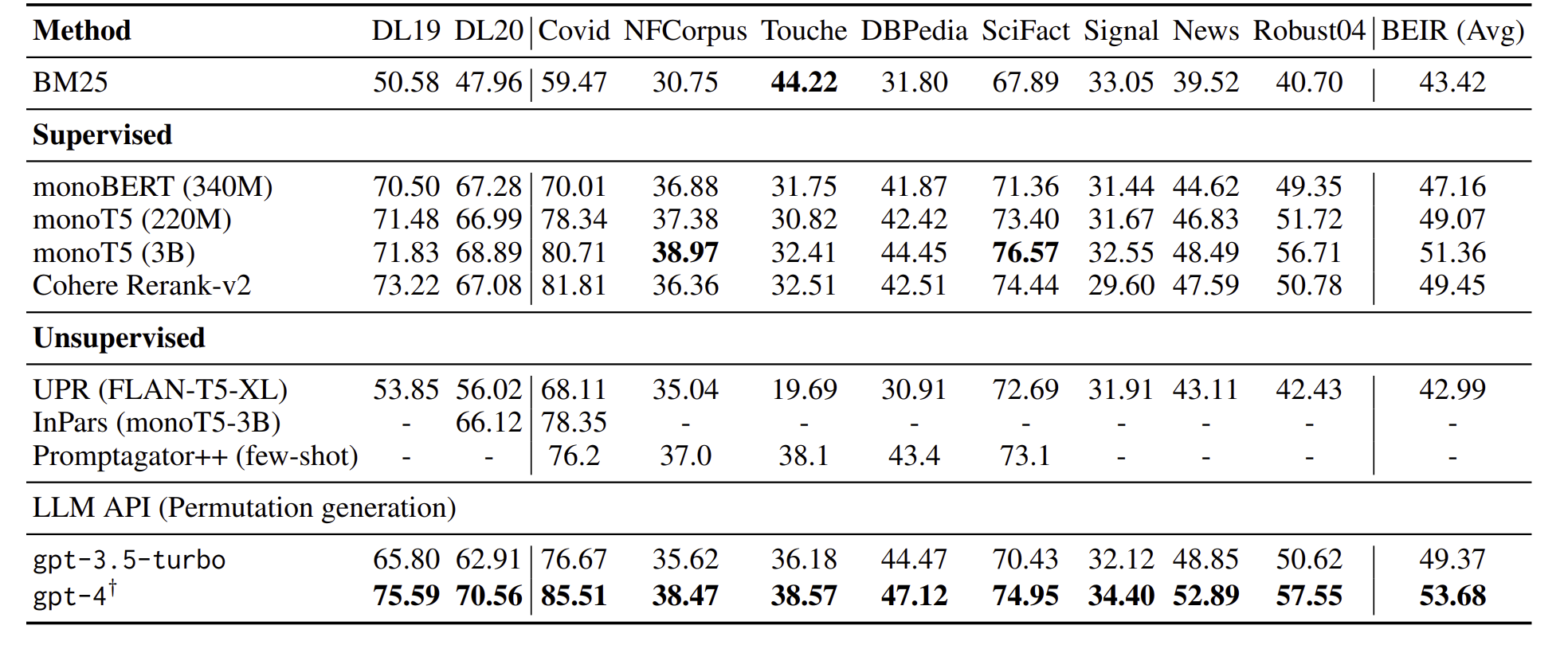
[LLM review] Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents
introduction
IR의 발전으로 re-ranking or passage retrieval 등이 사용되고 있다. 이에 대한 LLM의 활용에 대한 수요가 늘고 있지만 여전히 generation task에만 관심이 있다
relevance re-rank를 하기 위해서는 agent는 전체적인 문서와 query를 대조해야 한다. 그래서 우리는 다음 RQ가 있다
1)chatgpt가 re-ranking 어떻게 하는가?
2)더 적은 모델에 어떻게 re-ranking하는가?
chatgpt로 re-ranking하는데 log-probability 쓰는데 한계가 있다. 그래서 우리는 permutation genration을 제안한다.
이는 permutate해서 output하는 건데 여기다가 효율을 위해 sliding window도 제안한다. 또한 unknowed knowledge에 대해 LLM 평가하기 위해 noveleval도 제안한다
거기다가 작은 모델로 re-ranking하기 위해서 permutation distillation을 한다.
passage re-ranking with LLM
LLM가지고 re-ranking하는 연구가 좀 있지만 이는 log-probability에 너무 의존한다. 우리는 sliding window가 있는 instructional permutation generation을 한다.
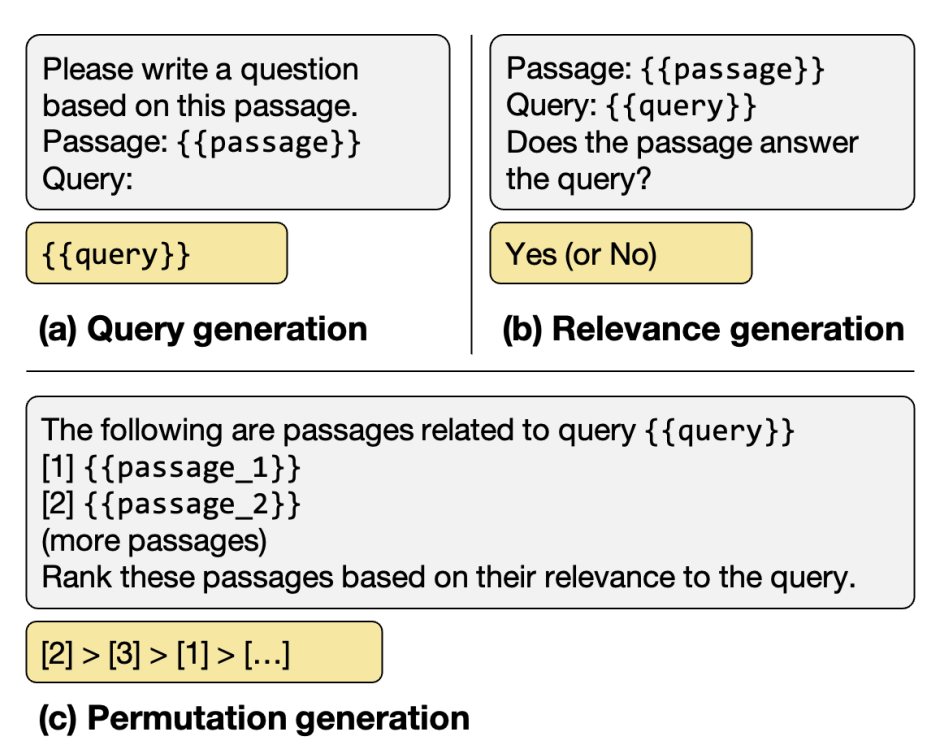
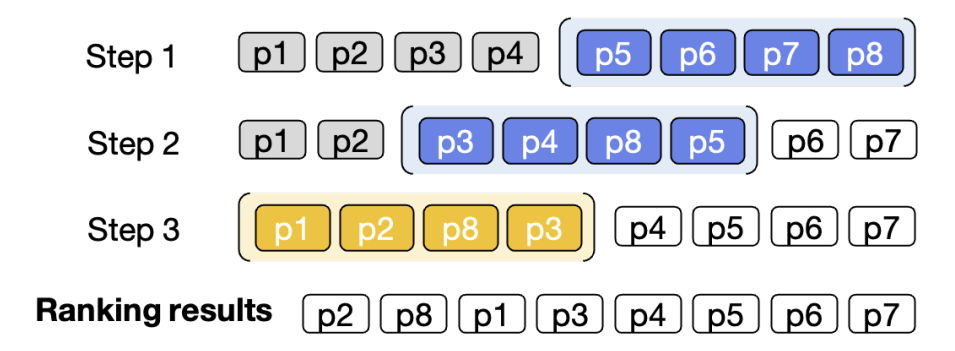
list를 생성해달라고 하는데 input limit때문에 sliding window로 하나하나씩 훑어간다.
window size, step size를 HP.로 조절한다.
또한 distillation도 하는데
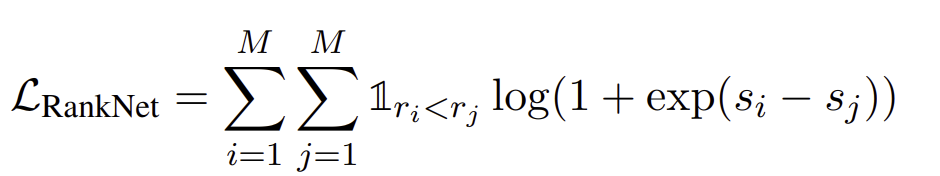
chatgpt가 내놓은 permutation에 대하여 distillation하는데 이때 ranknet loss를 사용. s_i,s_j는 cross-encoder를 이용한 relevance-score를 의미함.