": {
"name": "replicaSet",
"primary": "vm2-3:33061",
"status": "AVAILABLE",
"statusText": "All instances available.",
"topology": {
"vm2-1:33061": {
"address": "vm2-1:33061",
"instanceRole": "SECONDARY",
"mode": "R/O",
"replication": {
"applierStatus": "APPLIED_ALL",
"applierThreadState": "Waiting for an event from Coordinator",
"applierWorkerThreads": 4,
"receiverStatus": "ON",
"receiverThreadState": "Waiting for source to send event",
"replicationLag": null,
"replicationSsl": "ECDHE-RSA-AES128-GCM-SHA256 TLSv1.2"
},
"status": "ONLINE"
},
"vm2-2:33061": {
"address": "vm2-2:33061",
"instanceRole": "SECONDARY",
"mode": "R/O",
"replication": {
"applierStatus": "APPLIED_ALL",
"applierThreadState": "Waiting for an event from Coordinator",
"applierWorkerThreads": 4,
"receiverStatus": "ON",
"receiverThreadState": "Waiting for source to send event",
"replicationLag": null,
"replicationSsl": "ECDHE-RSA-AES128-GCM-SHA256 TLSv1.2"
},
"status": "ONLINE"
},
"vm2-3:33061": {
"address": "vm2-3:33061",
"instanceRole": "PRIMARY",
"mode": "R/W",
"status": "ONLINE"
}
},
"type": "ASYNC"
}
}[root@vm2-1 /]# hostname -I
10.64.70.21 10.64.23.183 192.168.122.1
[root@vm2-2 /]# hostname -I
10.64.70.22 10.64.21.254 192.168.122.1
[root@vm2-3 /]# hostname -I
10.64.70.23 10.64.70.17 10.64.21.44 192.168.122.1 ## VIP 플로팅
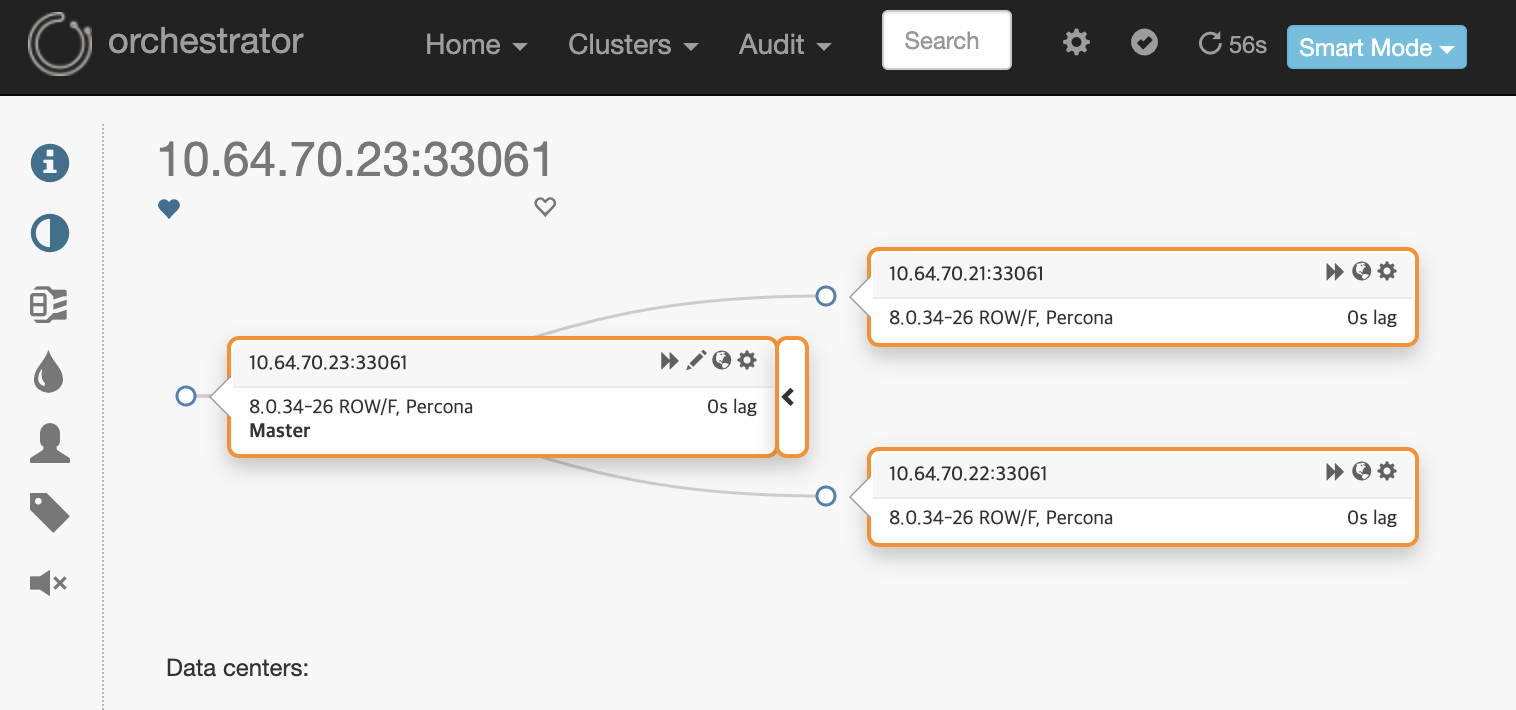
HA를 지원하지 않는 ReplicaSet에서 Orchestrator를 이용하여 HA를 구현했습니다.
다음 포스팅은, Jmeter를 이용하여 해당 시나리오가 적절한지(복제가 깨지진 않는지) 테스트하여 포스팅 하도록 하겠습니다.
