
Parts Of Speech
- parts of speech are categories of word defined distributionally by the morphological and syntactic contexts a word appears in. -> POS는 words의 category 분류인데, 형태학적, 문법적인 기준도 기준으로 들어간다.
Morphological distribution
- POS often defiend by distributional properties; verbs = the class of words that each combine with the same set of affixes.
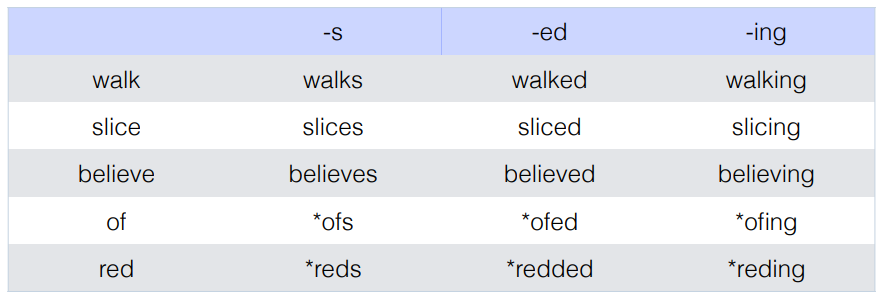
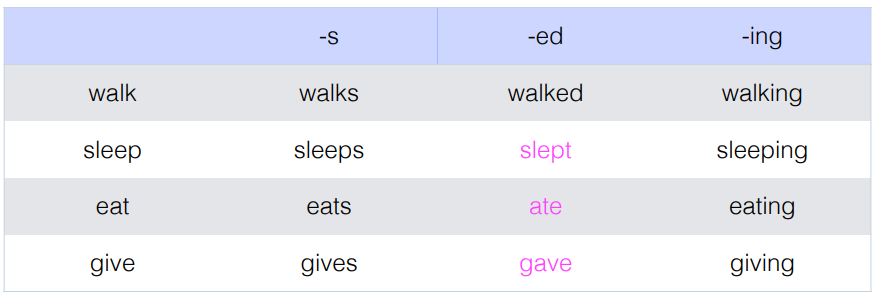
Syntatic distribution
- Subsitution test : if a word is replaced by another word, does the sentence remain grammatical?

- These can often be too strict ; some contexts admit subsitutability for som pairs but not others.
POS
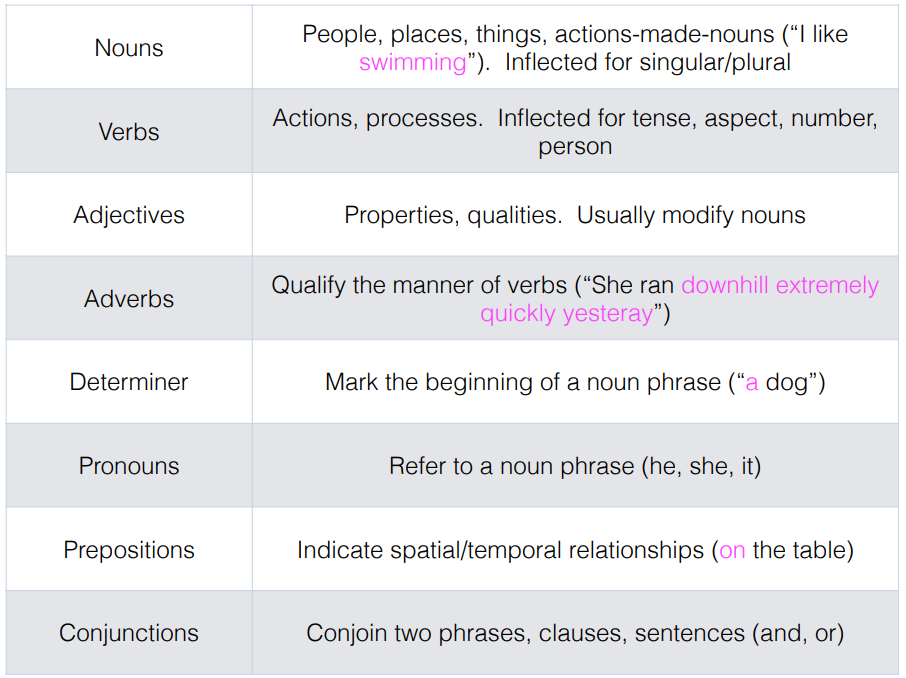
- OOV -> Out Of Vacabulary , training set 에 존재하지 않는 새로운 단어도 예측
POS tagging
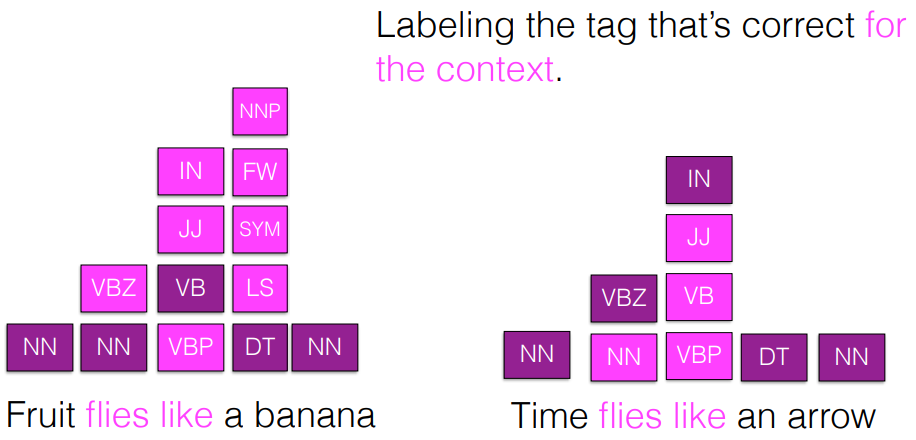
- state of the art
- 같은 형태여도 news 냐 literature 냐 등의 domain에 따라 달랐다.
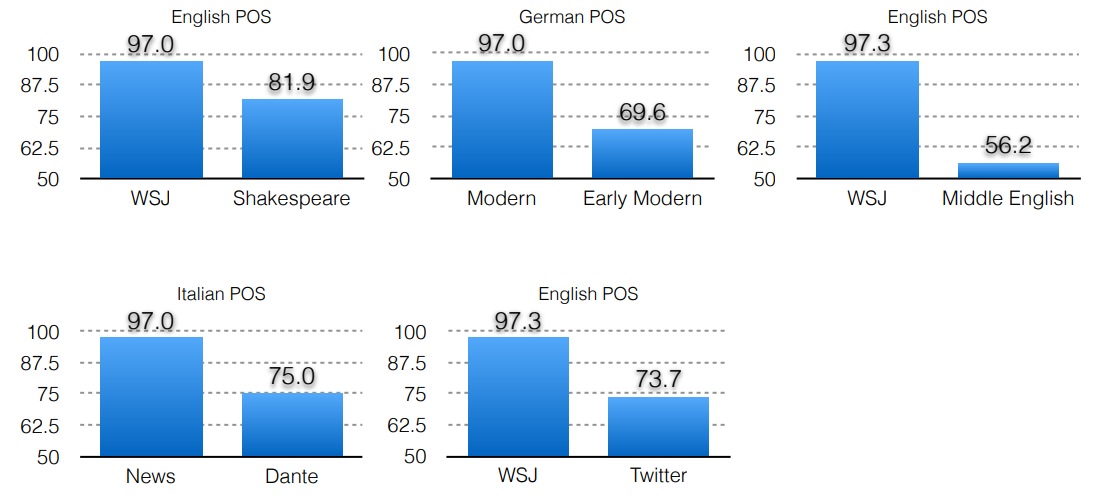
Why is POS tagging useful?
- POS indicative of syntax (문법의 척도)
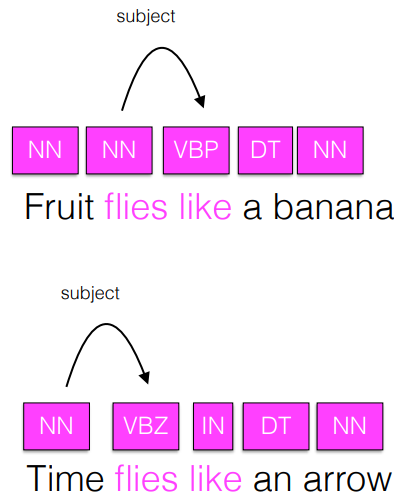
- POS is indicative of pronunciation (발음의 척도) : 예 ; 음성인식
Tagsets
- Penn Treebank
- Universal Dependencies
- Twitter POS
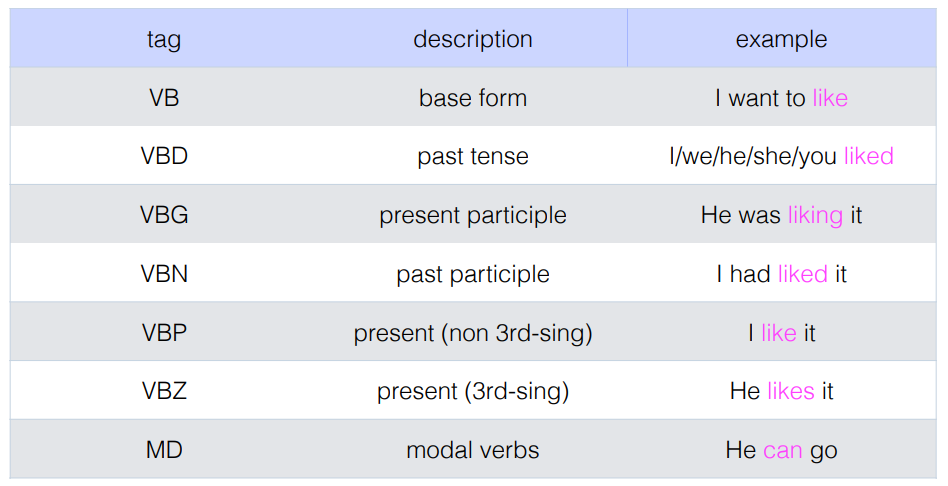
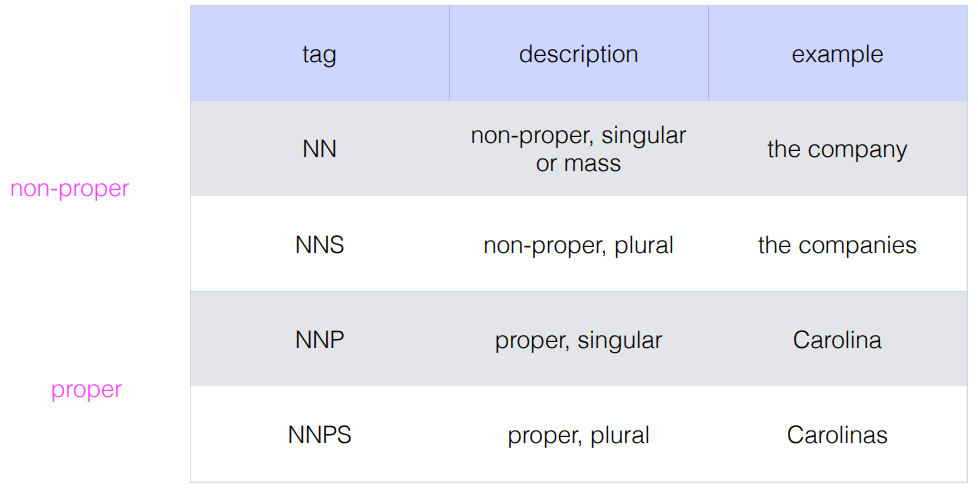
- 관사 같은 경우에는 Stop words 를 이용해서 관사를 제외하기도 한다. 아무런 의미없이 개수가 많기 때문이다.
Sequence labeling
- For a set of inputs x with n sequential time step, one corresponding label y for each x
1) 고전적인 방법 : HMM, HEMM, CRF -> 우리는 간단하게 HMM만 알아볼 것
2) Neural Network : RNN, LM, Transformer
Named entity recognition
- wikipedia 에 등장할 만큼 상징적인 것
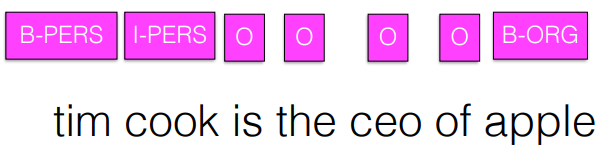
- Named entity 를 하면 apple 이 사과가 아니라 회사라는 걸 알고, 더 많은 정보를 알려줄 수 있으므로 Named entity를 한다. ( Entity Labeling )
HMM
- 단순히 확률로만 판단
- Pick the label each word is seen most often with in the training data
Sequences
- 순서가 있는 데이터에 어떻게 확률분포를 구할 것인가?
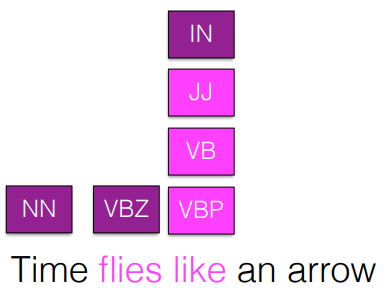

[참고]
Generative vs. Discriminative models
Generative models specify a joint distribution over the labels and the data. With this you could generate new data
P( x, y ) = P( y ) P( x | y )
Naive Bayes, HMM, GAN
-> 확률분포를 찾자!
Discriminative models specify the conditional distribution of the label y given the data x. These models focus on how to discriminate between the classes.
P ( y | x )
->logistic regression, RNN, softmax
-> 이진분류 모델을 학습시키자!
HMM
- HMM은 Generative 모델
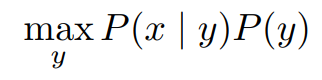
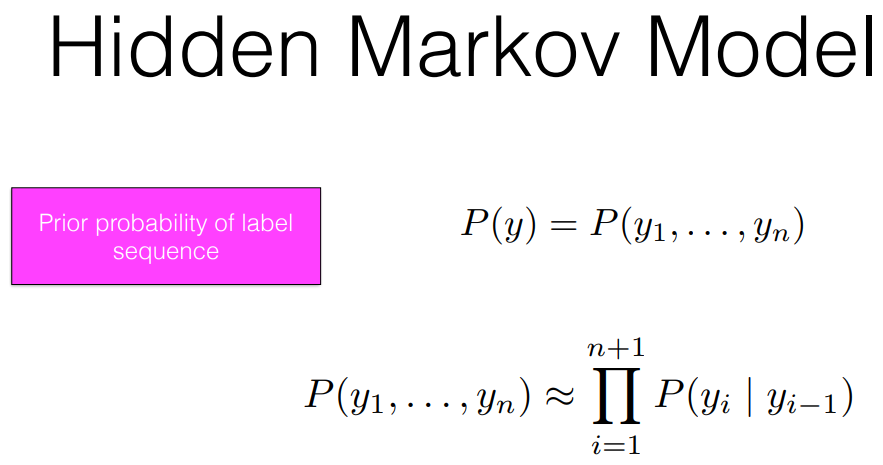
[Hidden Markov Model : HMM의 기본이론]
- Markov Assumption - 이전 혹은 직전의 Context는 현재를 반영한다.
- output Independent - 현재의 y는 x에 영향을 준다.
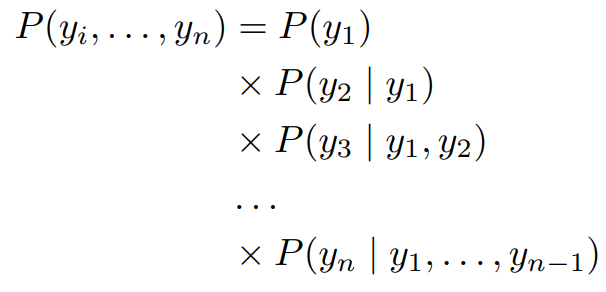
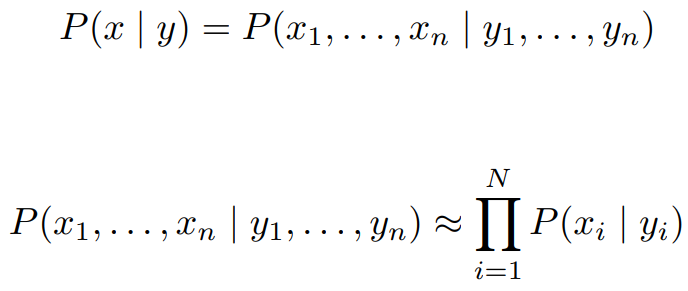
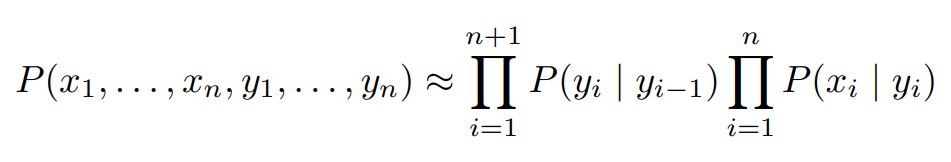
- P(y)P(x|y)
- P(y) : label 끼리의 관계
- P(x|y) : 현재 label과 현재 word의 관계
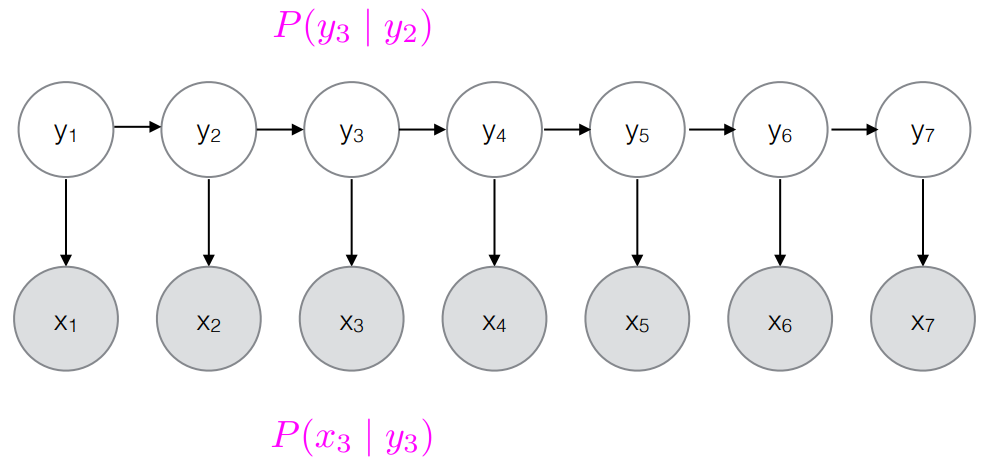
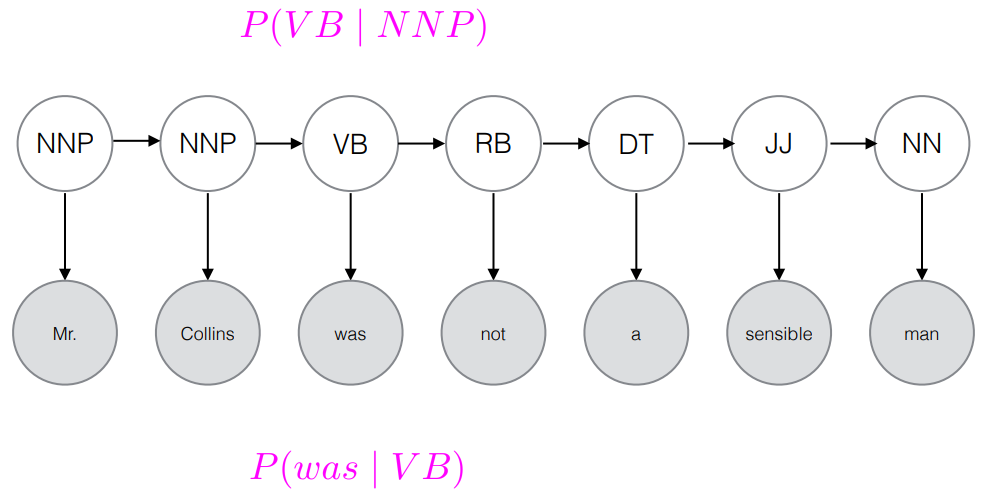
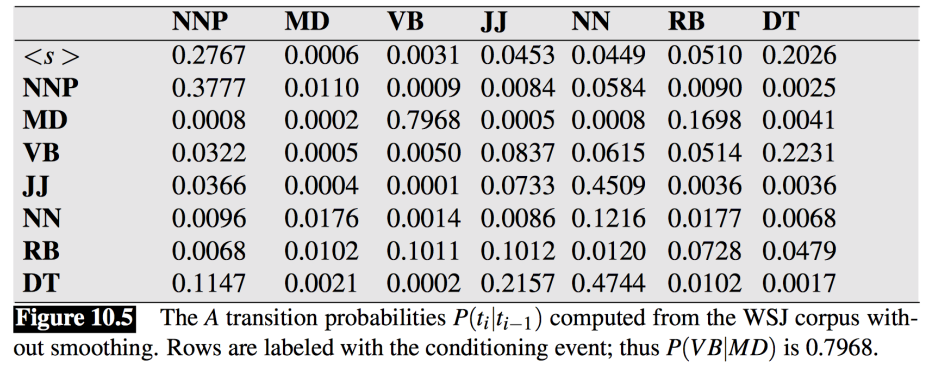
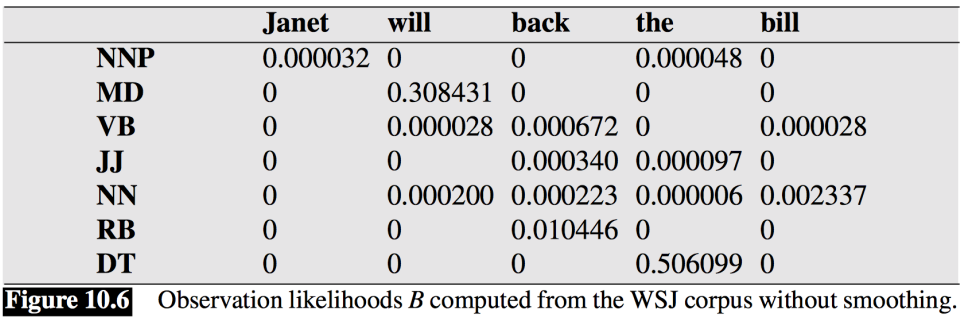
- 이미 확률이 다 계산되어 있다.
Decoding
- Greedy : proceed left to right, committing to the best tag for each time step (given the sequence seen so far)

- Information later on in the sentence can influence the best tags earlier on. -> 이미 best 라고 구했던 tag 가 다른 문장 요소에 영향을 줄 수 있다.
- Ideally, what we want is to calculate the joint probability of each path and pick the one with the highest probability. But for N time steps and K labels, number of possible paths = KN

데이터사이언스와 자연어처리를 공부하고 있습니다.