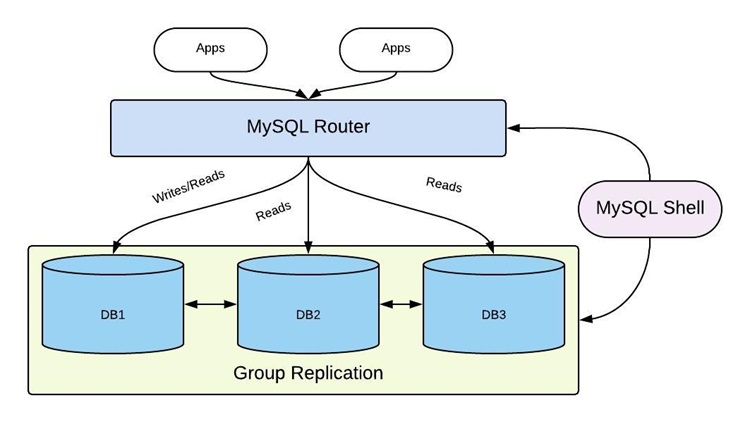
클러스터(Cluster) 란 무엇인가? ✍
- "MySQL Cluster" 는 기존의 MySQL Replication 의 단방향 데이터 전송 시스템
(Master-Slave)의 단점을 보완하고 보다 안전하고 활용성 높은 시스템 구현을 가능하게 해주는 것으로, Cluster로 묶여진 서버는 어느 서버에서 데이터가 입력, 수정, 삭제 되더라도 다른 데이터 서버로의 갱신이 신속하게 이루어진다. - 또한, 장애 발생 시 장애의 원인을 인지하여 스스로 복원하는 기능을 제공하고 있기 때문에 무정지 DB 시스템을 원하는 Client에게 권장된다.
- 즉, 클러스터링으로 구성한 서버는 대량의 트래픽으로 DB 서버가 다운되어도 또 다른 서버로 서비스를 유지하는 것이 가능하다.
"Replication" 과 "Clustering" 의 차이는 무엇인가? ✍
- ✅ 리플리케이션(Replication)
- 리플리케이션은 여러 개의 DB를 권한에 따라 수직적인 구조로 구축하는 방식으로
Master Node에서는 쓰기 작업 만을 처리하고,Slave Node에서는 읽기 작업만 처리한다. - Master와 Slave 간의 데이터 무결성 검사를 하지 않는 비동기 방식이기 때문에
지연 시간이 거의 없고, DB 요청의 대부분이 읽기 작업이기 때문에 리플리케이션만 사용해도 충분히 성능을 높일 수 있다는 장점이 있다. - 하지만❗ 노드들 간의 데이터 동기화가 보장되지 않아 일관성있는 데이터를 얻지 못할 수도 있으며,
Master Node가 다운되면 복구하는것이 까다롭다.
- 리플리케이션은 여러 개의 DB를 권한에 따라 수직적인 구조로 구축하는 방식으로
- ✅ 클러스터링(Clustering)
- 클러스터링은 여러 개의 DB를 수평적인 구조로 구축하는 방식으로 분산 환경을 구성하여
Fail Over시스템을 구축하기 위해 사용된다. - DB들 간의 데이터 무결성 검사를 하는 동기방식으로 데이터를 동기화하기 때문에 항상 일관성있는 데이터를 얻을 수 있고, 1개의 Node가 죽어도 다른 Node가 살아있기 때문에 시스템을 장애없이 계속 운영할 수 있다.
- 하지만❗ 여러 Node들 간의 데이터를 동기화하는 시간이 필요하므로 리플리케이션보다 속도가 느리다.
- 클러스터링은 여러 개의 DB를 수평적인 구조로 구축하는 방식으로 분산 환경을 구성하여
❗Cluster 구성 실습하기❗
- 사전 준비사항 : 리눅스 가상머신 4대 ( 3대 : DB Server로 사용 / 1대 : 라우터로 사용 )
-
컴퓨터 이름 설정 :
vi /etc/hostname
➡ 수정 후 시스템 재시작(init 6) 시 반영된다.
➡ 나는 "db1", "db2", "db3", "router" 로 설정하겠다.
-
컴퓨터의 IP 를 설정해준다. ( 아래는 내가 설정한 IP 주소이다. )
➡ db1 : 77.77.77.131
➡ db2 : 77.77.77.132
➡ db3 : 77.77.77.133
➡ router : 77.77.77.100
-
컴퓨터의 IP 주소를 이름으로 설정 :
vi /etc/hosts
➡ 기본 양식 : [DB1 IP주소] [지정할 이름]
➡ 위와 같이 4대의 컴퓨터 모두 설정해준다. 여기서 중요한 것은 이름을 지정해줄때
1번에서 설정해준 컴퓨터의 이름과 동일하게 설정✅ 해줘야된다는 것이다.
나중에 클러스터를 설정할 때 이름이 다르면 IP 주소를 찾아가질 못해서
오류가 발생하는것을 수업 시간에 확인했었다.
- 여기서부터는 라우터 컴퓨터를 제외한 DB 서버 컴퓨터 3대만 해당되는 사항이다.
- "mysql-server" 및 "mysql-shell" 설치
1) mysql-server 설치 :yum install -y mysql-server
2) mysql이 제공하는 repo(저장소) 추가
yum install -y https://dev.mysql.com/get/mysql80-community-release
-el8-9.noarch.rpm
3) mysql-shell 설치 :yum install -y mysql-shell
- mysql 서버 실행 및 초기 설정
- 서버 실행 :
systemctl start mysqld - 초기 설정 :
mysql_secure_installation
- 서버 실행 :
- 클러스터 구성을 위한 계정 생성
1) mysql-shell 실행 :mysqlsh
2) 계정 생성 :dba.configureInstance('root@localhost:3306')
➡ Please provide the password for 'root@localhost:3306' : 패스워드 입력
➡ Save password for 'root@localhost:3306'? : yes
➡ root 사용자 권한을 어떻게
➡ ERROR: User 'root' can only connect from 'localhost'. New account(s) with
proper source address specification to allow remote connection from all
instances must be created to manage the cluster.
1) Create remotely usable account for 'root' with same grants and password
2) Create a new admin account for InnoDB cluster with minimal required grants
3) Ignore and continue
4) Cancel
➡ root 사용자 권한을 어떻게 사용할건지 묻는 것으로2입력 후 새롭게 사용할
root 권한 계정명clusteradmin과 사용할 비밀번호를 입력해준다.
➡ Do you want to perform the required configuration changes? [y/n]: y
설정 바꾸는것을 할거냐? yes
➡ Do you want to restart the instance after configuring it? [y/n] : y
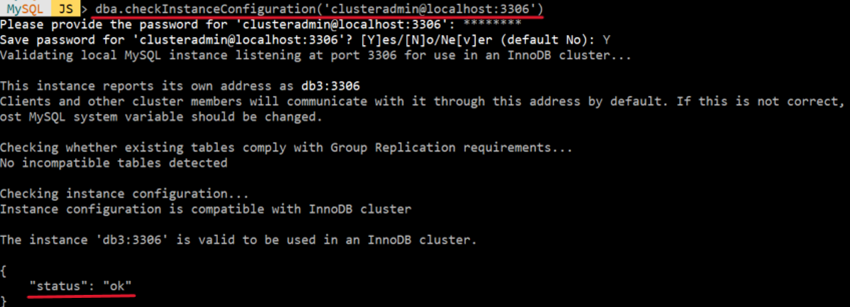
3) 정상적으로 계정 생성이 완료됬는지 확인
➡ mysql-shell 에서 root 계정으로 로그인 후 "status" : "OK" 확인
dba.checkInstanceConfiguration('clusteradmin@localhost:3306')
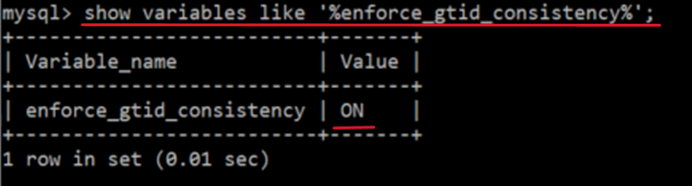
➡ mysql에서 root 계정으로 로그인 후 아래의 명령어 입력 : Value 속성 "ON" 확인
show variables like '%enforce_gtid_consistency%';
-
mysql 서버 ID 및 포트 설정 :
vi /etc/my.cnf.d/mysql-server.cnf
1) [mysqld] 아래에 다음과 같이 추가
server-id=[각자 다른 숫자 임의지정]
port=3306
mysqlx=ON
mysqlx-port=33060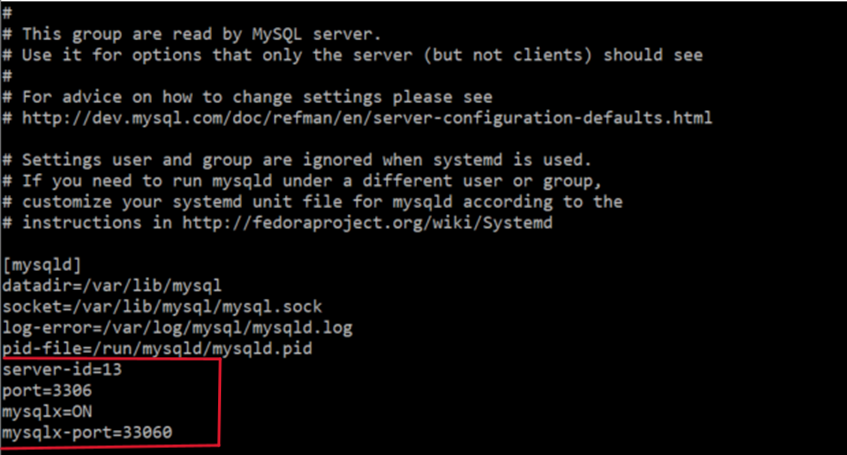
2) 설정 파일을 수정했으므로 재시작 :
systemctl restart mysqld -
방화벽 끄기 :
setenforce 0(로컬) 과systemctl stop firewalld(네트워크) -
클러스터 생성 : 클러스터 생성은 1개의 컴퓨터에서 실시( 나는 db1에서 실시하겠다. )
1) mysql-shell 접속 :mysqlsh
2) clusteradmin 계정으로 로그인 :\connect clusteradmin@db1:3306
3) 클러스터 생성 :var cluster = dba.createCluster('MyCluster',
{ipAllowlist: "db1, db2, db3"})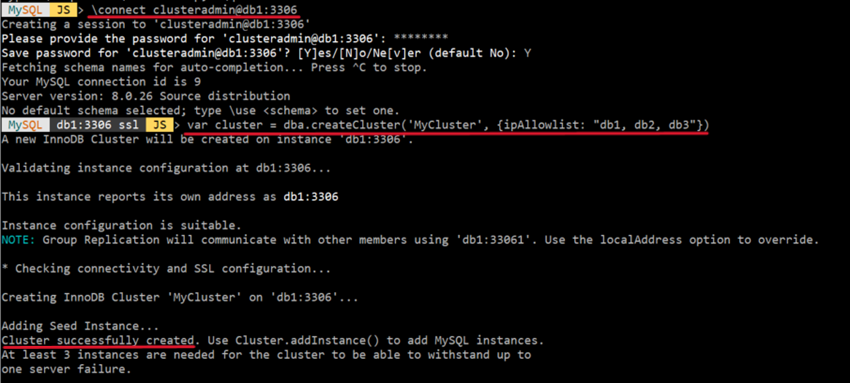 4) 위와 같이 뜨면 정상적으로 생성된 것이다.
4) 위와 같이 뜨면 정상적으로 생성된 것이다.
-
클러스터에 인스턴스 추가
1) 현재 클러스터 구성 확인 :var cluster = dba.getCluster()
2) db2 추가 / 아래 명령어 입력 후 "C" (클론 방식으로 데이터 공유) 입력
cluster.addInstance('clusteradmin@db2:3306', {ipAllowlist: "db1, db2, db3"})3) db3 추가 / 아래 명령어 입력 후 "C" (클론 방식으로 데이터 공유) 입력
cluster.addInstance('clusteradmin@db3:3306', {ipAllowlist: "db1, db2, db3"})
-
클러스터 상태 확인
1)var cluster = dba.getCluster()
2)cluster.describe()실행 : "topology" 에 db1, db2, db3이 있으면 성공
3)cluster.status()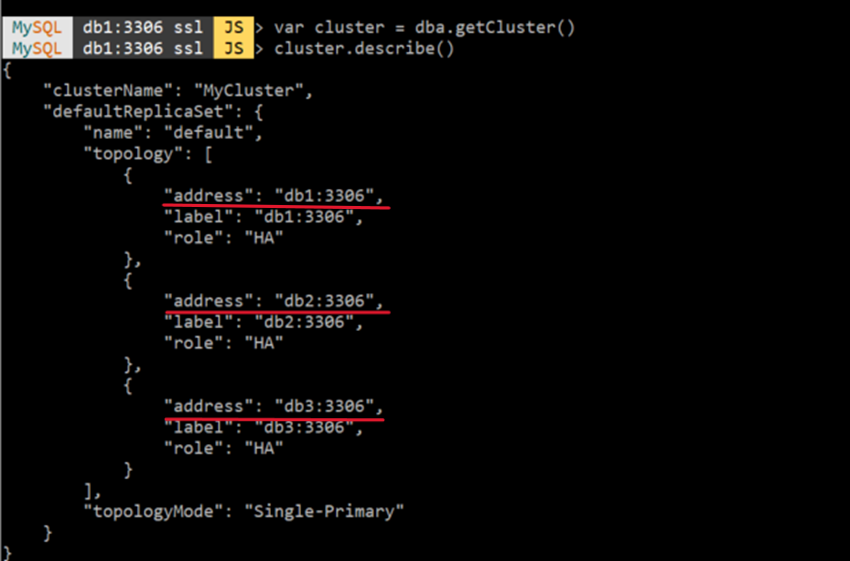
- 위와 같이 "db1", "db2", "db3" 가 "MyCluster" 라는 이름의 1개의 클러스터로
구성된 것을 확인할 수 있다. - topologyMode : "Single-Primary" 라는 것은 클러스터의 모드이며, 클러스터 내의 1개의 서버에서만 "읽기/쓰기" 기능 사용이 가능하고, 나머지 서버들은 "읽기" 전용으로 하는 모드를 말한다.
(여기서는 db1에서 클러스터를 생성했기 때문에 읽기/쓰기 기능은 db1 서버가 갖는다.) - 다른 모드로는 "Multi-Primary" 가 있는데, 이것은 클러스터 내의 모든 서버에서
"읽기/쓰기" 가 가능한 모드이다. "읽기/쓰기" 작업을 많이 수행하는 서버를 구성할때 보통 사용한다.
Single-Primary 와 Multi-Primary 모드 변경하는 방법 🧐
-
Multi-Primary -> Single-Primary ✅
1) mysql-shell 실행 :mysqlsh
2) clusteradmin 계정으로 로그인 :\connect clusteradmin@db1:3306
3) 모드 변경 쿼리문 입력 :cluster.switchToMultiPrimaryMode();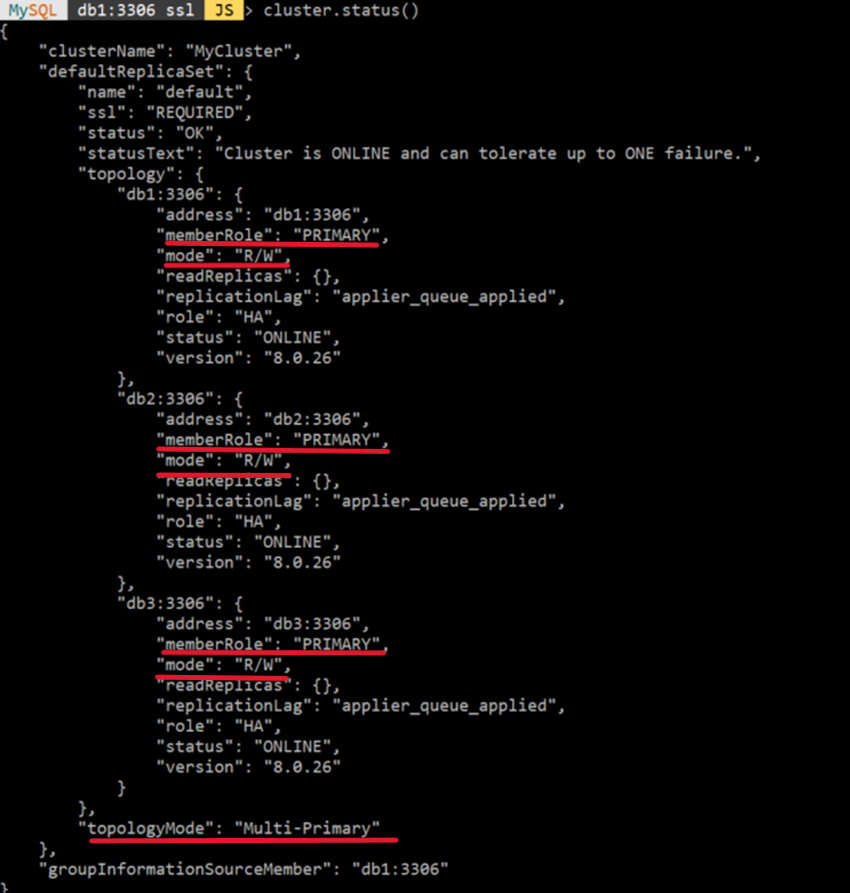
-
Single-Primary -> Multi-Primary ✅
1) mysql-shell 실행 :mysqlsh
2) clusteradmin 계정으로 로그인 :\connect clusteradmin@db1:3306
3) 모드 변경 쿼리문 입력 :cluster.switchToSinglePrimaryMode();
➡ 이렇게 하면 기존에 "db1"이 Primary 였기때문에 그대로 "db1" 이 Primary 가 된다.
4) Primary를 변경하면서 모드 변경
cluster.switchToSinglePrimaryMode('[변경하고자 하는 서버명]:3306');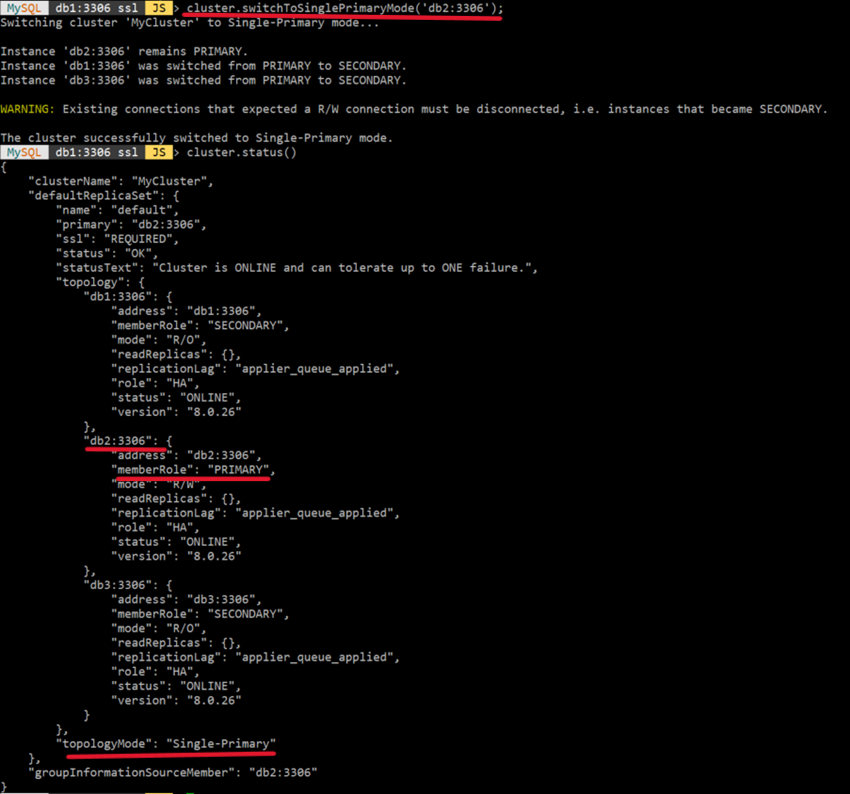
- 참고하면 좋은 클러스터 삭제 명령어
1) clusteradmin 계정 로그인 :\connect clusteradmin@db1:3306
2)var cluster = dba.getCluster()
3)cluster.dissolve()
❗라우터 구성 실습하기❗
1. 라우터 컴퓨터의 방화벽을 꺼준다.
1) setenforce 0
2) systemctl stop firewalld
2. mysql-router를 설치한다.
1) mysql이 제공하는 repo(저장소) 추가
yum install -y https://dev.mysql.com/get/mysql80-community-release
-el8-9.noarch.rpm
2) mysql-route 설치 : yum install -y mysql-router
3. mysql-router를 구성한다.
mysqlrouter --bootstrap clusteradmin@db1:3306 --name clusterrouter
--directory mycluster --account myrouter --user root
--bootstrap : 대표 서버 주소
--name : 구성할 라우터 이름
--directory : 구성 파일이 생성 될 디렉토리의 경로
--account : 라우터로 접속할 때 사용할 계정
--user : 파일을 생성할 리눅스의 사용자
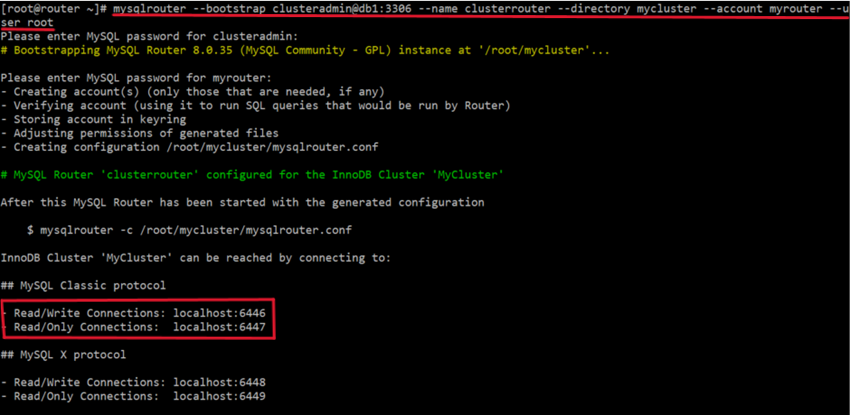 - 정상적으로 구성된다면 위와 같이 접속할 수 있는 포트번호가 출력된다.
1) 읽기/쓰기가 가능한 연결 : `6446` 포트
2) 읽기만 가능한 연결 : `6447` 포트
- 정상적으로 구성된다면 위와 같이 접속할 수 있는 포트번호가 출력된다.
1) 읽기/쓰기가 가능한 연결 : `6446` 포트
2) 읽기만 가능한 연결 : `6447` 포트
4. 라우터를 실행한다 : /root/mycluster/start.sh
5. MySQL Workbench 에서 접속 테스트를 한다.
hostname : [라우터 컴퓨터의 IP 주소]
username : [라우터 구성 시 생성해준 계정명]
port : [6446 or 6447] / 6446은 읽기/쓰기 가능, 6447은 읽기만 가능
➡ 각각 포트로 접속 후 show variables LIKE '%server_id%'; 쿼리문을 입력하여
출력되는 server-id 를 확인해본다.
➡ 6446 포트로 접속하면 읽기/쓰기가 가능한 1개의 server-id가 출력될 것이고,
6447 포트로 접속하면 나머지 2개의 server-id가 접속할때마다 바뀌면서
출력되는 것을 확인할 수 있다.
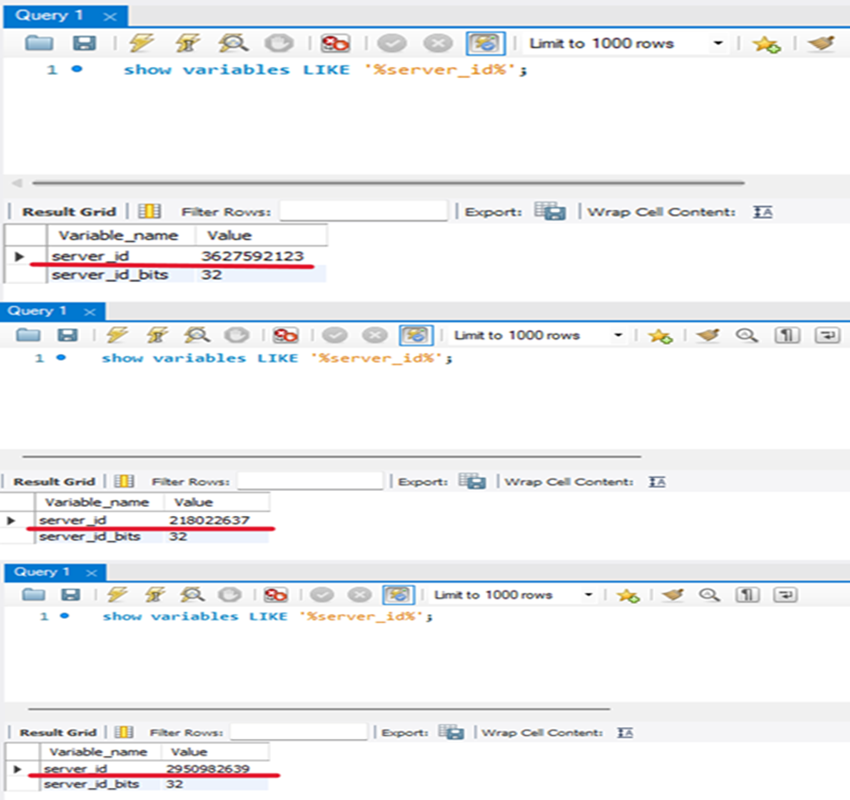
- 이때
server-id가 내가 설정해준 id랑 다르게 나타나는데 중요한 사항은 아니다. 중요한것은server-id가 포트 번호에 맞게 접속했을 때 동일한 숫자로 출력되면 된다.
오늘의 느낀점 👀
- 드디어 내일이면 DB 수업이 끝이 난다. 오늘 클러스터를 배움으로써 대용량 트래픽을 어떻게 관리하는지에 대해 조금이나마 이해를 할 수 있는 시간이었다.
- 리플리케이션과 클러스터링 두가지 중 어떤게 더 좋다 안좋다 할 수는 없겠지만 각각의 장/단점이 명확하게 존재하고, 기업 자체적으로 본인에게 맞는 방법을 선택할 것 같다.
- 가장 중요한것은 동기식이냐, 비동기식이냐로 나뉘고 그에따라 속도와 성능을 선택할 것인가? 안전성을 선택할 것인가? 를 선택하는 문제라고 생각한다.
- 내일 마지막 수업까지 집중해서 듣고, DB에 대한 정리를 마무리 해야겠다. 하루가 지날수록 배우는 내용이 심화되어지고 점점 내용들이 쌓이기 시작하는데, 하루라도 복습을 제대로 안하면 안될것 같다는 생각이 다시한번 들었다.
- 지금 이 마음가짐, 처음 부트캠프를 들어올때의 마음가짐을 항상 생각하며 끝까지 혼신을 다해서 불태울 것이다.😎
