[ASR study] Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
introduction
TTS기술이 발전하면서 DNN이 많이 쓰이고 있는데 TTS는 보통 2단계로 나누어져있다. 1.mel spectrogram 생성 , 2.raw waveform 생성. 이 두 단계가 독립적으로 행해진다.
기존의 있던 TTS의 sequential한 방식은 parallel을 어렵게 한다. 합성 속도를 빠르게 하기 위해 non autoregressive 방법이 사용되었다. PT autoregressive model의 attention map을 사용한 방법도 있고, mel spectrogram의 likelyhood를 추정한 방법도 있다. raw waveform 생성에서 GAN을 사용한 HIFI GAN도 있다.
2stage 훈련은 sequential하며 시간과 비용이 상대적으로 많이 든다. 한 단계에서 학습되면 다시 학습해야해서 어렵다.
Fastspeech 2s는 전체 waveform이 아니라 short audio clip을 훈련해왔다. 또 mel spectrogram 디코더를 text representation과 결부하여 성능을 향상했지만, 그 합성 퀄리티는 2단계를 거쳐서 나타난다.
우리는 parallel 한 end to end 를 제안한다. latent variable을 통한 end to end model을 나타낸다. 우리는 이를 위해
1.normalizing flow to conditional prior와
2.adversarial training을 수행한다.
또한 다양한 음의 생성을 위해 stochastic duration predictor를 수행한다.
method
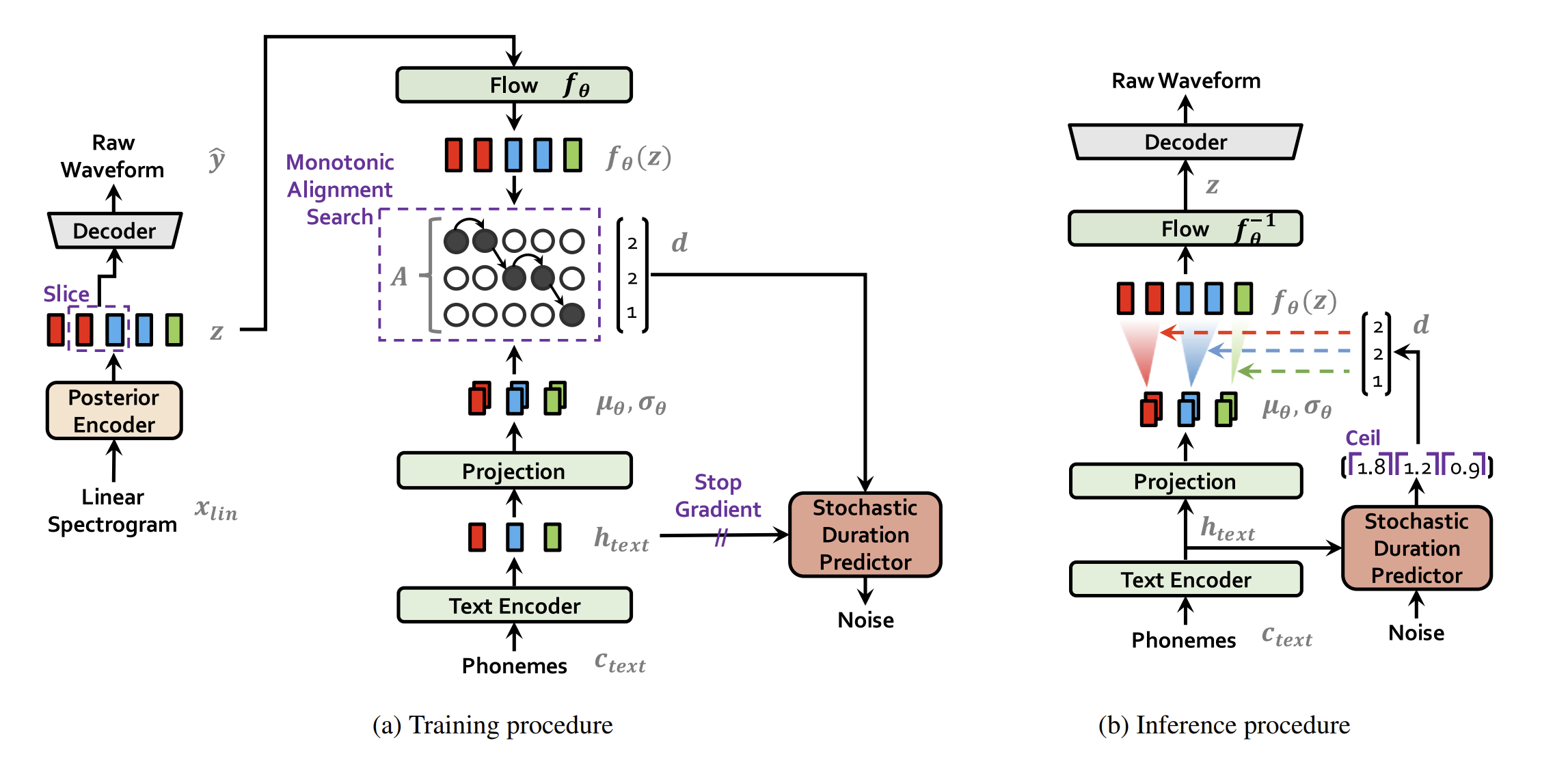
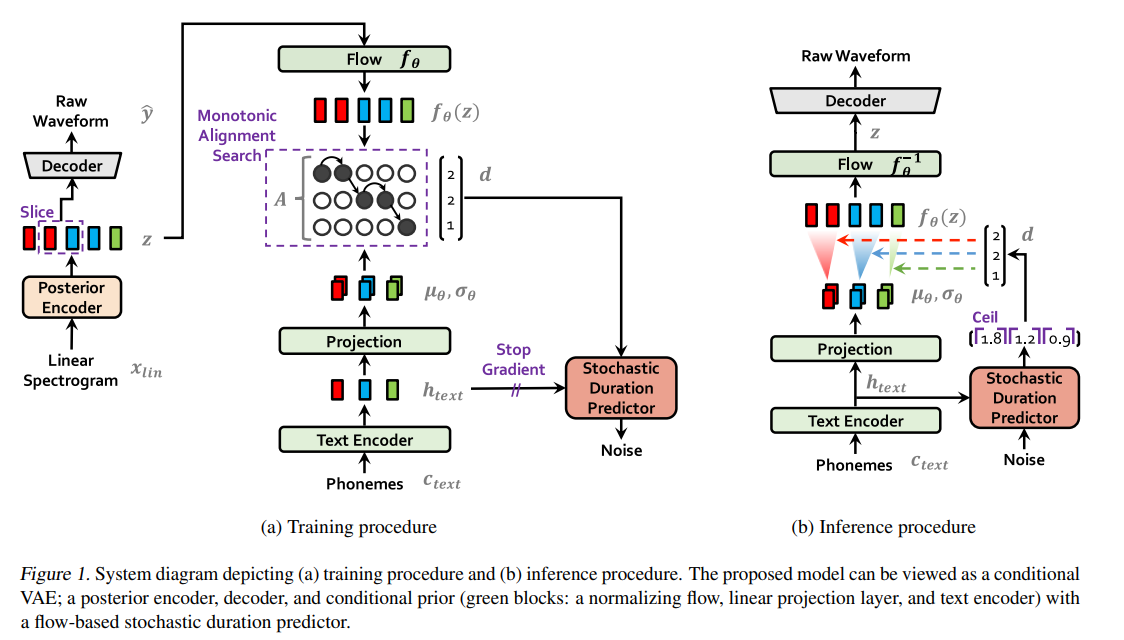
method는 크게 3가지로 나뉘어져 있다
1.conditional VAE formulation
2.alignment estimation
3.adversarial training
우리의 method를 VITS라고 부른다. (variational inference with adversarial learning for end to end tts)
variational inference
overview
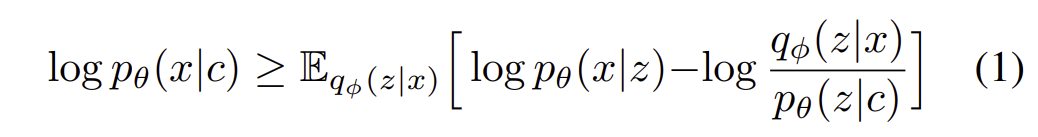
(본래 VAE는 조건화 c가 없는 식)
c에 조건화된 x에 대한 분포 p(x|c)는 VAE식에 따라서 lower bound로 나타낼 수 있다.
p(z|c) - c에 조건화된 latent의 prior, 여기서 조건화에 대한 prior latent는 미리 정해짐
p(x|z) - 데이터 x의 likelyhood (디코더에서 생성되는 거니까 latent로부터의 데이터 x 분포)
q(z|x) - 데이터 x로부터 z의 근사 posterior (x로부터 z를 근사하게 해야하는 encoder)
condition c가 있을 때 데이터 x의 확률을 높히는 것이 목표이다.
이를 극대화 하기 위해서는 ELBO에 해당하는 2가지 항을 높여야 한다.
이는 2가지를 동시에 학습한다.
1.reconstruction loss - prior z로부터의 gen x 나올 확률 증가
2.KL divergence - encoder의 latent가 prior에 근사하도록 KL
reconstruction loss
reconstruction 으로는 raw wave 대신에 mel-spectogram을 사용한다.
우리는 latent z로부터 waveform y로 upsample하고 이로부터 mel-spectogram x_로 변환한다.
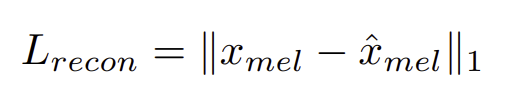
mel-spectogram은 인간의 청각 인지를 반영한 것인지라 이를 모사하도록 loss를 구성한다.
실제 x_mel을 생성하기 위한 decoder의 input으로는 latent z를 사용하지 않고 partial sequence를 generator의 input으로 사용한다. (for efficient training)
(그림을 보니 하나의 latent가 아니라 sequential 한 latent를 조건화하는 듯 하다)
ref:
{Fast and High-Quality End-to-End Text to Speech.}
{End-to-end Adversarial Text-to-Speech}
KL-divergence
input condition c는 phonemes c_text와 alignment A (phonemes and latent variable) 로 이루어져 있다.
따라서 alignment를 위해 hard-monotonic attention을 사용하는데
이를 위해 미리 |c_text|(phonemes) x |z| 의 latent matrix를 사용한다.
(이 phonemes의 latent에 대한 논의는 다음 챕터에서 논의한다)
보다 high resolution한 분포를 따르기 위해 x_lin은 mel-spectogram보다는 linear-spectogram을 사용한다.
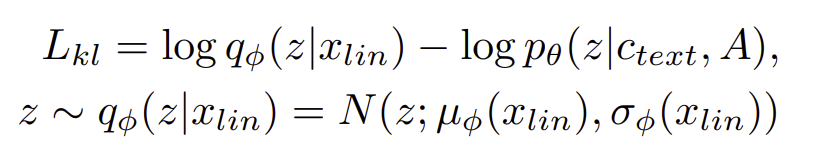
우리는 prior distribution의 expressiveness를 증가시키는게 중요하다는 것을 발견했다. 그래서 우리는 normalizing flow f_0를 하는데 이는 simple distribution을 more complex distribution으로 변경해주는 것이다.
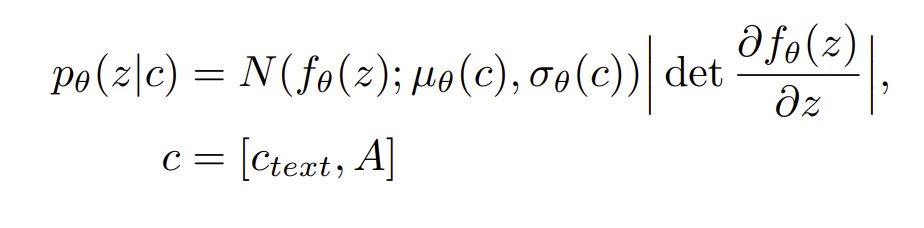
alignment estimation
monotonic alignment search
input text와 speech의 alignment를 찾기 위해 MAS algorithm을 사용한다.
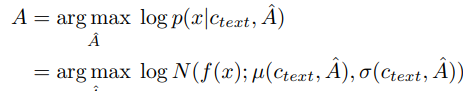
MAS란??
MAS는 2020 카카오에서 나온 glow-TTS에서 나온 기법으로, mel-spectogram 기반 align을 추정하는데 있어 병렬이 아닌 순차적인 방법으로 추론 하는 것을 말한다. CTC와 유사하다.
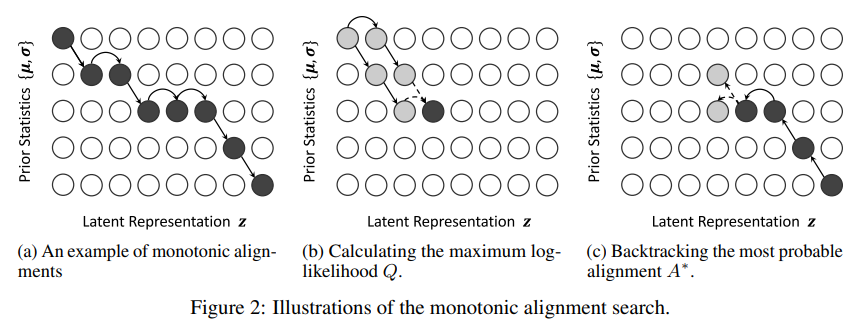
여러 timestep에서 거쳐 a에서 c로 이동할 때, 이전 단계를 고려하여 다음 단계를 추론하는 DP방식을 사용한다.
MAS에 대한 코드는 다음과 같다.

A가 전개되는 방식은 monotonic(A에서 C로 점점 이동하는)하며 not skippable하다. 본래 MAS는 dynamic하게 하지만, 우리는 목적함수가 ELBO이기에 그에 맞게 식을 redefine한다.
우리는 ELBO maximize하는 MAS redefine한다.
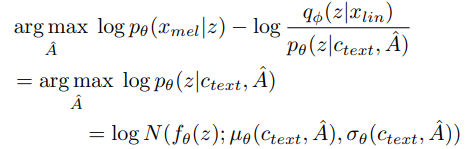
결국 동일하게 되므로 고칠 식이 없다.
duration prediction from text
그렇게 MAS로 각 토큰의 구간을 추정한다면 , duration을 구할 수 있다. 이때 duration을 예측하게 할 때 사람과도 같은 소리를 내기 위해서 랜덤한 요소를 넣는 값을 추정하도록한다.
stochatic duration predictor는 MLE이다. 하지만 이에 대해 MLE하는게 너무 어렵다. 이는 인풋이 다음과 같기 때문 :
1.discrete integer가 소수화 되어야 하는 것
2.scalar
이를 위해서 variational dequantization , variational data augmentation을 한다.
두 랜덤 변수가 있다. u ,v.
이는 동일한 resolution과 dimension을 갖고 있다.
u ~ [0,1] 을 따른다
그럼 d-u는 양의 실수 이다.
그리고 v와 d를 channel-wise하게 concat해 더 깊은 representation으로 만든다.
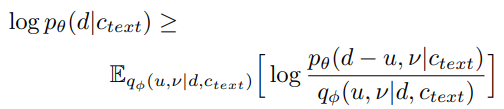
lower bound로 오른쪽 식을 줄이도록 한다.
(dequantization 까지 커버 못하는 것은 양해 바랍니다 (__) )
어쩄든 중요한건 duration이 noise가 들어가서 소수로 나온다!!! context를 기반으로 인코더가 duration을 랜덤하게 생성하게 한다!
Adversarial training
AT란 모델을 보다 robust하기 위해서 일부러 모델을 perturbed된 input을 입력하여 학습하게 하는 것이다.
AT를 하기 위해서 discriminator D를 도입하는데, 이는 decoder G에 의해 생성된 것이랑, GT y를 구분하기 위함이다.
2가지 LOSS를 도입한다
하나는 2017, least square for AT이고
하나는 2016, additional feature matching loss이다.
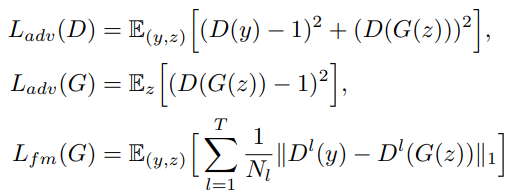
fm loss는 각 discriminator의 layer별 feature들 끼리 비교해서 차이 적게 하는 것이다. 이는 hidden feature 단위의 reconstruction error라고 볼 수 있다.
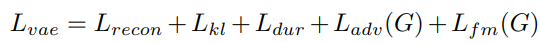
전체 LOSS
model architecture
1. posterior encoder
posterior로는 non-causal WAVENET block을 사용했다.
이는 dilated convolution과 residual block으로 이루어져 있고 맨 위의 linear layer가 사후 정규분포의 평균,분산 생성.
2.prior encoder
transformer의 text encoder를 사용한다. 그리고 여기에 linear layer를 붙여서 평균 분산을 생성한다.
여기서 normalizing flow는 wavenet residual block이 쌓여져 있는 affine coupling layer로 이며 , 이 크기를 유지하기 위해 자코비언 판별식을 사용했다.
3.decoder
HIFI-GAN V1 generator를 사용한다. 이는 transposed convolution과 multi-receptive field fusion module로 이루어져 있으며 output은 다른 receptive field를 가지는 residual block의 합이다.
4.discriminator
이것도 HIFI GAN을 사용한다.
multi-period discriminator는 markovian window-based sub-discriminator 들 로 이루어져 있따. 이들은 각각 다른 periodic을 처리한다.
experiment
datasets
데이터는 2개를 썼다
LJ Speech - 전체 24시간 분량의 13100개의 short audio clip으로 구성되어 있다. 22khz 샘플링이며 12500,100,500을 train/valid/test로 나누었다
VCTK - 109명의 native speaker에 의한 44000 short audio clip이 있다. 전체 44시간이며 44khz이다. 22khz로 나누었고 , 43470/100/500으로 train/valid/text나누었다
preprocessing
linear spectogram과 short time 퓨리에 변환 사용. FFT, window , hop size는 1024 , 1024 , 256이다. 80 band mel-scale을 쓴다.
국제 음성기호를 prior의 input sequence로 사용한다. 우리는 텍스트를 음성기호로 변환하며 토큰들은 blank로 떨어져있다.
training
32 사이즈의 window 별로 생성하는 windowed generator training을 한다. 훈련할 때도 전체 wave가 아닌 , window에 해당하는 것 가지고 훈련한다.
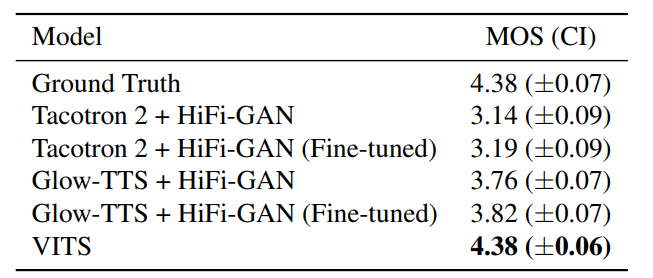
experimental setup for comparision
results
speech synthesis quality
참가자는 1~5점 으로 quality를 메기도록 하였으며 모든 오디오 클립을 정규화했다.

DDP 같은 경우 glow-tts에서 사용한 DETERMINISTIC DURATION PREDICTOR 구조인데 , 이는 VITS의 다음에 해당한다.
해당 결과는 다음과 같은 점을 시사한다.
1) stochastic이 deterministic보다 더 현실적이다
2) 동일한 stochastic을 쓰더라고 VITS가 짱이다.
또한 poteroir의 linear-scale spectrogram과 prior encoder의 normalizing flow에 대해서 ablation을 했다.
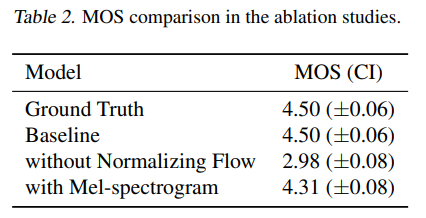
prior에서 normalizing flow가 없을 때 훨씬 못했다, 이는 prior의 유연성이 매우 중요하다는 것을 의미한다.
poterior에 있어 linear scale을 mel spectrogram으로 대체하니 성능이 감소했다. 이는 high resolution이 VITS에 있어서 효과가 있다는 것을 보여준다.
generalization to multi speaker text to speech
멀티 스피커 능력을 보기 위하여
Tacotron 2, glow-tts, hifi-gan을 훈련하고 multi speaker embedding을 추가하였다. 멀티 스피커 능력도 VITS가 이겼다
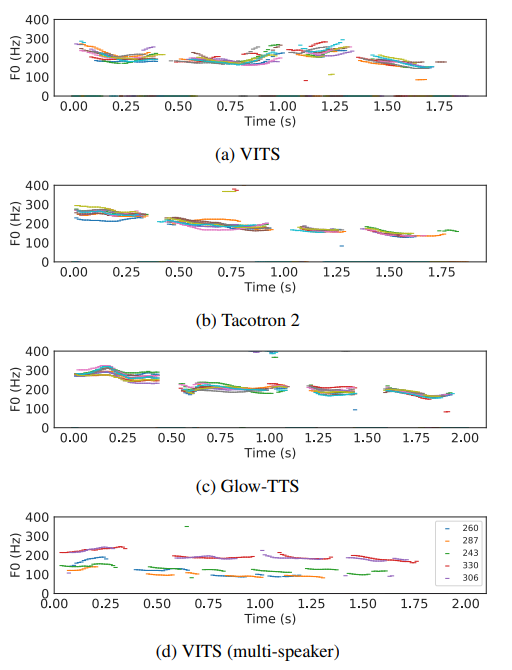
speech variation
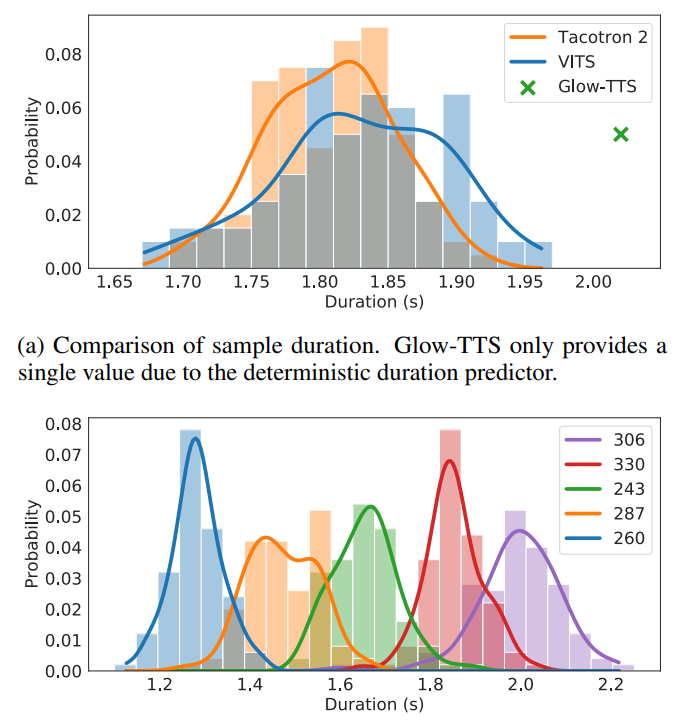
stochastic duration predictor로 인해서 다양한 샘플이 생성이 된다.
동일한 문장으로도 다양한 분포가 생성된다.
synthesis speed
100개의 샘플 별 생성 시간 비교. VITS가 생성 시간도 짧다
코드


generator



output , feature map return
train and evaluate



ref : Autoencoding beyond pixels using a learned similarity metric
