OS : Rocky Linux 8.8 64bit
MySQL : Percona for MySQL 8.0.34
Replica Set : 1(Soure), 2(Replica)
Server (VIP : 10.64.70.17)
node1(DB) : 10.64.70.21
node2(DB) : 10.64.70.22
node3(Orchestrator DB) : 10.64.70.11
이번 포스팅은 앞서 포스팅에 언급한 내용인 ReplicaSet의 HA 미구현을 Orchestrator로 구현하는 것이 적합한지 테스트 해보겠습니다.
먼저 새로운 소식이 있었는데요, Oracle MySQL이 Shell을 이용한 InnoDB Cluster와 ReplicaSet 기능을 출시했을 때, 앞으로 거의 대부분의 MySQL 작업을 Shell에서 할지도 모른다는 생각을 했었습니다.
(도큐먼트에서 MySQL Shell Admin API를 적극 권고하기도 합니다.)
바로 MySQL 8.2에서 MariaDB의 Maxscale과 유사한 기능인 Read/Write Splitted 기능을 제공하며, 이에 대한 예시가 MySQL ReplicaSet이라는 점입니다.
https://blogs.oracle.com/mysql/post/mysql-82-transparent-readwrite-splitting
(하지만 InnoDB Cluster가 주력이기에 HA 지원은 여전히 지원하지 않을 듯 한 늬앙스를 풍깁니다.)
Jmeter

Apache Jmeter는 여러가지 상황에서 서비스의 성능을 측정하고 분석하기 위해 나온 툴입니다.
JDBC, FTP, HTTP, TCP 연결, OS 네이티브 프로세스를 위한 단위 테스트 도구로서 사용할 수 있으며, 이번 포스팅은 MySQL 인 만큼 JDBC를 이용한 부하분산 테스트를 할 예정입니다.
부하/분산 테스트 툴은 Jmeter 외에 저명한 툴인 Sysbench도 존재합니다.
Sysbench는 Jmeter와 다르게 데이터 샘플을 원하는 양 만큼 적재할 수 있고, 샘플 시나리오 (Read/Write, Read Only, OLTP 등)를 이용하여 간단하게 테스트 할 수 있습니다.
MySQL의 성능 테스트에서는 Sysbench가 가장 좋은 선택인 것 같지만, Sysbench는 테스트 도중 우리가 이루고자 하는 HA(Failover) 도중 DB 커넥션이 잠깐이라도 유실된다면 테스트는 곧바로 Aborted됩니다.
(혹시라도 해당 환경의 테스트를 Sysbench로 구현 가능하다면 알려주시면 감사하겠습니다.)
그리하여 Jmeter로 이번 테스트를 진행토록 하겠습니다.
Jmeter Setting

아이콘 두번째 버튼을 눌러, Templates 선택창으로 이동해 JDBC Load Test를 클릭하여 Create 합니다.

MySQL 테스트이므로, Driver Class에서 mysql JDBC 드라이버를 선택합니다.
(MySQL JDBC 드라이버가 없다면 아래에서 설치 후 jmeter lib 경로에 복사합니다.)
https://dev.mysql.com/downloads/connector/j/

DB 설정에 맞게 초기 접근 정보를 세팅합니다.
Vaildation Query : 커넥션 시 먼저 특정 쿼리를 던져 접속을 확인합니다.
(주로 세션 타임아웃을 방지하기 위해 쓰이기도 합니다.)
SELECT 1; 처럼 간단한 쿼리문으로도 충분합니다.
DatabaseURL : jdbc 접속 URL 표준에 맞게 작성합니다.
ex) jdbc:mysql://[DB_HOST]:[DB_PORT]/[DB_SCHEMA]
여기서 [DB_HOST]는 VIP입니다.
username/password : 해당 스키마에 충분한 권한이 있는 계정으로 설정합니다.
MySQL Table Setting
mysql> SHOW CREATE TABLE insert_test.tb_test;
+---------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+---------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| tb_test | CREATE TABLE `tb_test` (
`id` int NOT NULL AUTO_INCREMENT,
`col1` varchar(20) DEFAULT NULL,
`time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3 |
+---------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)간단한 테이블을 생성하였습니다.
데이터 삽입은 아래 SQL로 통일합니다.
INSERT INTO insert_test.tb_test VALUES(DEFAULT, @@hostname, now())
->
+----+-------+---------------------+
| id | col1 | time |
+----+-------+---------------------+
| 1 | vm2-1| 2023-11-01 10:16:37 |
+----+-------+---------------------+
1 row in set (0.00 sec)@@hostname을 이용해 현재 커넥션된 DB 이름을 가져오고, 데이터 삽입 시간을 입력합니다.
이것을 이용해 어느 row부터 언제 Failover 될 수 있는지 알 수 있습니다.
데이터를 모두 지우고, Jmeter에 해당 쿼리문을 등록합니다.
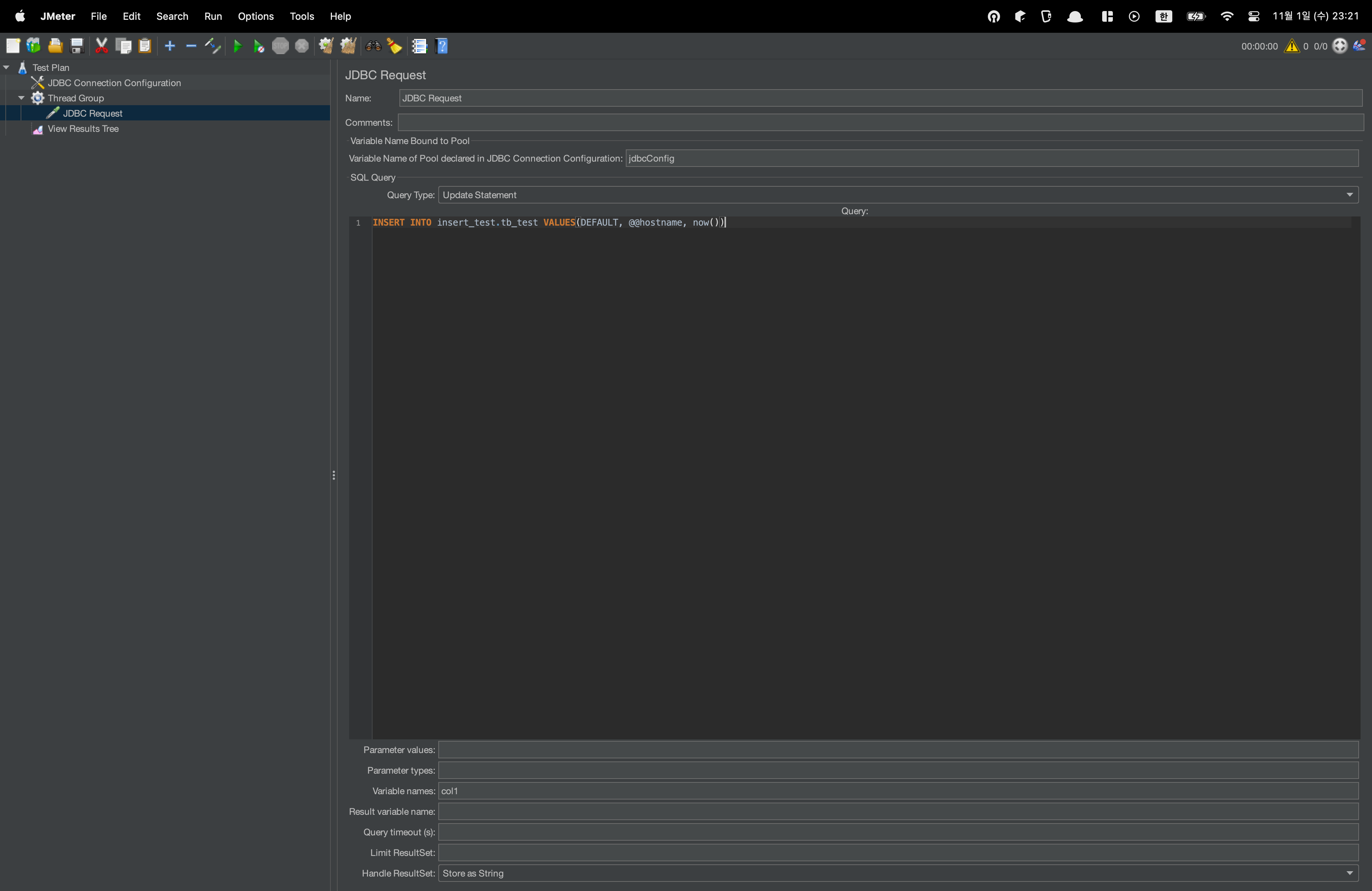
Query Type을 Update Statement로 변경합니다.
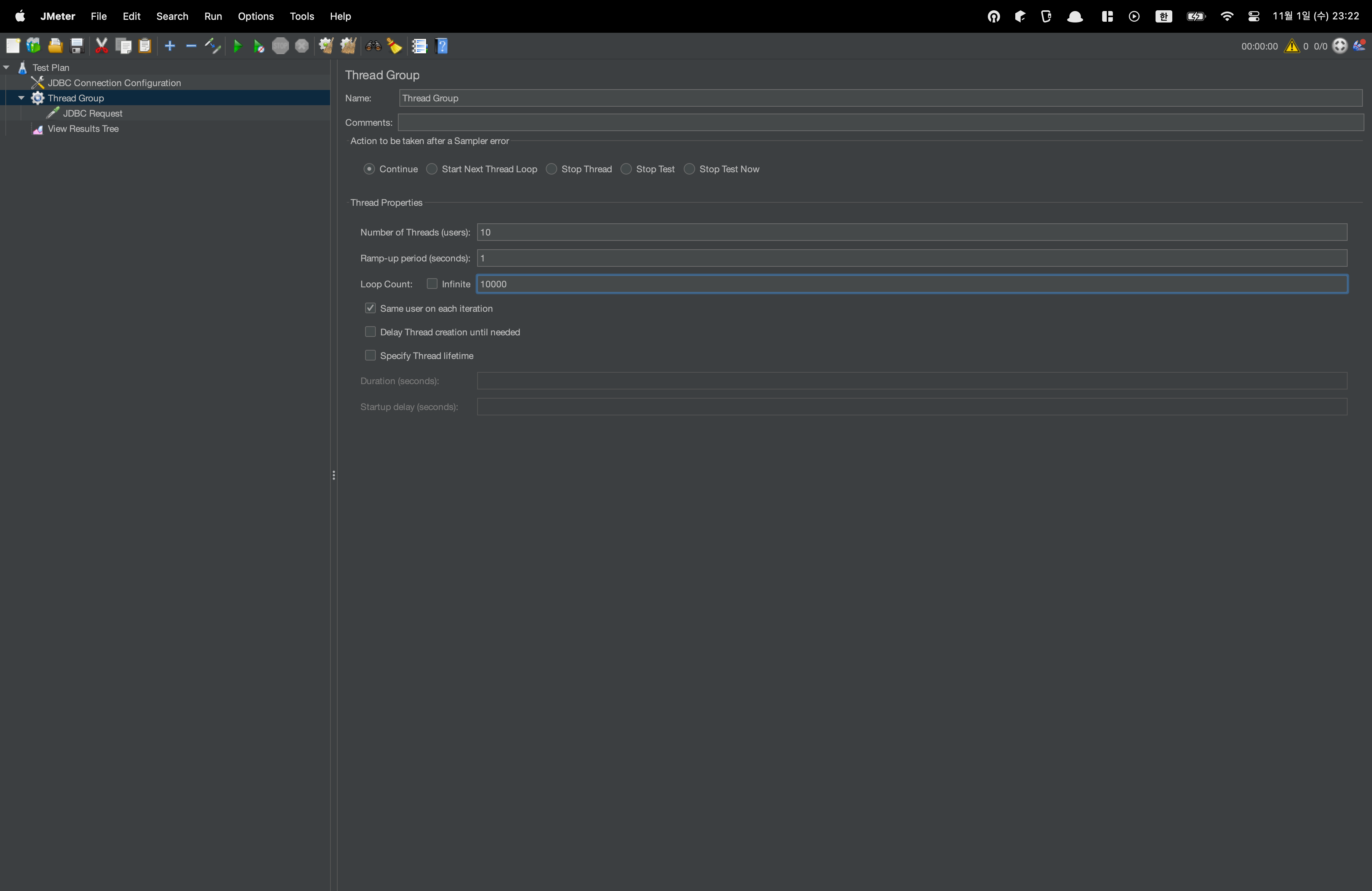
Thread Group 섹션으로 이동하여 쓰레드의 수를 조절합니다.
Number of Threads : 쓰레드 수
Ramp-up peiod : 쓰레드 주기(Loop Count) 가운데 대기 시간
Lood Count : 루프 횟수
현재 설정은, 10개의 쓰레드로 10,000번 반복하여 총 100,000개의 데이터를 채우는 것이 목표입니다.
위 테이블에 근거하면, PK가 100000까지 채워지는 것이 가장 이상적이지만, Failover 도중 유실되는 데이터를 고려하면 약 9만여개의 데이터가 채워질 것으로 예상됩니다.
Jmeter Start & Primary Node Shutdown
Jmeter 시작 후 테스트 도중 Primary 노드를 Down하여 Failover 시키겠습니다.
상단 재생 아이콘을 눌러 테스트를 시작합니다.
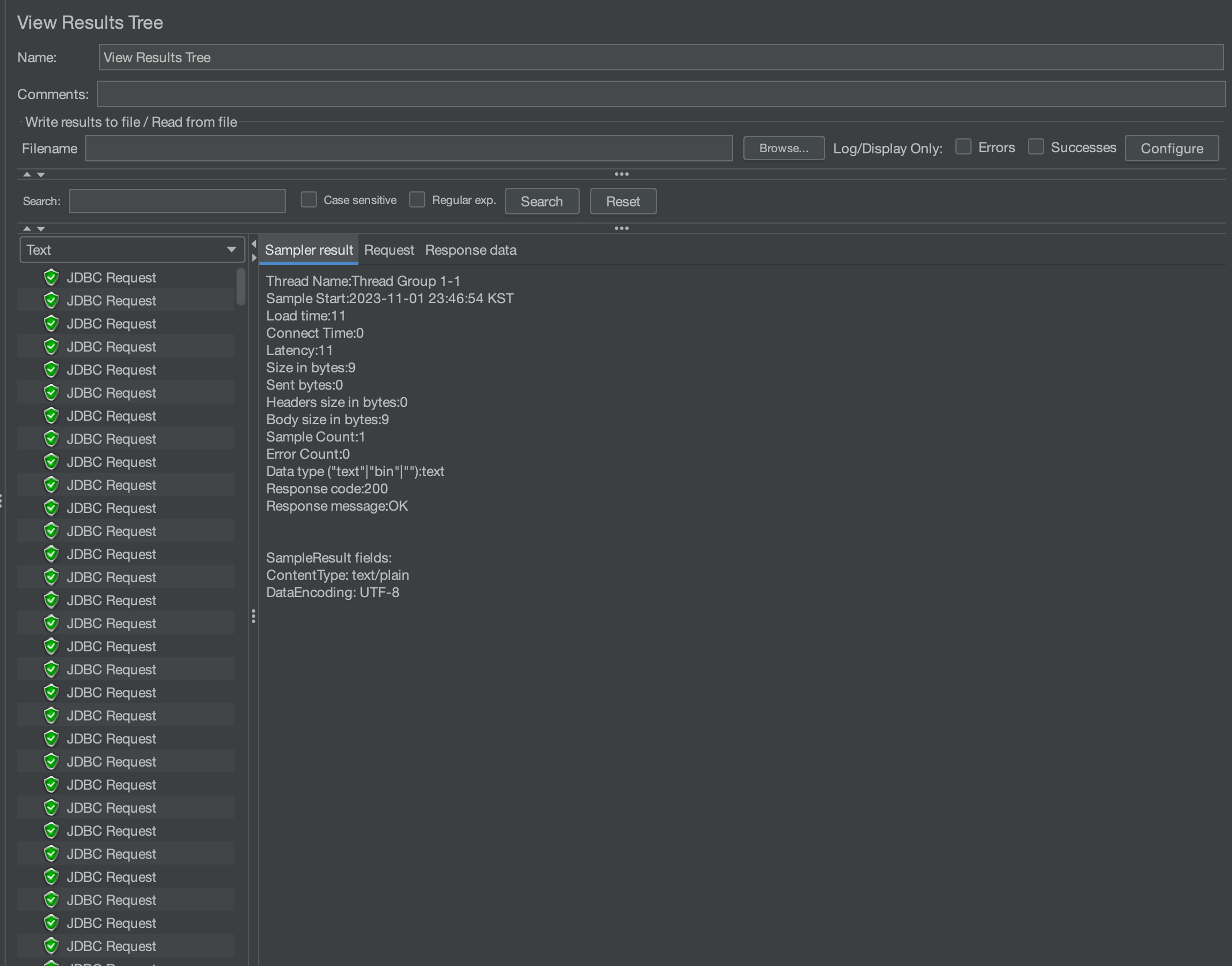
정상적으로 커넥션이 이루어졌음을 확인할 수 있습니다.
mysql> select max(id) from insert_test.tb_test;
+---------+
| max(id) |
+---------+
| 4012 |
+---------+
1 row in set (0.00 sec)약 4012개의 row가 들어갔을 시점에 Primary Node를 Shutdown 하겠습니다.

[root@vm2-1 ~]# /mysql/mysql/bin/mysqladmin -uroot -p shut -S /tmp/mysql_8.0.sock잠시 커넥션이 유실됨과 동시에, 곧바로 다시 커넥션이 연결됩니다.
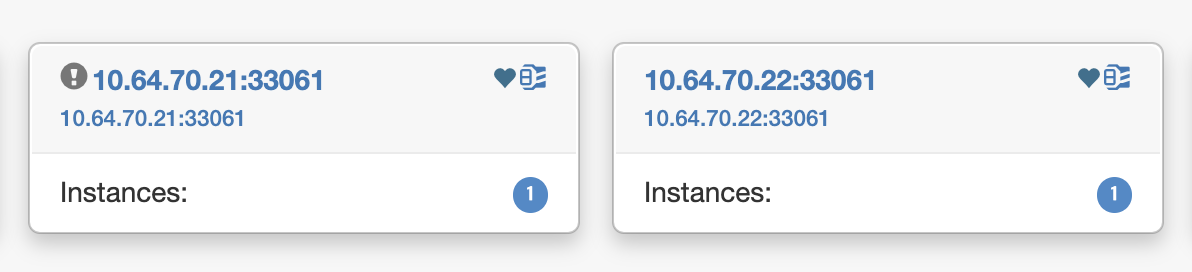
오케스트레이터는, 1번 Node와 2번 Node를 분리하였습니다.
[root@vm2-2 ~]# hostname -I
10.64.70.22 10.64.70.17 10.64.21.254 192.168.122.1또한, 정상적으로 2번 노드에 VIP (10.64.70.17) 플로팅 되었습니다.
테스트가 종료되었고, 테이블 데이터를 확인하겠습니다.
mysql> select * from tb_test where col1='vm2-1' order by id desc limit 5;
+------+-------+---------------------+
| id | col1 | time |
+------+-------+---------------------+
| 4206 | vm2-1 | 2023-11-01 10:45:15 |
| 4205 | vm2-1 | 2023-11-01 10:45:15 |
| 4204 | vm2-1 | 2023-11-01 10:45:15 |
| 4203 | vm2-1 | 2023-11-01 10:45:15 |
| 4202 | vm2-1 | 2023-11-01 10:45:15 |
+------+-------+---------------------+
5 rows in set (0.03 sec)
mysql> select max(id) from tb_test;
+---------+
| max(id) |
+---------+
| 91372 |
+---------+
1 row in set (0.00 sec)4202번 째 Row에서 Failover가 일어났으며, 100,000개 데이터 중 91,372개가 들어갔습니다.
약 8700개의 데이터 유실입니다.
해당 사항은, DB 서버의 스펙과 파라미터 설정, 네트워크 성능 등 여러가지 상황에 따라 달라집니다.
Recovery DeadMaster (Node1)
전 포스팅의 rejoin 방식을 이용하여 Node1을 복구하겠습니다.
MySQL localhost:33060+ ssl JS > rs = dba.getReplicaSet()
You are connected to a member of replicaset 'replicaSet'.
<ReplicaSet:replicaSet>
MySQL localhost:33060+ ssl JS > rs.status()
WARNING: Unable to connect to the PRIMARY of the ReplicaSet replicaSet: MYSQLSH 51118: Could not open connection to 'vm2-1:33061': Can't connect to MySQL server on 'vm2-1:33061' (111)
Cluster change operations will not be possible unless the PRIMARY can be reached.
If the PRIMARY is unavailable, you must either repair it or perform a forced failover.
See \help forcePrimaryInstance for more information.
{
"replicaSet": {
"name": "replicaSet",
"primary": "vm2-1:33061",
"status": "UNAVAILABLE",
"statusText": "PRIMARY instance is not available, but there is at least one SECONDARY that could be force-promoted.",
"topology": {
"vm2-1:33061": {
"address": "vm2-1:33061",
"connectError": "Could not open connection to 'vm2-1:33061': Can't connect to MySQL server on 'vm2-1:33061' (111)",
"fenced": null,
"instanceRole": "PRIMARY",
"mode": null,
"status": "UNREACHABLE"
},
"vm2-2:33061": {
"address": "vm2-2:33061",
"fenced": false,
"instanceErrors": [
"ERROR: Instance is NOT a PRIMARY but super_read_only option is OFF. Accidental updates to this instance are possible and will cause inconsistencies in the replicaset.",
"ERROR: Replication source channel is not configured, should be vm2-1:33061."
],
"instanceRole": "SECONDARY",
"mode": "R/W",
"replication": {
"applierStatus": null,
"expectedSource": "vm2-1:33061",
"receiverStatus": null,
"replicationSsl": null
},
"status": "ERROR",
"transactionSetConsistencyStatus": null
}
},
"type": "ASYNC"
}
}ReplicaSet 상태에서 전 포스팅과 같은 현상이 나옵니다. Orchestrator는 Failover 하였지만 Shell에서는 여전히 Node1번을 Primary로 인식합니다.
MySQL localhost:33060+ ssl JS > rs.forcePrimaryInstance('10.64.70.22:33061')
* Connecting to replicaset instances
** Connecting to vm2-2:33061
* Waiting for all received transactions to be applied
vm2-2:33061 will be promoted to PRIMARY of the replicaset and the former PRIMARY will be invalidated.
* Checking status of last known PRIMARY
NOTE: vm2-1:33061 is UNREACHABLE
* Checking status of promoted instance
NOTE: vm2-2:33061 has status ERROR
* Checking transaction set status
* Promoting vm2-2:33061 to a PRIMARY...
* Updating metadata...
vm2-2:33061 was force-promoted to PRIMARY.
NOTE: Former PRIMARY vm2-1:33061 is now invalidated and must be removed from the replicaset.
* Updating source of remaining SECONDARY instances
Failover finished successfully.
MySQL localhost:33060+ ssl JS > rs.status()
{
"replicaSet": {
"name": "replicaSet",
"primary": "vm2-2:33061",
"status": "AVAILABLE_PARTIAL",
"statusText": "The PRIMARY instance is available, but one or more SECONDARY instances are not.",
"topology": {
"vm2-1:33061": {
"address": "vm2-1:33061",
"connectError": "Could not open connection to 'vm2-1:33061': Can't connect to MySQL server on 'vm2-1:33061' (111)",
"fenced": null,
"instanceRole": null,
"mode": null,
"status": "INVALIDATED"
},
"vm2-2:33061": {
"address": "vm2-2:33061",
"instanceRole": "PRIMARY",
"mode": "R/W",
"status": "ONLINE"
}
},
"type": "ASYNC"
}
}forcePrimaryInstance() 옵션을 사용하여 강제적으로 Node2번을 Primary로 만듭니다.
[root@vm2-1 ~]# mysqld_safe --defaults-file=/etc/my.cnf_8.0 --user=mysql &
[1] 309410
[root@vm2-1 ~]#
[root@vm2-1 ~]# mysqld_safe Adding '/mysql/Percona-Server-8.0.34-26-Linux.x86_64.glibc2.17/lib/mysql/libjemalloc.so.1' to LD_PRELOAD for mysqld
2023-11-01T15:03:35.220831Z mysqld_safe Logging to '/mysql/mysql_log/mysql.err'.
2023-11-01T15:03:35.241843Z mysqld_safe Starting mysqld daemon with databases from /mysql/mysql_dataNode1번 DB를 기동 후, rejoinInstance()를 사용하여 증분 복구합니다.
여기서, 풀 복구가 아닌 증분 복구를 사용해 데이터를 복구할 수 있습니다.
MySQL localhost:33060+ ssl JS > rs.rejoinInstance('10.64.70.21:33061')
* Validating instance...
This instance reports its own address as vm2-1:33061
vm2-1:33061: Instance configuration is suitable.
** Checking transaction state of the instance...
The safest and most convenient way to provision a new instance is through automatic clone provisioning, which will completely overwrite the state of 'vm2-1:33061' with a physical snapshot from an existing replicaset member. To use this method by default, set the 'recoveryMethod' option to 'clone'.
WARNING: It should be safe to rely on replication to incrementally recover the state of the new instance if you are sure all updates ever executed in the replicaset were done with GTIDs enabled, there are no purged transactions and the new instance contains the same GTID set as the replicaset or a subset of it. To use this method by default, set the 'recoveryMethod' option to 'incremental'.
Incremental state recovery was selected because it seems to be safely usable.
* Rejoining instance to replicaset...
** Changing replication source of vm2-1:33061 to vm2-2:33061
** Checking replication channel status...
** Waiting for rejoined instance to synchronize with PRIMARY...
** Transactions replicated ##========================================================== 4%Incremental state recovery가 선택되었고, 진행중입니다.
MySQL localhost:33060+ ssl JS > rs.rejoinInstance('10.64.70.21:33061')
* Validating instance...
This instance reports its own address as vm2-1:33061
vm2-1:33061: Instance configuration is suitable.
** Checking transaction state of the instance...
The safest and most convenient way to provision a new instance is through automatic clone provisioning, which will completely overwrite the state of 'vm2-1:33061' with a physical snapshot from an existing replicaset member. To use this method by default, set the 'recoveryMethod' option to 'clone'.
WARNING: It should be safe to rely on replication to incrementally recover the state of the new instance if you are sure all updates ever executed in the replicaset were done with GTIDs enabled, there are no purged transactions and the new instance contains the same GTID set as the replicaset or a subset of it. To use this method by default, set the 'recoveryMethod' option to 'incremental'.
Incremental state recovery was selected because it seems to be safely usable.
* Rejoining instance to replicaset...
** Changing replication source of vm2-1:33061 to vm2-2:33061
** Checking replication channel status...
** Waiting for rejoined instance to synchronize with PRIMARY...
** Transactions replicated ############################################################ 100%
* Updating the Metadata...
The instance 'vm2-1:33061' rejoined the replicaset and is replicating from vm2-2:33061.
MySQL localhost:33060+ ssl JS > rs.status()
{
"replicaSet": {
"name": "replicaSet",
"primary": "vm2-2:33061",
"status": "AVAILABLE",
"statusText": "All instances available.",
"topology": {
"vm2-1:33061": {
"address": "vm2-1:33061",
"instanceRole": "SECONDARY",
"mode": "R/O",
"replication": {
"applierStatus": "APPLIED_ALL",
"applierThreadState": "Waiting for an event from Coordinator",
"applierWorkerThreads": 4,
"receiverStatus": "ON",
"receiverThreadState": "Waiting for source to send event",
"replicationLag": null,
"replicationSsl": "ECDHE-RSA-AES128-GCM-SHA256 TLSv1.2"
},
"status": "ONLINE"
},
"vm2-2:33061": {
"address": "vm2-2:33061",
"instanceRole": "PRIMARY",
"mode": "R/W",
"status": "ONLINE"
}
},
"type": "ASYNC"
}
}정상적으로 복구되었고, Node1번의 테스트 테이블 로우 수를 확인하겠습니다.
MySQL localhost:33060+ ssl JS > \connect test@10.64.70.21:33061
Creating a session to 'test@10.64.70.21:33061'
Please provide the password for 'test@10.64.70.21:33061': ***
Save password for 'test@10.64.70.21:33061'? [Y]es/[N]o/Ne[v]er (default No): y
Fetching schema names for auto-completion... Press ^C to stop.
Closing old connection...
Your MySQL connection id is 38
Server version: 8.0.34-26 Percona Server (GPL), Release 26, Revision 0fe62c85
No default schema selected; type \use <schema> to set one.
MySQL 10.64.70.21:33061 ssl JS > \sql
Switching to SQL mode... Commands end with ;
Fetching global names for auto-completion... Press ^C to stop.
MySQL 10.64.70.21:33061 ssl SQL > SELECT MAX(id) FROM insert_test.tb_test;
+---------+
| MAX(id) |
+---------+
| 91372 |
+---------+
1 row in set (0.0007 sec)
MySQL 10.64.70.21:33061 ssl SQL > select * from insert_test.tb_test where col1='vm2-1' order by id desc limit 5;
+------+-------+---------------------+
| id | col1 | time |
+------+-------+---------------------+
| 4206 | vm2-1 | 2023-11-01 10:45:15 |
| 4205 | vm2-1 | 2023-11-01 10:45:15 |
| 4204 | vm2-1 | 2023-11-01 10:45:15 |
| 4203 | vm2-1 | 2023-11-01 10:45:15 |
| 4202 | vm2-1 | 2023-11-01 10:45:15 |
+------+-------+---------------------+
5 rows in set (0.0303 sec)2번 노드와 동일하게 91,372개, 그리고 동일한 시점에서 Failover 시점을 확인할 수 있습니다.
Orchestrator Setting
해당 시나리오를 구현하려면, Orchestrator의 약간의 파라미터 추가가 필요합니다.
테스트 결과, Orchestrator는 기본적으로 Failover가 되었을 경우 Secondary의 지연(Replicaion_lag)을 기다려주지 않고 바로 Failover 합니다.
그렇게 된다면, Slave가 Relay Log에서 받아온 데이터를 모두 Commit하여 디스크에 쓰지 않은 채 아래 과정을 수행합니다.
- STOP REPLICA;
- RESET REPLICA ALL;
해당 시점에서 반영된 데이터들은 모두 유실되며, 결국 Failover 후 두 노드의 데이터는 차이가 나게 됩니다.
Orchestrator의 하단 JSON 셋에서 아래 파라미터를 추가합니다.
"GraphiteConvertHostnameDotsToUnderscores": true,
"ConsulAddress": "",
"ConsulAclToken": "",
"ConsulKVStoreProvider": "consul",
...
...
"DelayMasterPromotionIfSQLThreadNotUpToDate": true
}"DelayMasterPromotionIfSQLThreadNotUpToDate" 옵션은 지연된 Secondary가 있을 경우 이것을 기다린 후 Failover를 진행합니다. 현재 시나리오 처럼 2Node 이상의 ReplicaSet일 경우 지연 처리를 가장 먼저 끝내거나, 지연이 없는 Secondary로 Failover 합니다.
다음 포스팅은 Percona for MySQL을 사용하여 InnoDB Cluster 구축을 포스팅 하도록 하겠습니다.
