[Diffusion] LDM 논문 리뷰: High-Resolution Image Synthesis with Latent Diffusion Models
Diffusion
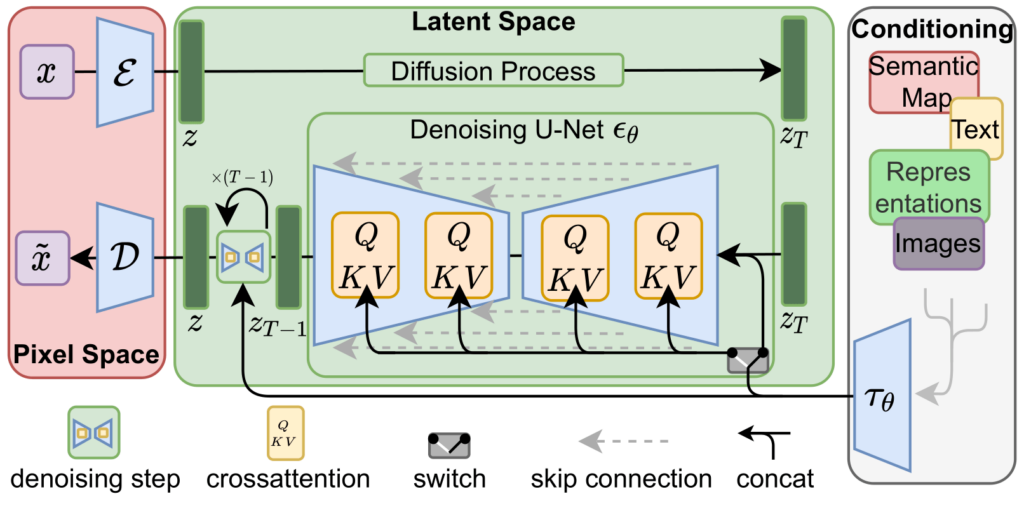
Stable Diffusion에서 사용한 모델들의 백본구조로 활용된 모델에 대한 2022년 논문
논문: https://arxiv.org/abs/2112.10752
깃헙: https://github.com/CompVis/latent-diffusion
핵심 요약
-
Latent Space 에서 학습
기존 Diffusion Models는 픽셀 공간에서 직접 동작하기 때문에 훈련이 비싸다
이를 해결하기 위해 사전 학습된 오토인코더의 latent space에서 학습.
복잡도 감소와 디테일 유지 사이의 최적 지점 달성 -
Cross-Attention Layer
텍스트, 바운딩 박스 등 다양한 조건을 활용한 유연한 이미지 생성 가능 -
LDMs의 성과:
- Image inpainting 및 class-conditional image synthesis에서 새로운 state-of-the-art 점수 달성
- Text-to-image synthesis, unconditional image generation, super-resolution 등 다양한 task에서 뛰어난 성능
- Pixel-based DM에 비해 계산 요구 사항을 크게 감소
기술 개요
Perceptual Image Compression
즉 autoencoder 활용해 latent space로 압축 때려버렸다는 것
선행연구: VQ-GAN
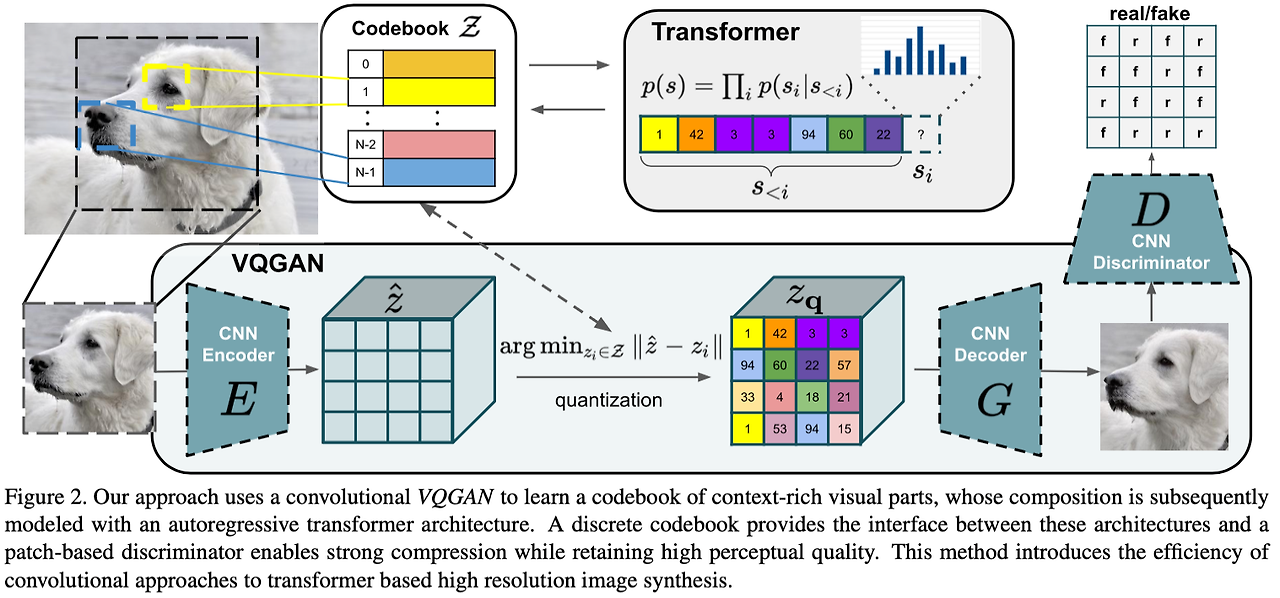
논문에서는 선행 연구로 Taming Transformers for High-Resolution Image Synthesis 를 언급한다.
선행연구 내용 간단 요약
1) VQ-VAE와 같은 방식으로 quantization 후 코드북을 짜는 형태로 시퀀스를 만들고 이걸 Transformer에 태우는 방식으로 pixel 공간 정보를 압축하여 학습했다. (꼬꼬무가 될까봐 제가 아는 내용은 좀 스킵을 하겠읍니다...)
2) 단순히 L1, L2 loss를 사용하는게 아니라 perceptual loss와 patch-based adversarial loss를 결합하여 활용 (요건 제가 CV 알못이라 좀더 자세히)
- L1, L2 Loss와 같은 픽셀 차이값 단순하게 계산하는 loss는 인간의 고차원 적인 인지를 (여기서도 이게 나오는구나..) 제대로 반영하지 못하고, 평균적인 값에 근사하다보니 블러 현상도 많이 발생
- 사전에 학습된 VGG 같은 CNN 모델의 중간 레이어 feature map을 loss function에 활용하여 생성된 고수준 feature가 원본의 것과 유사하게 만드는 것이 perceptual objective
- adversarial loss는 GAN 쓴다 이건데 이걸 픽셀단위에 적용한게 아니라 픽셀 몇개의 집합체인 patch 단위로 적용을 하여 활용한다는 것이다.
LDM에서는 위에서 언급된 loss들을 거의 그대로 활용해서 autoencoder가 효과적인 latent space를 구성할 수 있도록 학습시켰다.
추가로 latent space가 너무 큰 분산을 가지지 않게 하기 위해 다음 regularization 기법을 활용했다.
1) KL-reg.
VAE 처럼 latent vector가 Gaussian에 근접할 수 있는 형태가 되도록 KL penalty를 한꼬집 넣어줬다. 사실상 VAE 근데 kld 항이 겁나 작아 autoencoder처럼 활용되는
2) VQ-reg.
디코더에 VQ layer를 넣어줬다. 인코더는 아니구
암튼 이렇게 하면 latent space에서 개판으로 구성되어 있을 수 있는 벡터들을 정돈된 코드북 벡터로 디코딩하여 안정적인 결과를 얻을 수 있다.
또 기존 연구에서 압축 자체는 좋았지만 1D 형태로 하다보니 구조 정보를 완벽하게 반영할 수 없었는데 우리는 2D다 라고 자랑하고 있다.
Latent Diffusion Models
논문에서는 이렇게 잠재 공간으로 넘겨진 애들이 likelihood 기반 모델에 더 적합하다고 주장한다.
- 데이터의 중요한 의미적 정보(semantic bits)에 집중할 수 있음.
- 더 낮은 차원의 공간에서 학습이 가능하여, 연산 효율성이 크게 향상됨.
또한 2D로 다루다보니
- 2D Conv layer를 활용한 Unet 구조
- 경계 설정을 통해 perceptually relevant bits 에 더 집중
을 통해 이미지에 최적화된 inductive bias를 활용할 수 있게 된다고도 한다.
논문에서 내민 식은 아래와 같은데,
사실상 기존에 확률변수 를 활용해 의 노이즈에 대한 기댓값 계산이 아니라 Encoder를 통과해 변환된 잠재 벡터를 활용해 의 노이즈에 대한 기댓값 계산이 되었다는게 전부다.
는 DDPM과 같이 time-conditional Unet으로 구현되었다.
Conditioning Mechanisms
LDM에서의 또다른 임팩트있는 기여는 conditional한 생성을 도울수 있도록 cross attention 을 추가해서 conditioning이 유연하게 이루어질 수 있도록 하였다는 것이다.
다양한 모달리티의 입력 에 대해 이를 인코더 가 로 변환하여 cross attention이 이걸 Unet 중간층에 매핑하게 하는 것이다.
어텐션 수식은 위에서처럼 표현될 수 있다. 는 Unet 중간층 표현인거고
는 learnable projection matrices
그래서 conditioning 주는 LDM의 학습은 아래처럼 표현될 수 있다.
실험 결과
뭐 ablation 성능비교 이런건 그냥 패스하구... conditioning 학습을 어떻게 활용할 수 있을 지 봐보자
모 당연히 transformer encoder를 써서 text-to-image 할 수 있는거고, class conditioning으로는 SOTA

저화질 이미지를 condition으로 줘서 super resolution을 수행할 수 있다.

빵꾸난 사진을 활용해서 inpainting도 할 수 있다.
얘도 FID에서 SOTA score
이후에는 Stable Diffusion 3 연구 논문을 봐보겠다. 구성요소 MMDiT, RF 까지도 다 다시 볼지 하나로 퉁칠지.. 고민중
