U-BERT: Pre-training User Representations for Improved Recommendation
논문
코드
- 공개코드 없음
참고자료
- 없음
문제의식
- Building the recommendation system for a particular domain only use the domain
- Domain where the behavior data is insufficient to learn user representations : hurt performance
아이디어
- model user's commenting habits in the domain A and applied them to domain B : better Recommendation

학습
-
pre-training(content-rich domains) → fine-tuning(target content-insufficient domains)
-
Review Encoder : multi-layer Transformer / User Encoder : fusion - attention
-
combines 1. user representations, 2. item representations, 3. review interaction information
-
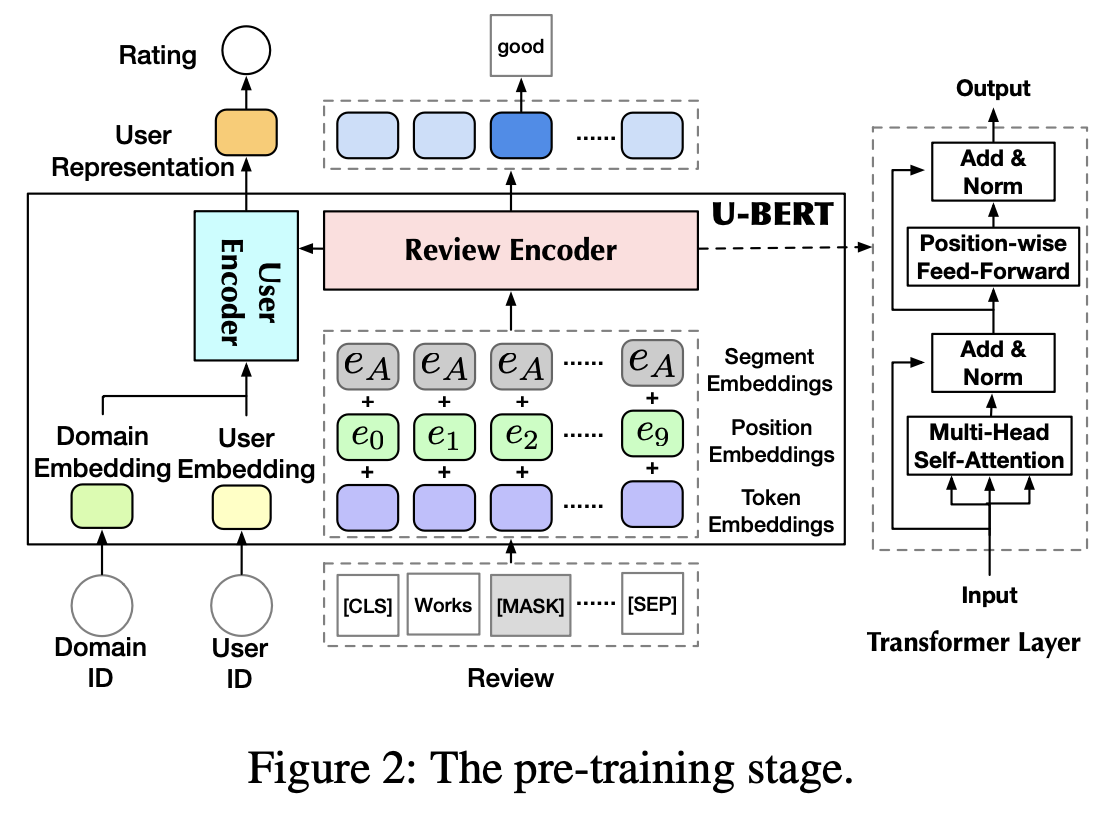
[stage 1] pre-training : content-rich domains
- self-supervision tasks to learn the general user representations
- (Masked Opinion Token Prediction) Review Encoder
- we add the additional user representation (to learn the inherent preference of the user)
- ※ (instead of randomly masking words) we choose the opinion words, shared across domains
- (Opinion Rating Prediction) User Encoder
- we use the review-aware user representation (User Encoder output)
- capture user's general review preference (linking opinions in domains)
- Loss : the weighted sum of losses of two tasks → multi-task learning
-
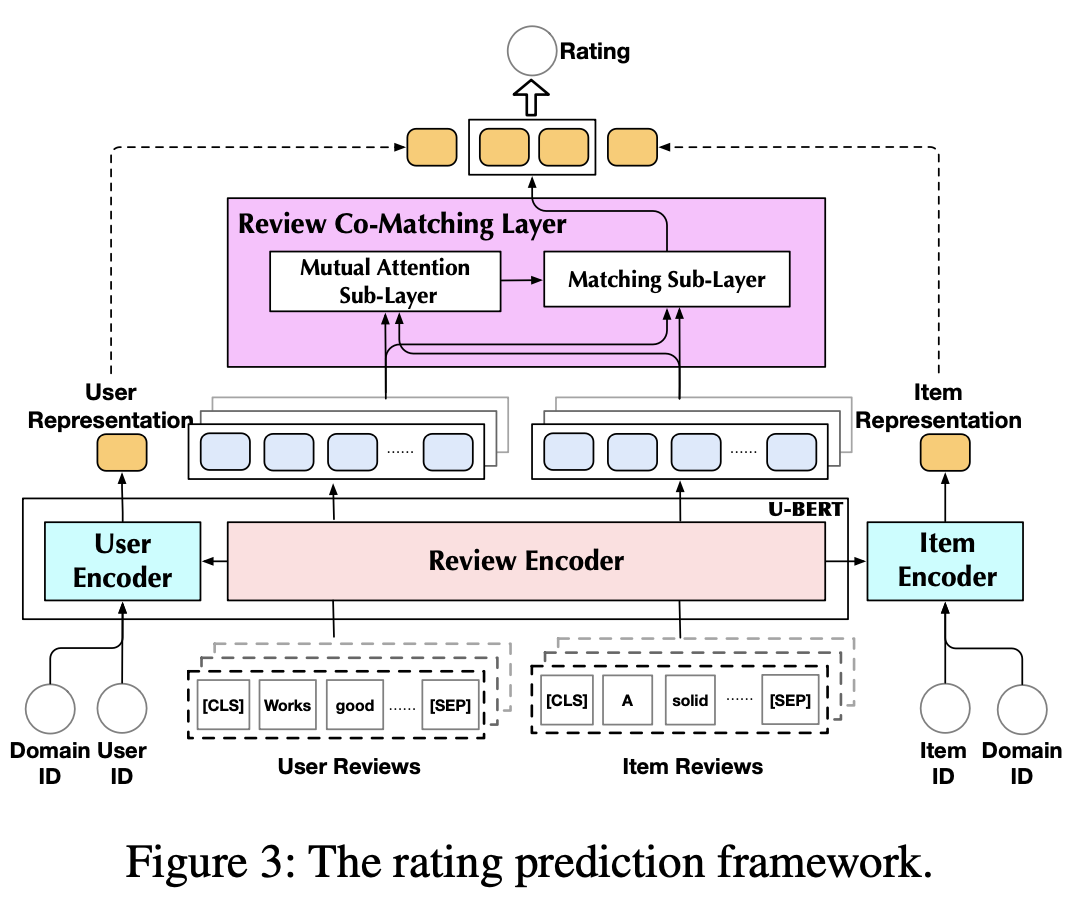
[stage 2] fine-tuning(rating prediction) : target content-insufficient domains
- encode multiple reviews one-by-one by using the review encoder → row-wise concat
- Review Co-Matching Layer : measuring their review semantic similarities (Aspect를 고려)
성능
-
without pre-training (the original BERT’s weights) / pretrain u-bert : 성능 평가


LLM, RecSys, FinNLP 관련하여 꾸준히 공부하며 콘텐츠를 작성할 계획입니다.
유익한 글이었습니다.