
Vector semantics
-
"You shall know a word by the company it keeps"
- 문맥(context)에 의해서 단어를 파악한다. -
앞서 봤던 모델들에 넣는 벡터를 어떻게 만드는지 생각해보자
Distributed representation (<-> one - hot vector)
- Vector representation that encodes information about the distribution of context a word appears in
- Words that appear in similar contexts have similar representations -> 비슷한 문맥은 비슷한 representation 을 가진다.
- We have several different ways we can encode the notion of "context"
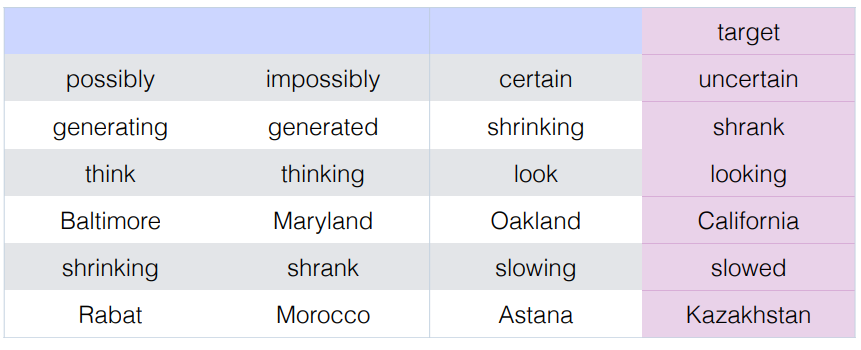
Term - document matrix


Cosine Similarity
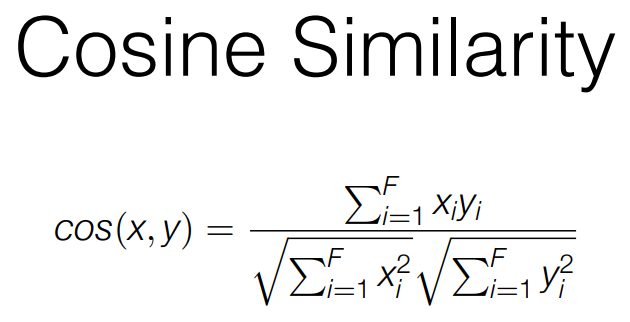
- We can calculate the cosine silmilarity of two vectors to judge the degree of their similarity
- Euclidean distance measures the magnitude of distance between two points
- Cosine similarity measures their orientation
- Cosine similarity 가 0.7 ~ 0.8 정도면 비슷한 단어라고 할 수 있다.
- -1 : 역방향 일치, 0 : 불일치, 1 : 일치
TF - IDF
- Term frequency -inverse document frequency ( TF-IDF )
- A scaling to representation a features as function of how frequently it appears in a data point but accounting for its freqency in the overall collection -> 예를 들어, a와 the 같은 관사는 별의미는 없는데 여러 문서에 많이 등장하기는 한다.
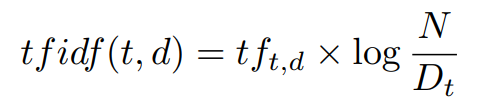
- like 는 별의미가 없지만 정보가 없지만 문서에 많이 등장한다. 즉, 특정 문서를 구분할 단서가 되지 않기 때문에 like 에 대한 정보를 떨어트린다. 즉, IDF를 0으로 만들어버린다.
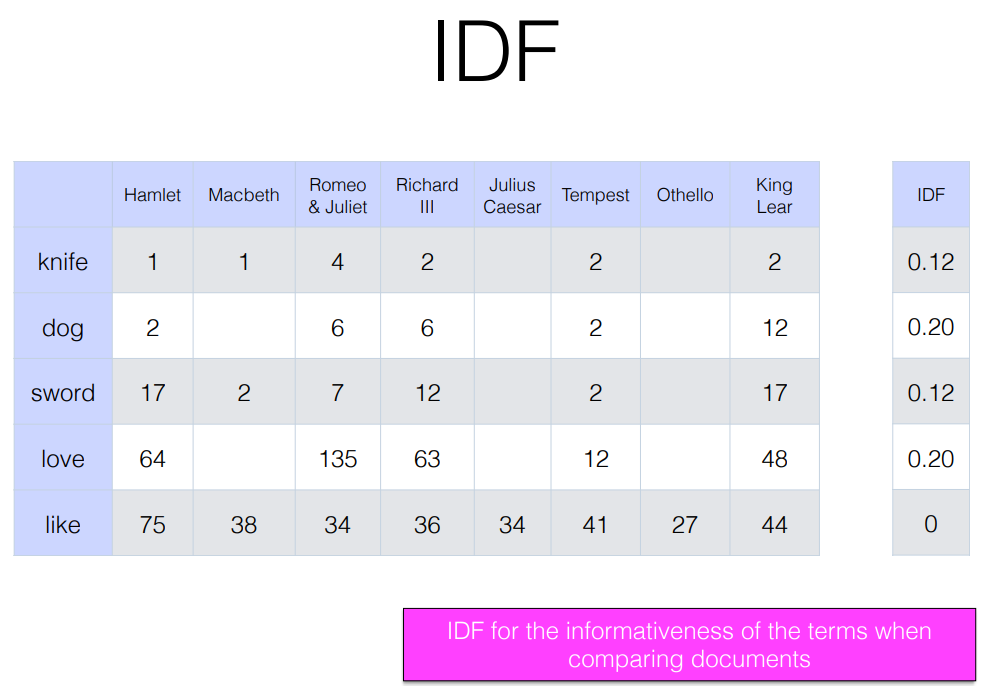
Intrinsic Evaluation
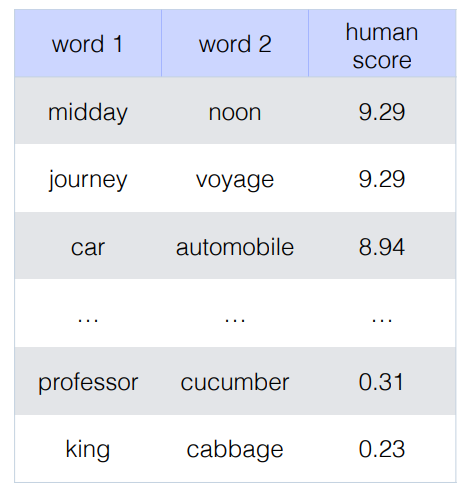
- Relatedness : correlation between vector similarity of pair of words and human judgments -> vector similarity 와 human judgment 두 벡터의 연관성을 분석한다.
- Analogical reasoning (Mikolov et al. 2013). For analogy Germany : Berlin :: France : ???, find closest vector to v("Berlin") - v("Germany") + v("France")
Sparse vectors -> Dense vectors (Word embedding)
- Learning low-dimensional(약 50~300차원) representations of words by framing a predicting task : using context to predict words in a surrounding window
- Transform this into a supervised prediction problem; similar to language modeling but we're ignoring order whitin the context window
Dense vectors from prediction
- skipgram model(Mikolov et al. 2013) : give a single word in a sentence, predict the words in a context window around it.
- 먼저 임의의 값으로 벡터들을 초기화한 후, 특정 단어가 주어졌을 때 그 주변 단어들의 등장 확률을 증가시키는 방향으로 학습하는 알고리즘이다. 가량 I love him but he hates me. 라는 문장을 생각해보자. 여기서 him 이라는 단어를 기준으로 앞 뒤 두 단어들인 I, love, but, he의 발생 확률을 증가시키는 방향으로 학습하게 된다. ( 여기서 앞 뒤 두 단어라고 했으니 window size = 2 이다. )
- 비슷한 문맥에서 등장하는 context -> skip-gram 등의 방법으로 word embedding 을 만든다. -> 비슷한 context 는 비슷한 vector 값을 가지게 된다.

- Mikolov et al. 2013 show that vector representations have some potential for analogical reasoning through vector arithmetic ( = Analogical inference = analogy reasoning )
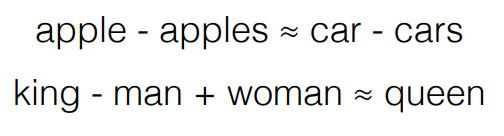
Low - dimensional distributed representation
- Low-dimensional, dense word representations are extradrdinarily powerful
- Lets your representation of the input share statistical strength with words that behave similarly in terms of their sidtributional properties (often synonyms or words that belong to the same class)
Two kinds of training data
- The labeled data for a specific task (e.g., labeled sentiment for movie reviews) : 2K labels/reviews, ~ 1.5M words-> used to train a supervised model
- General text ( Wikipedia, the web, books, etc .), -> ~trillions of words -> used train word distributed representation
using dense vectors
- In neural models (CNNs, RNNs, LM), replace the V-demensional sparse vector with the much smaller K-dimensional dense one.
- Can alse take the derivative of the loss function with respect to those representations to optimize for a paricular task. -> dense vector로 특정 task 를 최적화하기 위해서 손실함수를 미분할 수도 있다.

데이터사이언스와 자연어처리를 공부하고 있습니다.