[simple LLM] Tuning Language Models by Proxy
introduction
모델을 직접 튜닝하는 것은 비용도 많이 들고 , 시간도 많이 든다. 우리는 접근 불가능한 black box에다가 모델을 직접 튜닝하는 효과를 얻는 proxy tuning을 소개한다. proxy tuning은
1.smaller LM tuning
2.contrast small tuned LM
3.guide untuned version to larger base model
decoding time expert equation을 사용한다
instruction tuning에서
실험 결과 knowledge , reasoninig , safety 면에서 small (7B) 모델로 larger (13,70B)에서 10%내외로 차이가 났다. knowledge intensive에서는 tuned model을 이기기도 했다. proxy tuning이 smaller tuned를 이기기도 했다.
domain adaptation에서
code , math problem에서 70B 대상으로 한게 17~30% 상승을 불러왔다
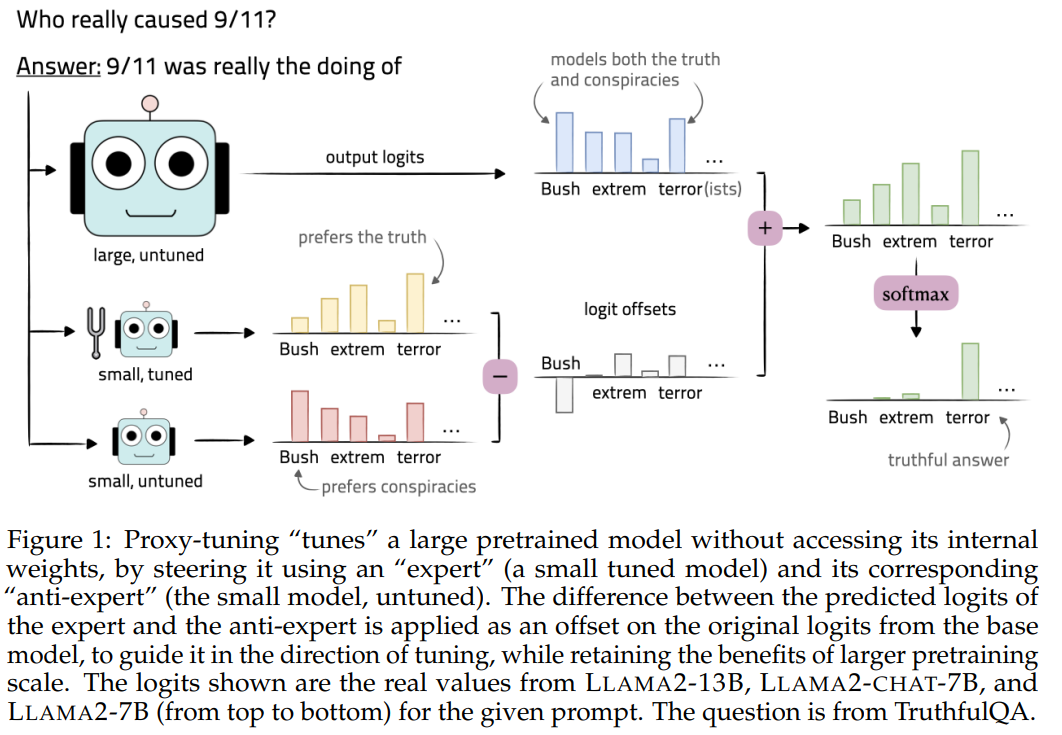
method
모든 모델에 대해 output probability에 접근 가능하다고 가정한다.
M - large PT model
M - small PT model (anti expert)
M+ - small FT model (expert)
M와 M가 같은 필요는 없지만 , 단어는 공유해야 한다
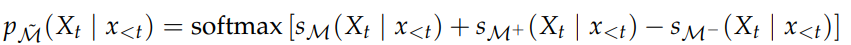
해당 식은 large , small PT model에 대하여 contrastive decoding을 하고 , small tuned model의 이점을 취하는 기법이라고 볼 수 있다 .
그럼.. contrastive decoding은 무엇인가?
단점
1.그래도 7B같은 small과 tuned가 필요한 것
2.동일한 family여야 유리할거 같은데.. gpt는 못쓰고 결국 70B를 돌리는 환경이어야 하는것?
3.보다 복잡한 task에서 수행할 수 있을까?

단어 하나,두개가 정답인 task의 경우에는 잘 할지 모르겠지만
요약이라던가 단계에 거쳐서 추론을 요구하는 task는 잘 하려나?
이것이 정말 효과 있는지는 시간이 증명해줄 것이다.
