[ASRstudy] SPEECH AND SPEAKER RECOGNITION FROM RAW WAVEFORM WITH SINCNET intro
abstract
최근 DNN speech recognition은 MFCC보다 더 많은 정보를 가진 raw wave를 input으로 넣고 있다. 하지만 이는 challenging하다. 우리가 제안하는 Sincnet을 쓰면 sinc function을 통해 CNN first layer에서 low and high cutoff frequencies를 잡아낼 수 있다. 빠른 수렴 가능하다
introduction
최근 딥러닝은 단순한 것을 input넣어서 복잡한 문제를 해결한다. 그러니 pixel,raw wave등 을 input으로 넣어야 딥러닝에 적합다고 볼 수 있다.
speech 분야의 sota 모델의 feature는 hand crafted인 FBANK and MFCC가 있다. 하지만 이런 feature가 optimal 하다는 근거는 없다. 이러한 단점 보완하기 위해 요즘은 spectrum이나 raw wav를 CNN에 넣는다
그런데 CNN은 noisy 하거나 incongruous multi-band shapes을 잡아낸다. 이는 인간의 intuition에 맞지 않는다.
의미 있는 filter를 학습하기 위해 filter shape에 제한을 두는 sincnet을 제안한다.
Sincnet은 speaker verification에서 의미있는 성능 향상이 이루어졌다. 또한 이는 interpretable filter를 보인다.
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
이 논문을 알기 위해 선행되는 SINCNET을 알아야 한다
sincnet 탄생 논문.
Speaker Recognition from raw waveform with SincNet
introduction
최근 음성인식 많이 발전하고 있다. 그런데 deep learning 기반은 MFCC와 같은 hand-craft 기법만 사용하고 있다. 이와 유사한 smooth speech spectrum은 narror-band 특징 (pitch , formant)를 잘 잡아내지 못한다. 이런걸 다루기 위해 cnn 쓴다
cnn의 첫번째 layer가 가장 중요한데 , 이는 vanishing gradient의 영향을 많이 받는다. 또한 데이터가 매우 적으면 이렇게 학습된 필터는 노이즈를 가지고 있으며 사람에게도 직관적이지 않다
더 의미 있는 filter를 갖기 위해 모양을 제한하기를 제안한다.
the SincNet convolves the waveform with a set of parametrized sinc functions that implement band-pass filters.
이는 사람이 보기에 더욱 직관적이기도 하다.
실험 결과 사람마다 짧고 적은 데이터를 가지고 학습하는데 cnn보다 더 낫다.
architecture
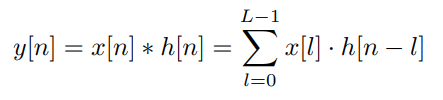
본래 cnn의 식은 다음과 같다. x는 변수. l은 filter의 길이. n는 chunk의 n th 이다.
Q. filter의 길이라 함은 .. filter의 개수 인가?
Q. x[n]은 n번째 chunk? 그럼 x[l]은 뭐지? 모두 같은 값인가?
Q. cutoff-frequency가 무엇이지? -> (chatgpt) response가 급격하게 감소하는 frequency
이게 기존 cnn이라면 sincnet은 매우 적은 parameter를 가진다
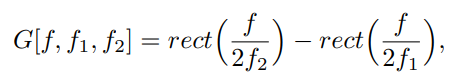
두개의 주파수로 나타내는 직사각형 모양의 filter. 주파수만 보겠다는 것이다.
이를 역퓨리에 변환으로 time에 대한 domain으로 나타내면
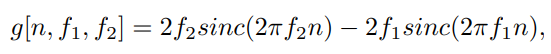
좌우 대칭인 주기 함수가 된다.
initialize를 mel scale에서 cutoff frequency로 초기화 된다.
이 방법을 적용함으로써의 이점은 다음과 같다.
1.fast convergence.
주된 영향을 미치는 filter만 학습하게 하기 때문에
2.few parameters
필터 개수가 F ,길이가 L 일 때 CNN은 F x L , sincnet은 2F
3.계산 효율성
4.interpretability.
-> 어떤 주파수에 집중하는가?
