[simple LLM] Self-Rewarding Language Models
introduction
PT모델에 feedback 주는게 엄청 powerful하다. RLHF로 인간이 피드백하고 reward model frozen하는게 기존 PPO이며 최근은 preference로 바로 학습하는 DPO가 있다. 여기에는 2가지 단점이 있는데 , preference data의 quality,size 또한 frozen reward model의 퀄리티이다.
우리는 self-improving RM을 제안한다. 이전 연구에서 PT와 instruction tuning을 동시에 하면 작업수행능력 높아지는 것처럼 , RM도 동시에 하면 RM modeling과 instruction following을 동시에 잘한다
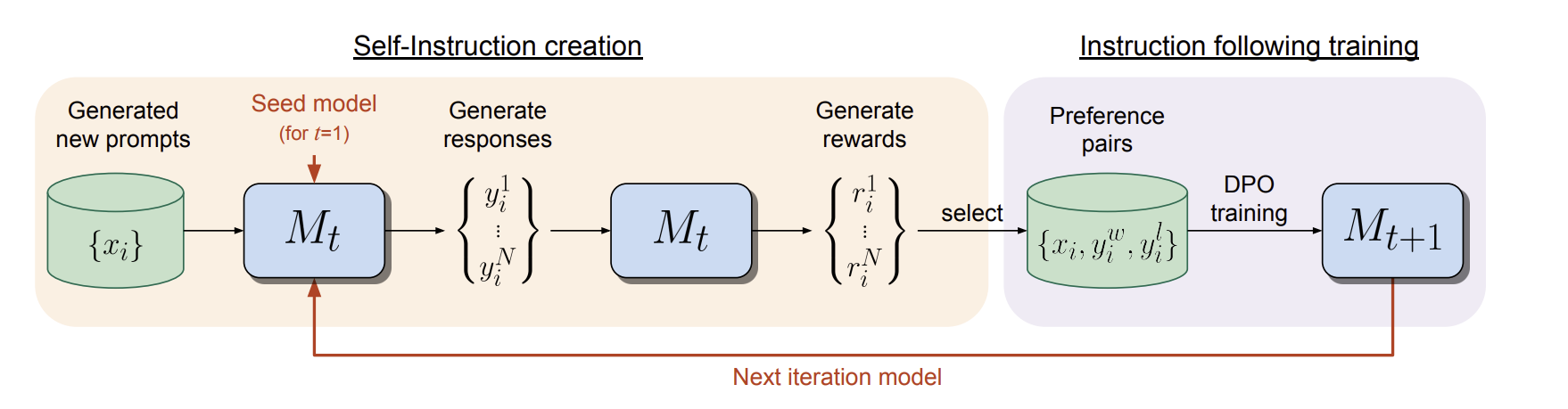
self rewarding language models
학습에 있어 2가지 역할을 동시에 하도록 한다.
1.instruction following : helpful response를 생성하는 능력
2.self-instruction creation : 새로운 instruction example을 생성하고 평가하는 것
self-instruction creation은 instruction에 대한 response를 생성하고 LLM이 이를 스스로 평가하게 해서 reward model의 역할을 한다.
이 과정이 iterative하게 이루어 진다. 이 과정을 통해 RM 능력 뿐만 아니라 , instruction following 능력도 증가한다. 이러면 human data로 만들어진 고정된 RM보다 더 나은 RM을 제공할 수 있다.
initialization
seed insturction following data - human authored seed dataset을 구하고 이를 FT한다
Seed LLM-as-a-Judge instruction following data - 또한 training에 사용되는 evaluation prompt , response도 주어진다. evaluation 과정은 COT를 이용해서 행해진다

이것은 evaluation finetuning data로 이름 붙힌다.
self-instruction creation
그 다음에 training set을 self-modify한다.
1.generate new prompt. IFT data로부터 새로운 prompt x_i를 sampling한다.
2.generate candidate response. N diverse response를 생성한다.
3.evaluate candidate response. 같은 과정을 통해 다시 judge한다.
AI Feedback training
처음엔 IFT , EFT로 학습되는데 , 그 이후 AIFB으로 augment되어서 학습된다.
overall self-alignment algorithm

experiment
seed traninig data
initial finetuning data open assistant data (2024)
EFT data
evaluation metric
eval 기준은 2가지이다
1.intrtuction following
alpacaeval 데이터로부터 256개 sampling해서 GPT4한테 평가하고 , tie일 경우 pairwise를 한다. 또 다양한 데이터에 실험한다
2.reward modeling
open assistant 데이터 에는 데이터 퀄리티에 대한 human eval이 존재한다.
우리는 SFT 모델을 가지고 figure-2에서 제공했던 question-response pair에 대해 점수를 메기도록 하고 , 사람과 eval이 일치한 데이터만 traning에 넣는다.
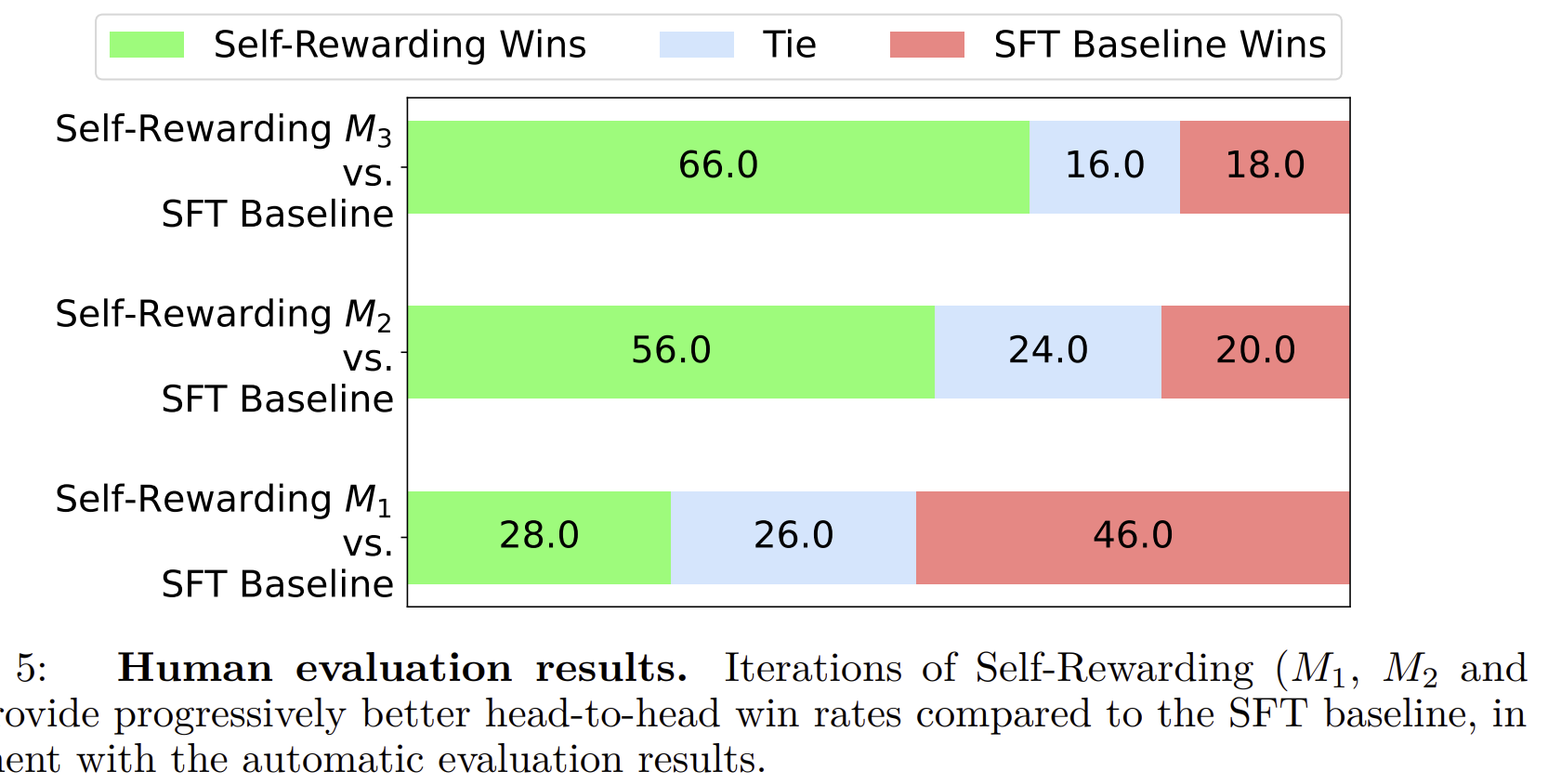

이는 다른 task를 수행하고 학습함에도 기존의 성능을 놓치지 않는다는 설명.
