
🐻 DB 성능 개선 - 1 ( N + 1 문제 해결 )
N + 1 문제란 ❓
-
JPA를 사용한다면 반드시 발생하는 문제이다. 연관 관계에서 발생하는 이슈로 연관 관계가 설정된 엔티티를 조회(Read) 할 경우에 조회된 데이터 갯수(n) 만큼 연관관계의 조회 쿼리가 추가로 발생하여 데이터를 읽어오게 된다. 이를 N+1 문제라고 한다.
-
실제 예시를 들어보겠다. 코드는 지난 글에서 사용했던 코드를 그대로 사용하였다.
상품과상품이미지엔티티가 1:N 관계를 형성하고 있다고 할 때, 상품의 리스트를 출력해보는 것으로 N+1 문제를 바로 확인할 수 있다. -
상품 테이블에는 상품 테이블과 상품 이미지 테이블에는 아래와 같이 5개씩 데이터가 들어있다.
✅ 상품 테이블
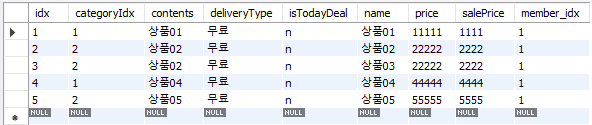
✅ 상품 이미지 테이블

-
여기서 상품 List를 출력해본다고 할 때 실행되는 쿼리문은 아래와 같다.
1) 먼저, 상품 테이블을 SELECT 하면서 1회 실행되고,
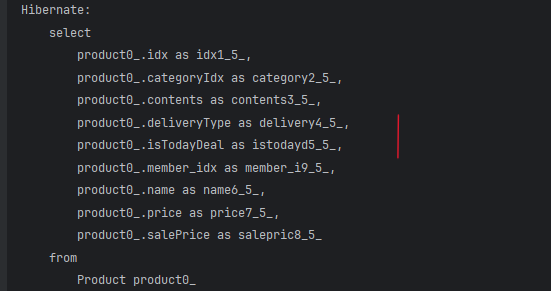
2) 다음으로, 상품 이미지 테이블을 SELECT 하는데 이때 테이블에 들어있는
데이터의 개수(N) 만큼 쿼리문이 실행된다. 나는 5개의 데이터가
들어있어서, 총 5번 실행되었다.
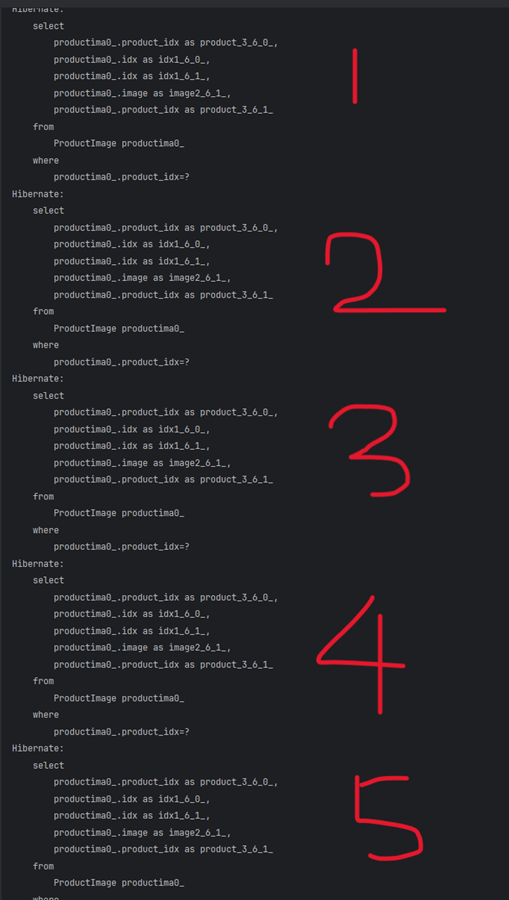
-
따라서 총 시행된 SQL 쿼리문이
1 + 5로 다시 말해 1 + N 문제가 발생한 것이다. 만약, 직접 쿼리문을 작성한다면 JOIN 문을 이용하여 1회만 시행하면, 상품의 List를 뽑아낼 수 있을 것이다. -
이러한, N+1 문제를 해결하지 않는다면, 수만개의 데이터가 있을 때 데이터 조회 시마다 수만번의 DB 조회를 하게 되어 DB의 성능을 저하시키므로, JPA를 사용한다면 이러한 N+1 문제를 해결해줘야 된다.
🐶 N+1 문제를 해결하는 방법
-
N+1 문제를 해결하는 방법에는 대표적으로
1) JPQL 사용
2) QueryDSL 사용
3) EntityGraph 사용의 3가지 방법이 있는데, 수업 때는 JPQL 과 QueryDSL 에 대해서 알아보았다.
-
먼저, JPQL을 사용하는 방법이다.
➡ 장점 : 제일 간단하게 N+1 문제 해결이 가능하다.
➡ 단점 : 페이징 기능의 구현이 어렵다.: JPQL은 JPA의 일부로 쿼리를 테이블이 아닌 객체(=엔티티)를 기준으로 작성하는 객체지향 쿼리 언어이다. 즉, 쿼리문을 직접 작성하는 것인데 작성 예시는 아래와 같다.
@Repository public interface ProductRepository extends JpaRepository<Product, Integer> { public Optional<Product> findByIdx(Integer idx); @Query("SELECT p FROM Product p " + "LEFT JOIN FETCH p.productImageList " + "LEFT JOIN FETCH p.member") public List<Product> findAllQuery(); } -
레포지터리에서 위와 같이 직접 JOIN 문을 작성해 준 뒤, 다시 상품 List를 출력해보면 아래와 같이 쿼리문이 1번 실행된다.
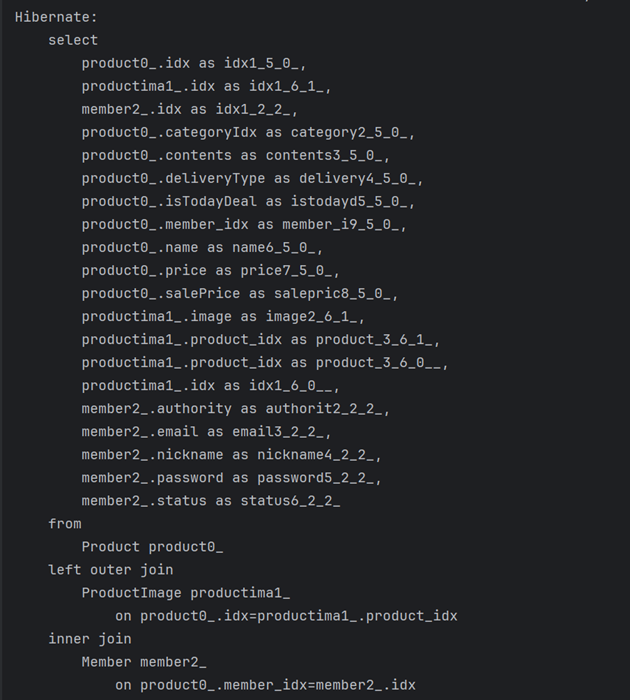
-
여기서, JOIN을 실행시키는 역할을 하는 것이 "fetch join" 이다. "fetch join" 은 JPQL에서 DB 성능 최적화를 위해 사용하는 기능으로, 특정 엔티티를 DB에서 가져올 때 연관된 엔티티까지 함께 가져오도록 하는 방법이다.
-
만약, 위의 JPQL 쿼리문에서 LEFT JOIN 을 적어준 뒤 FETCH를 안적어주면 N+1 문제는 해결되지 않고 원래와 같게 된다. 즉,
LEFT JOIN은 "이 방식으로 조인을 실시할 것이다" 라는 의미고,FETCH를 사용해야지만 지정한 방식으로 "조인을 실행하겠다가 완성" 된다. -
하지만, 이러한 JPQL도 페이징 기능을 구현하는 것은 복잡하다는 단점이 있다. 예를들어, 페이징 기능을 구현하기 위해서는 아래와 같은 쿼리문을 작성해야 된다.
@Query(nativeQuery = true, value = "SELECT * FROM test.product AS p " +
"LEFT JOIN test.product_image AS pi ON p.id = pi.product_id " +
"LEFT JOIN test.member AS m ON p.member_id = m.id LIMIT :page, :size")
public List<Product> findAllQueryWithPage(Integer page, Integer size);- 이러한 쿼리문을 페이징이 필요한 엔티티마다 다 작성해야되기 때문에 엔티티가 많아지면 엔티티들 간의 관계를 고려하여 쿼리문을 작성하는 것이 어려울 것이다.
또한, 이렇게 했을때도 N+1 문제가 여전히 발생하는 경우도 있다.
-
따라서, 이러한 것을 보완해서 나온 것이 "QueryDSL" 이다.
➡ 장점 : 일반적인 페이징 기능 등 추가 기능들 모두를 지원한다.
➡ 단점 : 스프링 라이브러리가 아니고, 코드가 복잡하다. -
✅ "QueryDSL 설정하기"
1)
pom.xml파일에 라이브러리 추가 ( 공식홈페이지에서 확인 가능 )
➡ http://querydsl.com/static/querydsl/5.0.0/reference/html_single/#d0e147<dependency> <groupId>com.querydsl</groupId> <artifactId>querydsl-apt</artifactId> <version>${querydsl.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>com.querydsl</groupId> <artifactId>querydsl-jpa</artifactId> <version>${querydsl.version}</version> </dependency>
2)
pom.xml파일에 플러그인 추가 ( 위의 홈페이지에서 확인 가능 )<plugin> <groupId>com.mysema.maven</groupId> <artifactId>apt-maven-plugin</artifactId> <version>1.1.3</version> <executions> <execution> <goals> <goal>process</goal> </goals> <configuration> <outputDirectory>target/generated-sources/java</outputDirectory> <processor>com.querydsl.apt.jpa.JPAAnnotationProcessor</processor> </configuration> </execution> </executions> </plugin>
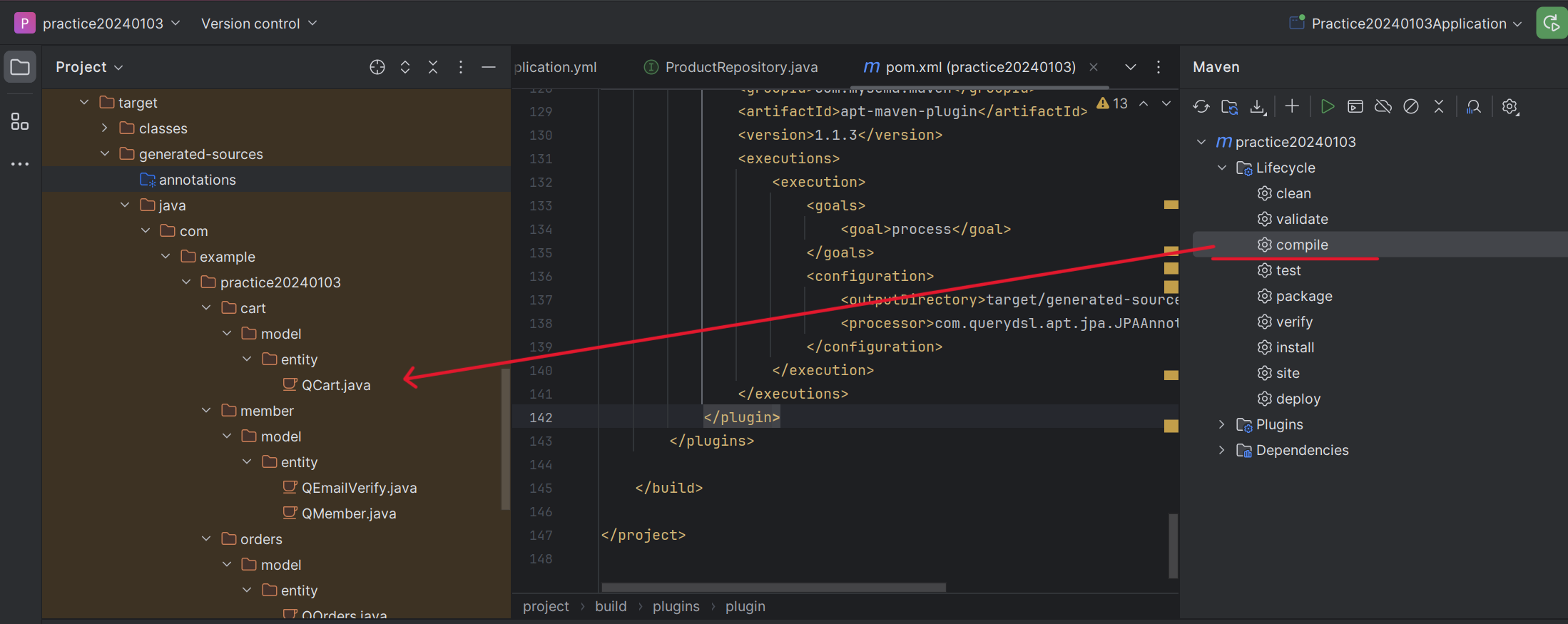
3) 인텔리제이 오른쪽 메이븐 m 표시 클릭 ➡ Lifecycle 클릭 ➡ compile 더블 클릭
➡ 그러면 아래 사진처럼target폴더 밑에 Q[엔티티명] 의 클래스들이 생기게 된다.
4)
ProductRepositoryCustom의 이름으로 새로운 레포지터리를 생성해준다.@Repository public interface ProductRepositoryCustom { public List<Product> findList(); }
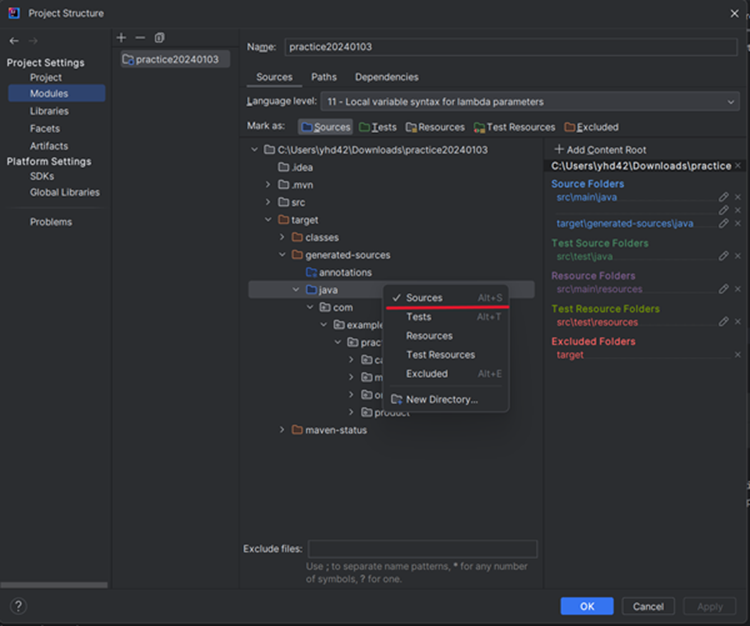
5) Q클래스들을 자바 코드로 인식되도록 설정한다.
프로젝트 우클릭 ➡Open module settings➡target➡generated-sources➡ Java 우클릭 후 source 선택
6) 생성한 레포지터리를 구현하는 구현체를 생성하는데, 이때
QuerydslRepositorySupport를 상속받는다.public class ProductRepositoryCustomImpl extends QuerydslRepositorySupport implements ProductRepositoryCustom{ public ProductRepositoryCustomImpl() { super(Product.class); } @Override public List<Product> findList() { // 조인이 필요한 각 클래스들에 대한 객체 생성 QProduct product = new QProduct("product"); QProductImage productImage = new QProductImage("productImage"); QMember member = new QMember("member"); // QueryDSL 을 사용하기 위한 from 메서드 작성 List<Product> result = from(product) .leftJoin(product.productImageList, productImage).fetchJoin() .leftJoin(product.member, member).fetchJoin() // 중복제거를 위한 코드 추가 .fetch().stream().distinct().collect(Collectors.toList()); return result; }
7) 기존의 Product 레포지터리에서 생성한 ProductRepositoryCustom 을 상속받는다.
@Repository public interface ProductRepository extends JpaRepository<Product, Integer>, ProductRepositoryCustom { }
- 그다음 똑같이 ProductService 클래스에서 아래와 같이
findList()메서드를 사용하여 상품 List를 검색해보면 N+1 문제가 해결된 것을 확인할 수 있을 것이다.List<Product> result = productRepository.findList()
- 그다음 똑같이 ProductService 클래스에서 아래와 같이
-
그렇다면 이제 QueryDSL에서 페이징 기능을 추가해보겠다.
1) ProductRepositoryCustomImpl 클래스에 쿼리문을 추가해준다.// 페이징 기능 사용을 위한 쿼리 @Override public Page<Product> findList(Pageable pageable) { QProduct product = new QProduct("product"); QProductImage productImage = new QProductImage("productImage"); QMember member = new QMember("member"); List<Product> result = from(product) .leftJoin(product.productImageList, productImage).fetchJoin() .leftJoin(product.member, member).fetchJoin() .distinct() .offset(pageable.getOffset()) .limit(pageable.getPageSize()) .fetch().stream().distinct().collect(Collectors.toList()); return new PageImpl<>(result, pageable, result.size()); }
2) PrdocutService 클래스를 수정한다.
public BaseRes list(Integer page, Integer size){ // ✅ 추가 부분 Pageable pageable = PageRequest.of(page-1, size); Page<Product> productList = productRepository.findList(pageable); // 여기까지 List<GetProductListRes> getProductListResList = new ArrayList<>(); for(Product product : productList) { String fileName = ""; List<ProductImage> productImageList = product.getProductImageList(); for (ProductImage productImage : productImageList) { fileName += productImage.getImage() + ","; } fileName = fileName.substring(0, fileName.length()-1); GetProductListRes getProductListRes = GetProductListRes.builder() .idx(product.getIdx()) .name(product.getName()) .member_idx(product.getMember().getIdx()) .categoryIdx(product.getCategoryIdx()) .price(product.getPrice()) .salePrice(product.getSalePrice()) .deliveryType(product.getDeliveryType()) .isTodayDeal(product.getIsTodayDeal()) .filename(fileName) .like_check(false) .build(); getProductListResList.add(getProductListRes); } BaseRes baseRes = BaseRes.builder() .isSuccess(true) .code(1000) .message("요청 성공") .result(getProductListResList) .success(true) .build(); return baseRes; }
3) ProductController도 수정한다.
@RestController @RequiredArgsConstructor @RequestMapping("/product") @CrossOrigin("*") public class ProductController { private final ProductService productService; @RequestMapping(method = RequestMethod.GET, value = "/list") public ResponseEntity list(Integer page, Integer size) { return ResponseEntity.ok().body(productService.list(page, size)); }
- Postman으로 테스트해보면 아래와 같이 페이징 기능이 구현되고, N+1 문제도 해결되있는것을 확인할 수 있다.
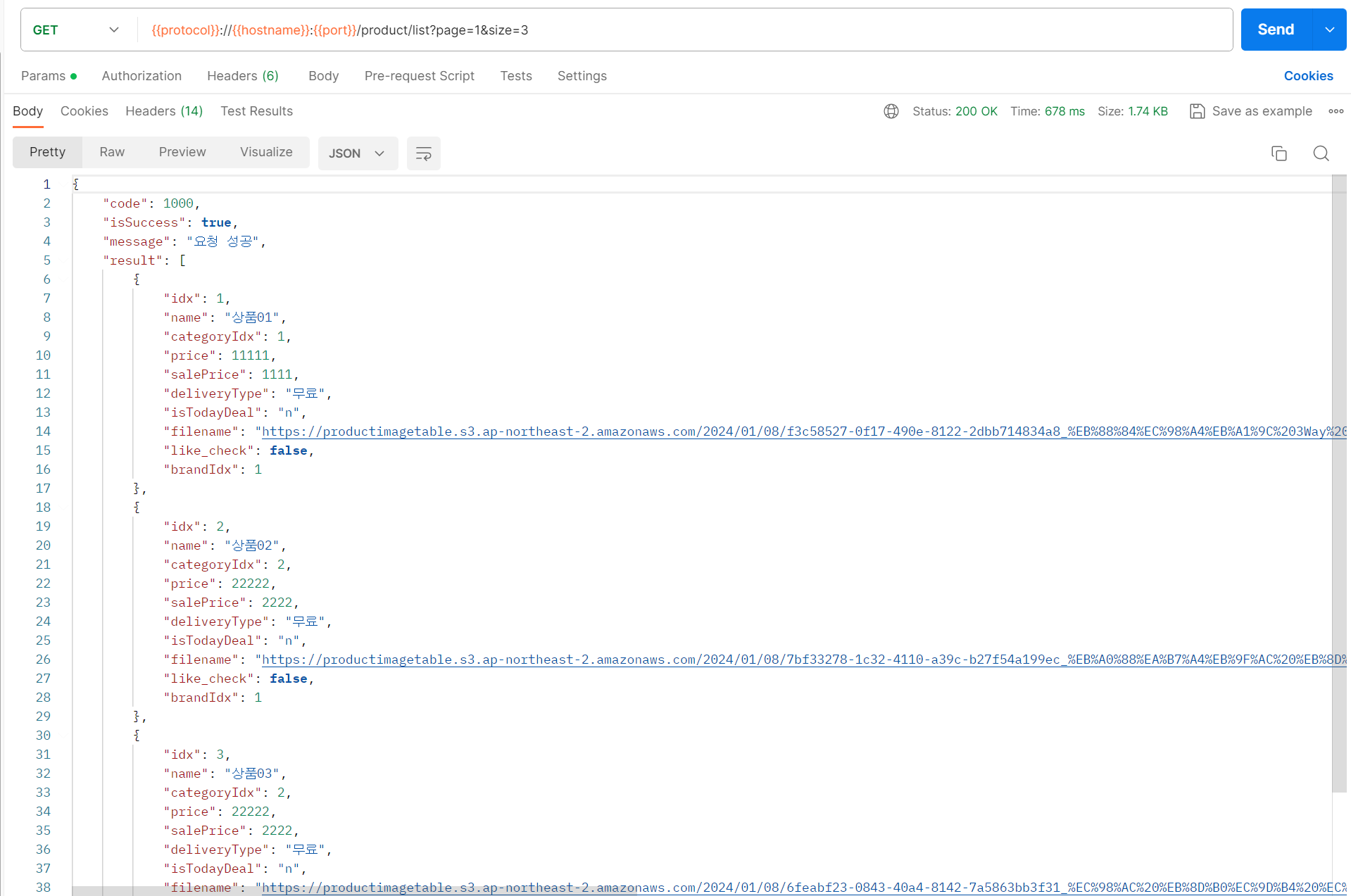
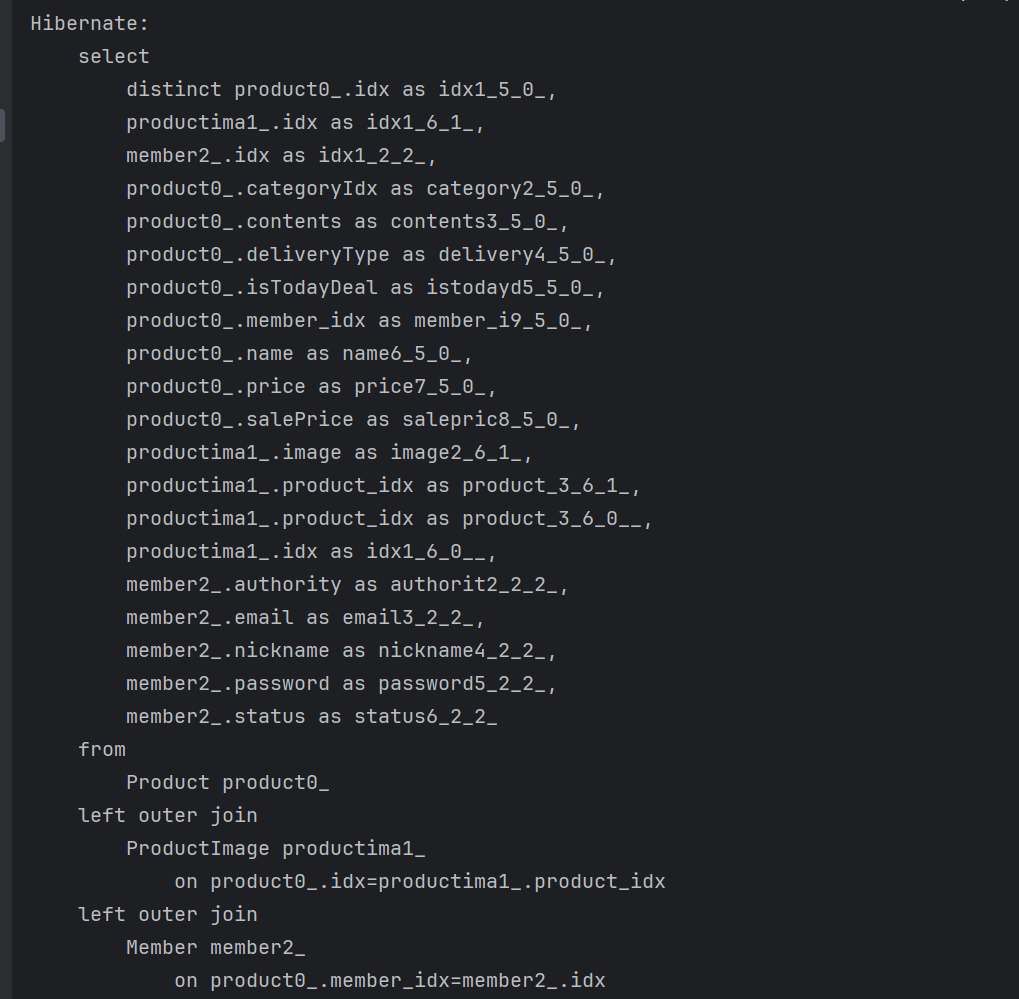
- Postman으로 테스트해보면 아래와 같이 페이징 기능이 구현되고, N+1 문제도 해결되있는것을 확인할 수 있다.
-
여기까지 JPQL 과 QueryDSL을 사용하여 N+1 문제를 해결하는 방법과 페이징 기능을 구현하는 것을 실습해봤다. 중요한 것은 무조건적으로 QueryDSL 을 사용하는게 좋다고 말할 수는 없는 것처럼 JPQL 이든 QueryDSL 이든 사용할때는 왜 그것을 사용하는지에 대한 이유를 생각해보고 사용해야 한다는 것을 기억해야 한다.
🐷 DB 성능 개선 - 2 ( 트랜잭션 처리 )
-
트랜잭션은 데이터베이스에서 논리적인 작업 단위를 말하는데, 쉽게 말해서 여러 개의 SQL 쿼리문을 하나의 작업으로 묶어서 처리하는 것을 말한다.
이러한 트랜잭션은 ACID 원칙을 따른다.1) 원자성 (Atomicity) : 트랜잭션의 모든 작업은 일괄적으로 수행되거나, 전혀 수행되지
않아야 한다는 특징. 즉, 트랜잭션 내의 모든 단계가 성공적으로
완료되면 커밋(Commit)이 수행되며, 하나라도 실패하면 롤백
(Rollback)이 발생하여 이전 상태로 되돌린다.2) 일관성 (Consistency) : 트랜잭션이 실행되기 전과 후에 데이터베이스는 일관된
상태를 유지해야 한다는 특징. 트랜잭션이 일부만 적용되고
중단되더라도 데이터베이스는 일관된 상태로 유지되어야 한다3) 고립성 (Isolation) : 여러 트랜잭션이 동시에 실행될 때, 각 트랜잭션은 다른
트랜잭션의 영향을 받지 않아야 한다는 특징.4) 지속성 (Durability) : 트랜잭션이 성공적으로 완료되면 그 결과는 영구적으로
저장되어야 한다는 특징. 시스템 장애 또는 다시 시작해도
트랜잭션의 결과는 손실되지 않아야 한다.
-
이 중에서 원자성과 고립성에 대해서 처리하는 것을 실습해 보겠다.
1) 원자성 (Atomicity) ✍
원자성은 간단하게 처리할 수 있는데 바로@Transactional어노테이션만 달아주면
된다.➡ 예를 들어, 상품을 등록한다고 할때 상품 정보는 상품 테이블에, 상품 이미지는 상품
이미지 테이블에 데이터를 순서대로 저장한다고 해보자.public void createProduct(PostProductReq postProductReq, MultipartFile[] uploadFiles) { Member member = (Member) SecurityContextHolder.getContext().getAuthentication().getPrincipal(); Product product = Product.builder() .member(member) .name(postProductReq.getName()) .categoryIdx(postProductReq.getCategoryIdx()) .price(postProductReq.getPrice()) .salePrice(postProductReq.getSalePrice()) .deliveryType(postProductReq.getDeliveryType()) .isTodayDeal(postProductReq.getIsTodayDeal()) .contents(postProductReq.getContents()) .build(); // ✅ 상품 테이블에 저장 Product result = productRepository.save(product); // ✅ 상품 이미지 테이블에 저장 for(MultipartFile multipartFile : uploadFiles) { String saveFileName = saveFile(multipartFile); productImageRepository.save(ProductImage.builder() .product(result) .image(saveFileName.replace(File.separator, "/")) .build()); } }
➡ 이때, 상품 테이블과 상품 이미지 테이블 모두 데이터가 저장되어야지만 정상적으로
상품 등록이 끝나는 것인데, 만약 상품에 대한 데이터는 제대로 저장되었는데, 상품
이미지 테이블에 이미지를 저장할 때 에러가 발생했다고 했을 때, 상품 테이블에 상품
정보가 저장되어 있으면 트랜잭션의 원자성이 깨진 것이다.➡ 상품 이미지 테이블까지 정상적으로 저장이 완료될때만 상품 테이블에도 데이터가
저장이 되어야 하고, 만약 하나라도 에러가 발생했다면 모든 쿼리문 자체가 취소
되어야 하는 것이다.
2) 고립성 (Isolation) ✍
고립성은 동시에 여러 트랜잭션이 수행될 때 발생하는 상황인데, 고립성을 해결하기 위한 방법은Lock이 있다.Lock이란? 여러 사용자들이 동시에 같은 데이터에 접근하는 상황에서 한 사용자가 데이터를 수정하는 동안에는 커밋이나 롤백 전까지 다른 사용자가 해당 데이터를 수정할 수 없도록 막는 역할, 즉 잠가놓는 것을 말한다.
Lock의 종류 중 "비관적 락" 과 "낙관적 락" 에 대해 실습해보겠다.
1) 비관적 락 (Pessimistic Lock) 🧐
➡ 동일한 데이터를 동시에 수정할 가능성이 높다는 관점으로 잠금을 거는 기법
➡ 예를 들어, 상품의 재고는 동시에 같은 상품을 여러명이 주문할 수 있기 때문에
데이터 수정에 의한 경합이 발생할 가능성이 높다고 비관적으로 보는 것
➡ 이 경우 충돌감지를 통해 잠금을 발생시키면, 충돌발생에 의해서 예외가 자주
발생한다.
➡ 이럴 경우 비관적 락을 통해서 예외를 발생시키지 않고, 정합성을 보장하는 것이
가능하다.장점 : 충돌이 잦은 환경에서는 롤백을 줄일 수 있어 성능상 유리하며, 데이터
무결성을 보장할 수 있다단점 : 레코드 자체에 락을 걸기 때문에 동시 처리 시 성능상 손해를 볼 수 있다.
서로 자원이 필요한 경우데드락(교착상태)이 일어날 가능성이 존재한다
비관적 락에는공유 락(Shared Lock)과배타적 락(Exclusive Lock)이
있다.➡ 데드락(교착상태) : 멀티스레드 환경에서 두 개 이상의 작업이 서로 상대방의
작업이 끝나기만을 기다리고 있어서, 결과적으로 아무것도
완료되지 못하는 상태
➡ 공유 락 : 데이터를 동시에 Read 하는 것은 가능하지만, Write 는 불가능
➡ 배타적 락 : 트랜잭션이 끝나는 시간동안 Read/Write 불가
-
상품의 좋아요 기능을 통한 실습하기
✅ Product 엔티티에 "좋아요 수" 추가
@Entity @Getter @Setter @AllArgsConstructor @NoArgsConstructor @Builder public class Product { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Integer idx; @OneToMany(mappedBy = "product", fetch = FetchType.LAZY) private List<ProductImage> productImageList = new ArrayList<>(); @OneToMany(mappedBy = "product", fetch = FetchType.LAZY) private List<Cart> cartList = new ArrayList<>(); @OneToMany(mappedBy = "product", fetch = FetchType.LAZY) private List<OrdersProduct> ordersProductList = new ArrayList<>(); @ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "member_idx") private Member member; private Integer likeCount; // "격리성" 실습을 위한 좋아요 수 public void increaseLikeCount() { this.likeCount = this.likeCount + 1; } private String name; private Integer categoryIdx; private Integer price; private Integer salePrice; private String deliveryType; private String isTodayDeal; private String contents; }
✅ LikesService 클래스
@Service @RequiredArgsConstructor public class LikesService { private final ProductRepository productRepository; @Transactional public void likes(Member member, Integer idx) { Optional<Product> result = productRepository.findByIdx(idx); if(result.isPresent()) { Product product = result.get(); product.increaseLikeCount(); product = productRepository.save(product); } } }✅ LikesController 클래스
@RestController @RequiredArgsConstructor @RequestMapping("/likes") public class LikesController { private final LikesService likesService; @RequestMapping(method = RequestMethod.GET, value = "/{idx}") public ResponseEntity likes(@AuthenticationPrincipal Member member, @PathVariable Integer idx) { likesService.likes(member, idx); return ResponseEntity.ok().body("ok"); } }
-
-
이제 동시에 요청을 보내야 하는데, 동시에 요청 보내는 것을 테스트하는 방법은 아래와 같다.
1) 포스트맨에서 오른쪽 </> 표시 클릭 후 Powershell RestMethod 에 있는 코드 복사
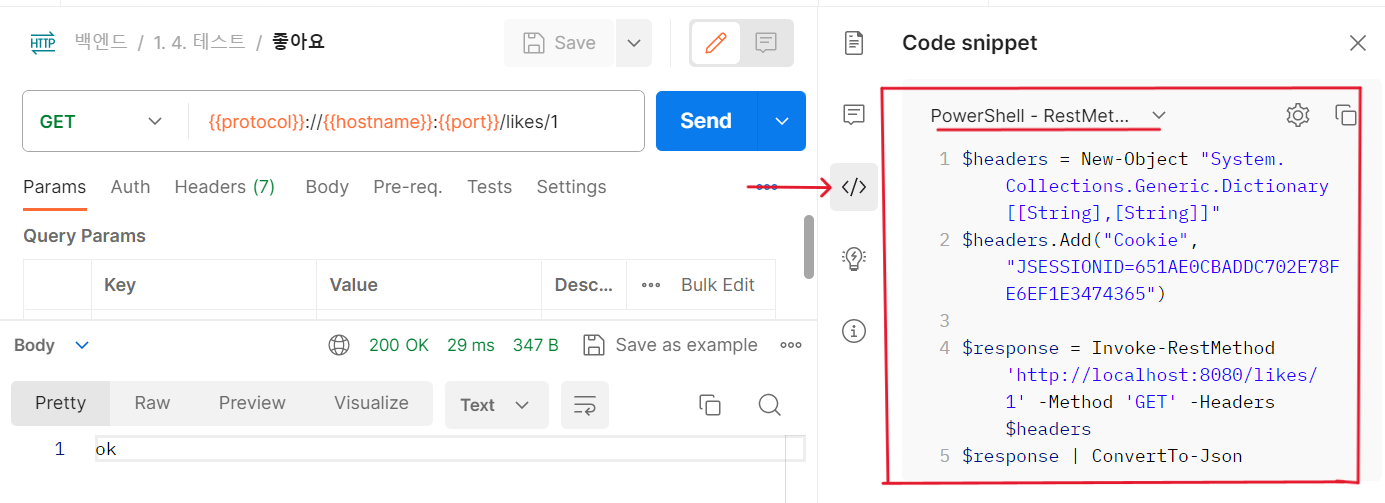
2) 인텔리제이에서 디버깅 걸어놓고, 디버깅 오른쪽 클릭 "Thread" 선택
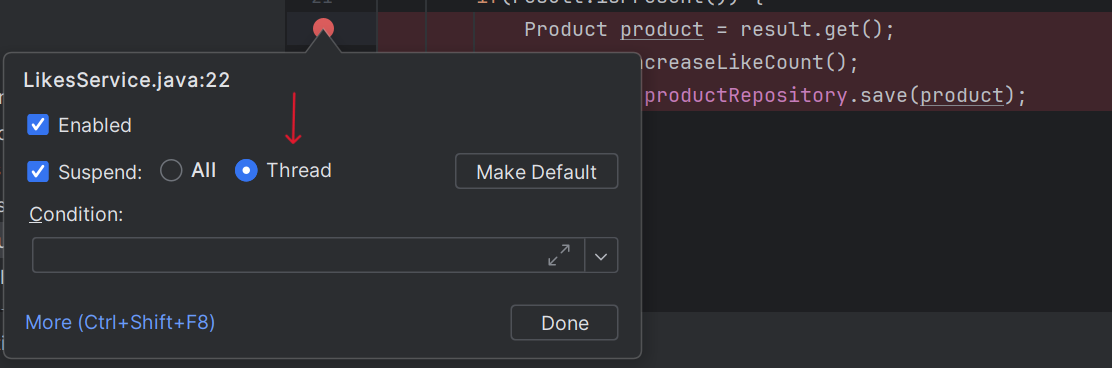
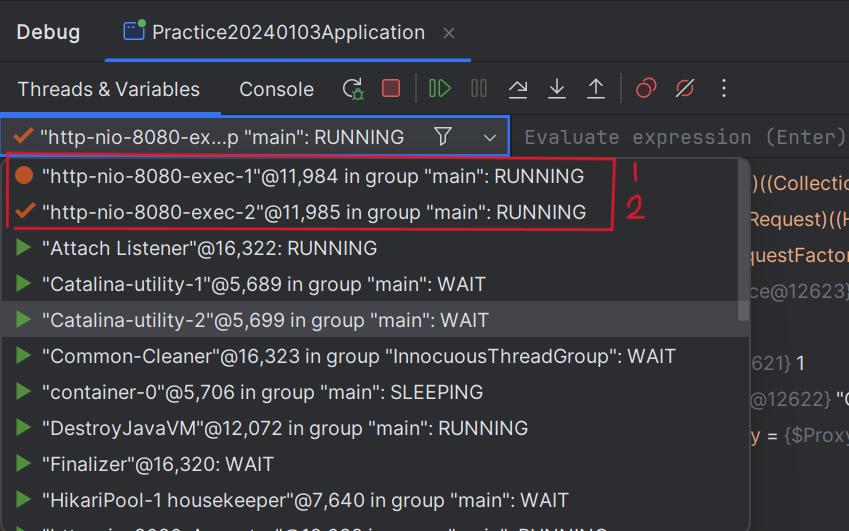
3) 윈도우에서 PowerShell 검색 후 실행, 2개 실행 후 포스트맨에서 복사한 코드
각각 붙여넣기 해보면 2개가 동시에 요청이 들어온 것이 된다.
-
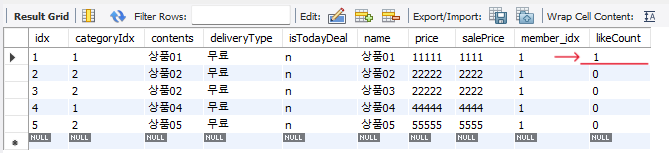
요청을 수행했을때, 정상적이라면 좋아요 수가 2가 증가해야될 것이다. 하지만 실제로 확인해보면 좋아요 수가 1만 증가한 것을 확인할 수 있을 것이다. 이러한 것이 트랜잭션의 고립성이 깨진 것이다.
-
이러한 트랜잭션의 고립성을 지키기 위해서 먼저 비관적 락을 설정해줘보겠다.
➡ 비관적 락은 레포지터리에서 아래와 같이 설정해줄 수 있다.@Repository public interface ProductRepository extends JpaRepository<Product, Integer>, ProductRepositoryCustom { // ✅ 비관적 락 설정 ( 읽기 일때는 PESSIMISTIC_READ 로 설정 ) @Lock(LockModeType.PESSIMISTIC_WRITE) public Optional<Product> findByIdx(Integer idx); }➡ 다시 똑같이 2개의 요청을 보내보면, 이번에는 디버깅에도 1개의 요청이 먼저 들어와
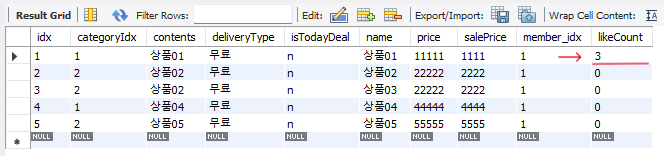
있고, 이 요청에 대한 처리가 끝나고 다음 요청이 들어오는 것을 확인할 수 있다.
또한, 좋아요 수가 정상적으로 2개 증가한 것을 확인할 수 있을것이다.
-
위의 내용을 MySQL Workbench 에서 확인해보겠다.
➡ DB에 대한 사용자를 1명 더 추가하여 총 2개의 연결을 시켜놓는다.
➡ 실습을 위해 먼저 "AUTOCOMMIT" 설정을 꺼준다 :SET AUTOCOMMIT = 0;
➡ 아래의 코드를 한 줄씩 실행할 예정이다.
1) START TRANSACTION;
2) SELECT * FROM Product WHERE idx=1;
3) UPDATE Product SET likeCount = likeCount + 1 WHERE idx=1;
4) COMMIT;➡ 먼저 1번 사용자가 1, 2번 실행 하고 / 2번 사용자가 1, 2번을 실행 한 뒤
1번 사용자가 3번 실행, 2번 사용자도 3번 실행 후 각각 커밋을 실행시켜본다.
그러면 문제없이 진행되어 좋아요 수가 2 증가할 것이다.➡ 이번엔 2번의 마지막에
FOR UPDATE를 추가해준 뒤, 1번 사용자가 1번 실행,
2번 사용자가 1번 실행 후 1번 사용자가 2번 실행, 2번 사용자가 2번 실행 해본다.➡ 그러면 2번 사용자는 아래와 같이
running이라고 떠있고, 일정 시간이 지나면
Lost Connection이라고 뜨면서 에러코드가 뜰 것이다.


➡ 이런 상황을 바로 데드락(교착 상태) 라고 한다. 일정 시간 기다리다가 연결 자체가
아예 끊겼기 때문이다. 그 이유는 1번 사용자가 락을 걸어 놓은 뒤 아직 트랜잭션
작업이 끝나지 않았기 때문에 2번 사용자는 1번 사용자의 작업이 끝날때까지 계속
기다리고 있을 수 밖에 없다.➡ 이처럼 비관적 락은 한 개씩 락을 걸었다 풀었다를 반복하기 때문에 동시 요청이
많으면 많을수록 성능이 저하될 수 있다는 단점이 있지만, 데이터가 절대 누락되지
않는다는 장점이 있다.
2) 낙관적 락(Optimistic Lock) 🧐
➡ 현실적으로 데이터 갱신 시 경합이 발생하지 않을 것이라고 보고 잠금을 거는 기법
➡ 예를 들어, 회원 정보 수정과 같은 경우는 회원 본인에 의해서 수정이 이루어지기
때문에 동시에 여러 요청이 발생할 가능성이 낮다.➡ 따라서 수정이 이루어진 경우를 감지해서 예외를 발생시켜도 실제로 예외가
발생할 가능성이 낮다고 낙관적으로 보는 것으로 잠금보다 충돌감지(Conflict
Detection)에 가깝다.장점 : 동시 요청에 대해 처리 성능이 좋다.
단점 : 충돌이 자주 일어나면 롤백이 자주 일어나 비용이 많이 들어 오히려 성능상
손해를 볼 수 있으며, 롤백 처리를 구현하는게 복잡할 수 있다.
➡ 낙관적 락은 버전을 설정한 뒤, 만약 동시에 요청한 것이 반영이 안될 때는 에러를
발생시켜서 예외처리를 해주는 방식이다.
1) 레포지터리에서 설정해준다.
@Repository
public interface ProductRepository extends JpaRepository<Product, Integer>, ProductRepositoryCustom {
// 비관적 락
@Lock(LockModeType.PESSIMISTIC_WRITE)
public Optional<Product> findByIdx(Integer idx);
// ✅ 낙관적 락
@Lock(LockModeType.OPTIMISTIC)
public Optional<Product> findByIdx(Integer idx);
} 2) 엔티티 클래스에서 버전을 설정해준다.
@Version // 낙관적 락을 걸어 주기 위한 것
private Integer likeCount; // "격리성" 실습을 위한 좋아요 수-
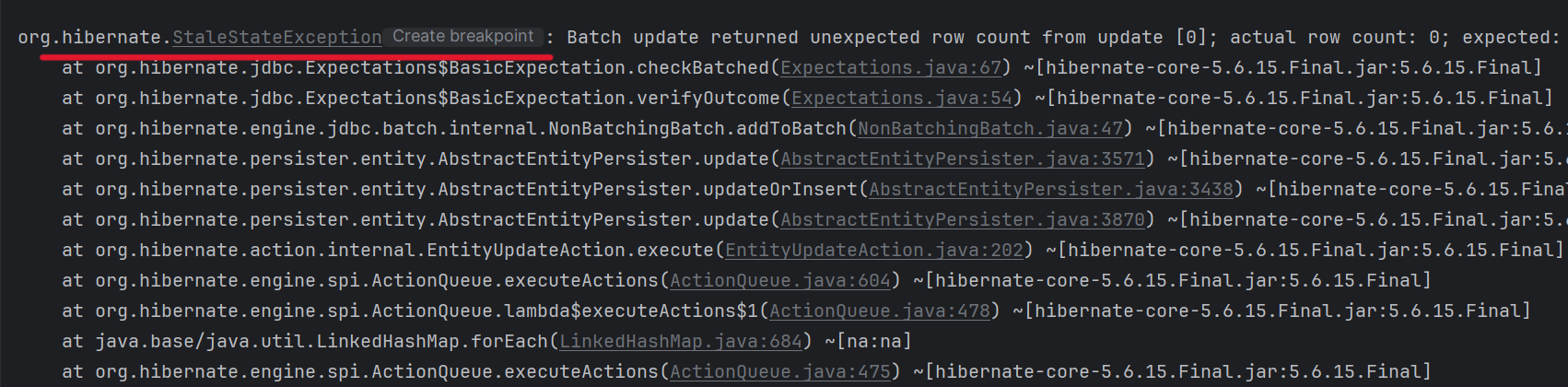
그런다음, 동시에 요청을 2개 보내보면 1개는 정상적으로 실행되고, 그 다음 요청을 처리할 때 아래와 같이 에러(StaleStateException)가 발생하는 것을 확인할 수 있으며, 좋아요 수를 확인해봐도 1만 증가하였다.
-
따라서 이러한 에러를 처리하기 위해 LikesController 클래스에 예외처리를 아래와 같이 추가해 줄 수 있다.
@RestController
@RequiredArgsConstructor
@RequestMapping("/likes")
public class LikesController {
private final LikesService likesService;
@RequestMapping(method = RequestMethod.GET, value = "/{idx}")
public ResponseEntity likes(@AuthenticationPrincipal Member member, @PathVariable Integer idx) {
try {
likesService.likes(member, idx);
} catch (Exception e) {
System.out.println("동시성 에러 발생");
}
return ResponseEntity.ok().body("ok");
}
}-
그러면, 이전과 동일하게 2개의 요청을 보냈을 때 아래와 같이 에러가 처리되어 있다.

-
만약, 좋아요 수를 2 증가시키고자 한다면
catch 부분에서 likes 메서드를 한번 더 실행하면 가능은 하다. 하지만, 이렇게 하면 비관적 락과 마찬가지로 요청이 많아지면 많아질수록 성능이 느려질 것이다. -
따라서, "비관적 락" 과 "낙관적 락" 에 대한 적절한 선택이 필요하다. 예를 들면, 예금과 같은 중요한 데이터에 대해서는 데이터가 누락되면 안되기 때문에 비관적 락을 사용해야될 것이고, 상품의 좋아요 수와 같은 것은 사실상 데이터가 누락된다고 크게 영향을 미치는 것은 아니기 때문에 낙관적 락을 걸어줄 수 있을 것이다.
-
낙관적 락이 SQL 쿼리문에서 동작하는 원리는 아래와 같다.
# Thread 1이 Product를 조회 (version 1)
SELECT * FROM Product WHERE idx=1;
# Thread 2이 Product를 조회 (version 1)
SELECT * FROM Product WHERE idx=1;
# Thread 1이 Product를 수정 (version 2)
UPDATE Product SET likeCount = likeCount + 1, version = version + 1 WHERE idx=1 AND version = 1;
# Thread 2이 Product를 수정 (version 1) => version 1이 없어져서 에러가 발생 🔥
UPDATE Product SET likeCount = likeCount + 1, version = version + 1 WHERE idx=1 AND version = 1; DB Replication(Master-Slave) 구성 후 스프링 부트에서 연결하기
1) application.yml 파일에서 datasource 부분 수정하기
// 기존
datasource:
url: jdbc:mysql://77.77.77.111/shop
username: test01
password: qwer1234
driver-class-name: com.mysql.cj.jdbc.Driver
// ✅ Master - Slave 구성을 위한 수정
datasource:
master:
hikari:
username: test01
password: qwer1234
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://77.77.77.111/master
slave:
hikari:
username: slave01
password: qwer1234
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://77.77.77.112/master2) DataSource를 Bean으로 등록해주기 위해 Config 클래스를 생성
@Configuration
public class DataSourceConfig {
public static final String MASTER_DATASOURCE = "masterDataSource";
public static final String SLAVE_DATASOURCE = "slaveDataSource";
@Bean(MASTER_DATASOURCE)
// application.yml 파일에서 prefix로 지정한 이름으로 시작하는 값들을 전부 불러오는 어노테이션
@ConfigurationProperties(prefix = "spring.datasource.master.hikari")
public DataSource masterDataSource() {
return DataSourceBuilder.create()
.type(HikariDataSource.class)
.build();
}
@Bean(SLAVE_DATASOURCE)
@ConfigurationProperties(prefix = "spring.datasource.slave.hikari")
public DataSource slaveDataSource() {
return DataSourceBuilder.create()
.type(HikariDataSource.class)
.build();
}
@Bean
@Primary
// 위에서 설정한 MASTER_DATASOURCE와 SLAVE_DATASOURCE를 빈으로 등록한 뒤
// 아래 메서드를 빈으로 등록하라는 어노테이션
@DependsOn({MASTER_DATASOURCE, SLAVE_DATASOURCE})
public DataSource routingDataSource(
// 어떤 빈으로 등록하는지 빈의 이름을 적어주는 어노테이션
@Qualifier(MASTER_DATASOURCE) DataSource masterDataSource,
@Qualifier(SLAVE_DATASOURCE) DataSource slaveDataSource) {
// 맵을 생성하여 KEY-VALUE 에 DataSource를 등록해준다.
RoutingDataSource routingDataSource = new RoutingDataSource(
Map.of("master", masterDataSource, "slave", slaveDataSource),
masterDataSource
);
// 트랜잭션 처리가 끝난 상태에서 DataSource 객체를 받아가기 위한 설정
// 만약 설정하지 않으면, 읽기 전용인지 쓰기 전용인지 처리가 안끝난 상태에서 받아가기 때문에
// 항상 master 서버를 받아가게 된다.
return new LazyConnectionDataSourceProxy(routingDataSource);
}
}3) 라우팅을 해주는 클래스를 만들고, AbstractRoutingDataSource를 상속받는다.
public class RoutingDataSource extends AbstractRoutingDataSource {
public RoutingDataSource(Map<Object, Object> targetDataSources, Object defaultTargetDataSource) {
super.setTargetDataSources(targetDataSources);
super.setDefaultTargetDataSource(defaultTargetDataSource);
afterPropertiesSet(); // InitializingBean을 구현하므로 스프링이 빈을 초기화할 때 호출됨
}
@Override
protected Object determineCurrentLookupKey() {
Boolean test = TransactionSynchronizationManager.isCurrentTransactionReadOnly();
if(test) {
// readOnly가 true면 slave
return "slave";
} else {
// readOnly가 false면 master
return "master";
}
}
}-
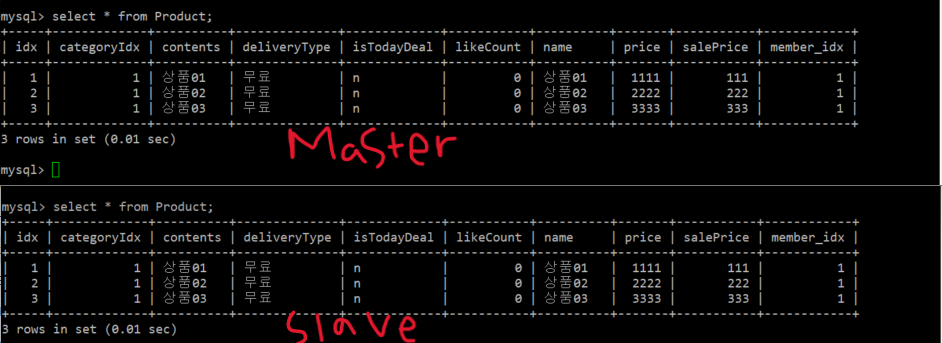
DB 서버 2대를 Master-Slave로 구성해준 뒤 마스터 서버에서 상품 테이블에 데이터를 3개 넣어본다. 그러면 아래와 같이 Master와 Slave 서버에 동일하게 상품 데이터가 들어있게 된다.
-
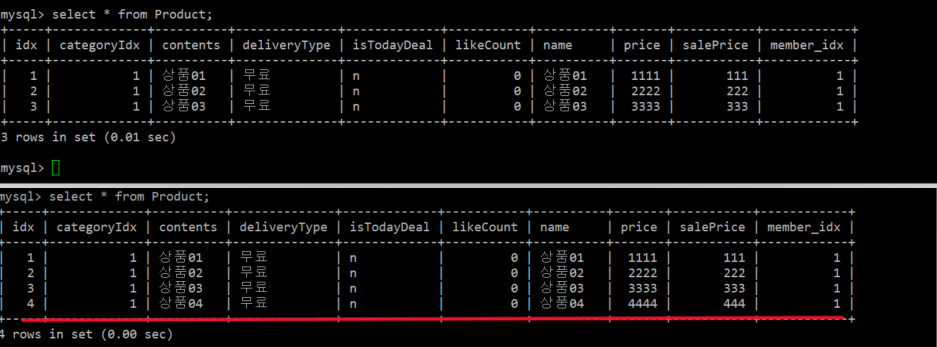
다음으로 테스트를 위해 Slave 서버에만 상품 데이터를 1개 추가 해보겠다.
-
그런다음 상품 List 출력 메서드에
@Transactional(readOnly = true)달아준 뒤 상품의 List를 검색해보면 Slave 서버에 연결되어 상품 4개가 검색되는 것을 확인할 수 있다. -
DB Replication 구성과 트랜잭션 처리에 관한 조금 더 구체적인 내용은
"에러 정리 시리즈" 에서 다시 작성해보겠다.
