[Diffusion] Stable Diffusion 3 논문 리뷰: Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Diffusion

LDM 의 전반적인 컨셉 자체는 좋아하는데, 논문 자체에 활용된 기술들이 꽤 오래됐다보니 실질적으로 적용하기엔 까다롭다. 아니 2022년 논문이었는데 시간도 빠르지만 기술도 너무 빠르다. 카티 앨범이 2020이었는데 음악보다 트렌드가 빠르다 미친
암튼 기존 LDM 형태에 더 팬시한 디노이징 방식과 diffusion process와 생성방식이 적용된 Stable Diffusion 3 입니다.
논문: https://stability.ai/news/stable-diffusion-3-research-paper
huggingface: https://huggingface.co/stabilityai/stable-diffusion-3-medium-diffusers
코드가 공식적으로 제공되지는 않고 hf 라이브러리에 diffusers에 파이프라인과 모델 아키텍쳐 소스코드 자체는 포함되어 있는데 여기저기 퍼져있어서 일단 스킵,,
핵심 요약
-
Recitified Flow 학습을 위해 perceptually relevant scales에 맞춰 샘플링 편향이 될 수 있도록 샘플링 방식을 개선
(대충 rectified flow 좀 개선한 버전의 flow model 쓴다)
recified flow 와 flow matching은 언젠가 또 다뤄보겠습니다.. -
텍스트-이미지 생성에 Transformer 기반 아키텍쳐 제안
-
텍스트와 이미지 모달리티에 각각 별도 가중치 적용.
-
텍스트와 이미지 토큰간 양방향 정보 흐름을 만듦.
-
-
이 모델이 스케일링 법칙을 따르는 것도 확인했고, val loss가 실제 성능과도 연관있는 것을 확인했다. 다른 SOTA들 개팼다
기술 개요
Simulation-Free Training of Flows
simulation-free 란 옛날 DDPM 스타일의 SDE 기반 샘플링을 수행하지 않는다는 것이다. 이건 Flow Matching 개념을 참조..
암튼 논문에서는 Flow Matching 모델의 기본 개념들을 설명해주고, 선행 논문들에서 다루어진 관련 수식들을 정리해주고 있다.
앞으로의 설명에 필요한 수식만 쓰면서 설명하자면,
forward process:
CFM Loss를 noise 예측 형태로 쓰면:
CFM Loss 일반화:
여기서
중간중간 정의가 설명되지 않는게 많은데 그냥 다 쓰면 복붙이 되니 논문을 참고..
암튼 결국 Flow Matching 모델 자체는 기존 diffusion model의 noise 예측에 weight가 가해진 형태로 학습이 이루어지는 것이 식을 통해 표현된다.
Flow Trajectories
Flow Model은 결국 적절하고 학습에 효율적인 probability path를 찾는것이 중요하고, 논문에서는 이 probability path를 찾는 기묘한 모험들을 줄줄 나열하고 있다. 결국 사용한건 recified flow라니까 RF만 보자면
Gaussian과 데이터 분포를 직선으로 이은 형태의 probability path를 가지며 forward process를 다음과 같이 표현한다:
이건 의 CFM Loss를 쓴다.
근데 또 이 친구는 직선연결이기 때문에 노이즈 예측 방식으로 학습하는게 아니라 velocity 를 학습하는 형태로 되어야한다.
암튼 에 대해서는 시간에 대해 uniform 하게 학습이 이루어지는데, SDE 기반이 아닌 문제로 바꾸어 이렇게 만들다보니 t=0이나 t=1에 근접하지 않은 이상 중간과정에서의 샘플링 난이도가 훨씬 올라가게 된다.
요걸 해결해주기 위해 우선적으로 목표를 다음과 같이 설정한다:
timestep에 걸친 분포를 균일분포인 가 아니라 로 바꾸고, 이 가 학습 중간스텝에 더 많은 가중치를 줄 수 있도록 한다. 즉 다음 를 loss의 weight으로 쓴다.
그 방법은... 좀 끄적여보다가 좀 노잼이라 그냥 logit-normal distribution을 활용한다 정도로 정리하고 그림 틱 올려놓겠습니다...
과 를 건드려서 분포 형태를 조절해 줄 수 있다는 거에요..
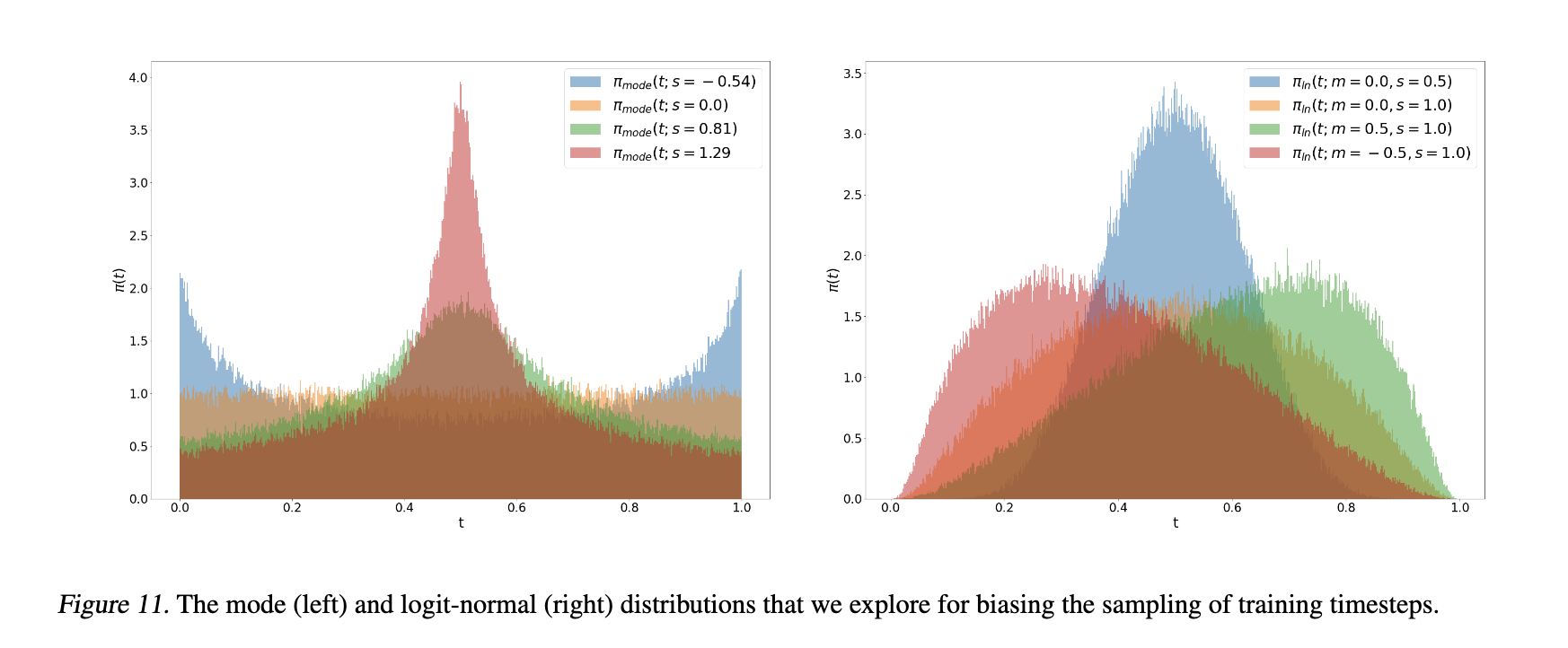
그리고 time step sampling (본문에서는 cosine schedule, 실험에서는 여러가지 방법들도 사용)
Text-to-Image Architecture
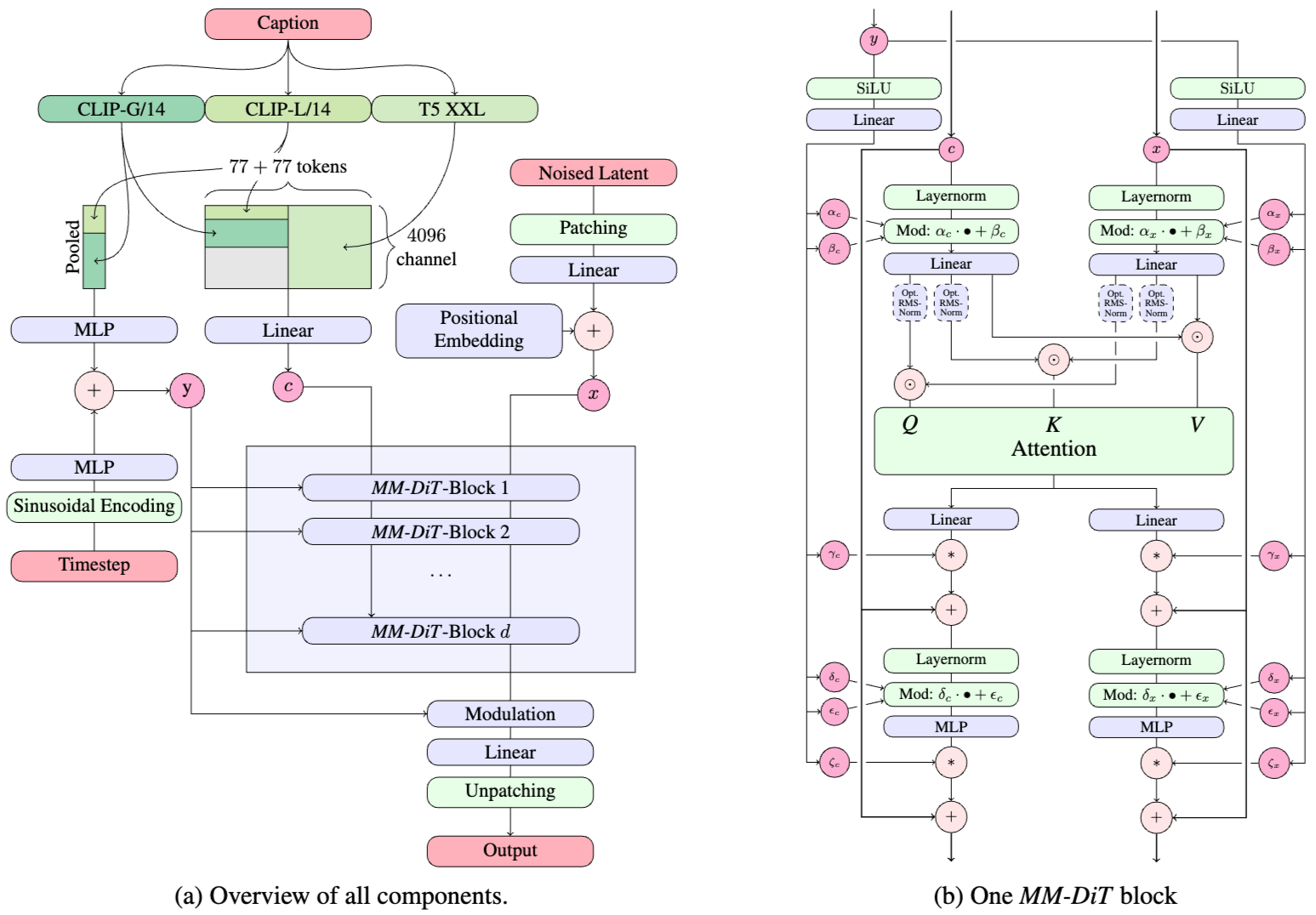
ae로 latent vector 만들고 그 공간에서 diffusion task 수행하는 것 자체는 기존 LDM 형태를 따른다.
text conditioning을 frozen LM에서 인코딩 하는 방식은 선행 연구 Palette, eDiff-I (안읽어봄ㅎ) 의 형태를 따랐다구 한다.
그림에 나온거처럼 CLIP-G/14, CLIP-L/14, T5 XXL 모델들의 인코딩 결과를 이래저래 짤라붙여서 필요한 conditioning vector들을 구성했다.
약간 더 구체적으로, CLIP 모델 두개에서 나온 pooled output을 이어 붙여서 을 만들었고 이건 기존 DiT 에서 활용한것과 같은 형태라고 한다. 다만, CLIP에서 압축된 표현만 사용하기엔 좀 모잘라서 T5 인코더까지 빨아서 도 만들었다고 한다.
형태의 latent representation에는 패치를 적용해 의 시퀀스를 만든다.
이 두개가 결국 실제 reverse process가 수행될 MM-DiT 블록을 통과하는데, 여기서 attention만 합쳐서 계산하고 weight set도 따로 쓰고 modulation 연산도 별도로 적용을 한다. text와 image 임베딩은 본질적으로 다르기 때문이다.
실험 결과
실제 써먹을 때 활용할 팁같은게 좀 많은거같아 평소보단 구체적으로 정리..
RF + logit-normal ablation
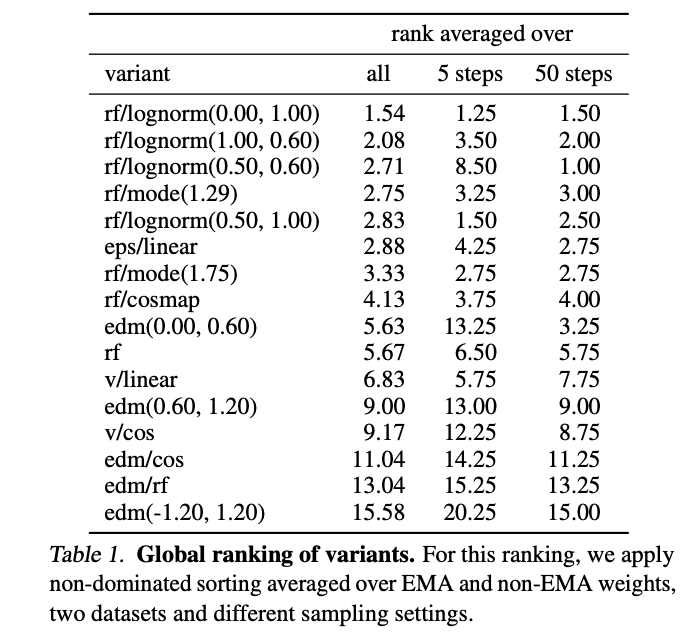
진짜 토악질나오게 열심히 뒤져봤구나 싶음..
논문 본문에서도 RF 뿐만 아니라 다양한 trajectory에 대한 설명도 잘 나와있음
Improved Autoencoders

VAE 잠재 채널 수를 늘렸더니 recontruction 성능이 올랐따
MM-DiT
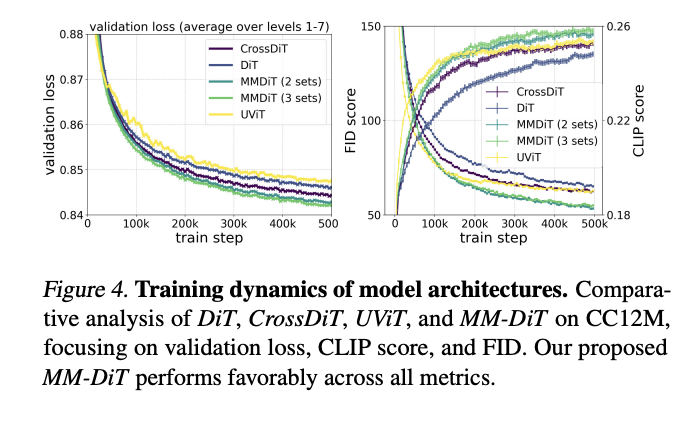
일단 다른애들을 개팼다
여기서 2set은 논문에 설명된대로 이미지 latent랑 condition 인코더에서 온 벡터들 투세트로 분리해서 학습한거 말하는거고, 3set은 CLIP 이랑 T5에서 온 얘들까지 찢어서 분리한거라고 한다.
3set이 쪼꼼 더 좋아보이는 부분도 있지만 연산량이 늘어나는거에 비해 미미해서 2set 기준으로 썼다고 한다.
QK-Normaliztion
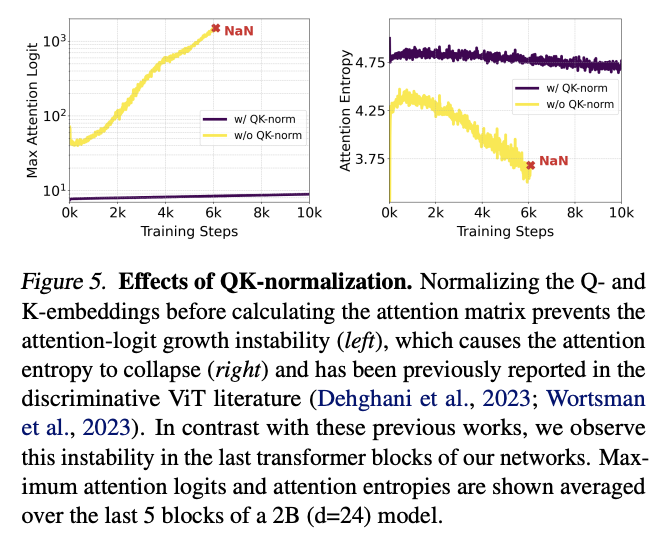
보통 학습할때 256^2 의 저해상도에서 pretrain 후 고해상도 이미지를 학습하는데, 고해상도에서 mixed-precision 으로 훈련하는게 불안정해지고 loss가 발산해버리는 현상이 나타났다. 그렇다고 차마 full-precision을 쓸수는 없어 (실제로 성능 반갈죽 당했다고 함) 다른 선행 연구를 참고하였다. 선행 연구에서는 large ViT가 발산하는게 attention entropy가 폭발해버리기 때문임을 보았고, 이에 따라 attention 계산 전에 Q, K 값을 정규화 때려버려서 해결하였다. 그래서 요걸 따라서 RMS Norm을 추가하였다. MM-DiT 블록 그림내 Opt. RMS-Norm이라고 써진게 그거다.
Positional Encodings for Varying Aspect Ratios
PE를 쓰는데 다양한 종횡비나 resolution에 따라서 이게 뒤죽박죽 될수 있으니 보정하는 내용을 절절히 쓰고 있는데
음 실제로 계산도 제대로 때려서 쉽게 돌릴수 있는지 알아봐야 하고 또 실제로 몰라서 안했을리는 없을테니 궁금한건데 RPE 쓰면 많이 해결되는게 아닐까 싶었다
Resolution-dependent shifting of timestep schedules
해상도가 높으면 메꿔야되는 noise가 많아지기 때문에 해상도에 따라 타임스텝 변환이 다른 느낌으로 가야한다. 아무튼 계산 요래요래 해갖구 해상도 포함해서 타임스텝 변환 공식을 만들었고 그걸 적용했다. 추가로 DPO 통해서 추가 정렬도 진행했다.
