서비스 목표 :
콘텐츠 알람 및 광고 최적화등을 활용하여 커뮤니티 블로그의 전환율을 증진하는 서비스
- 사용자의 특성에 따른 보안 관리 및 세션 보호
- 효율적인 실시간 알림 시스템 구축
- 대용량 데이터 검색 및 성능 최적화
- 데이터 기반 컨텐츠 선정 및 광고 전환율 이력 관리
1. 서비스를 처음 구상하게 된 계기
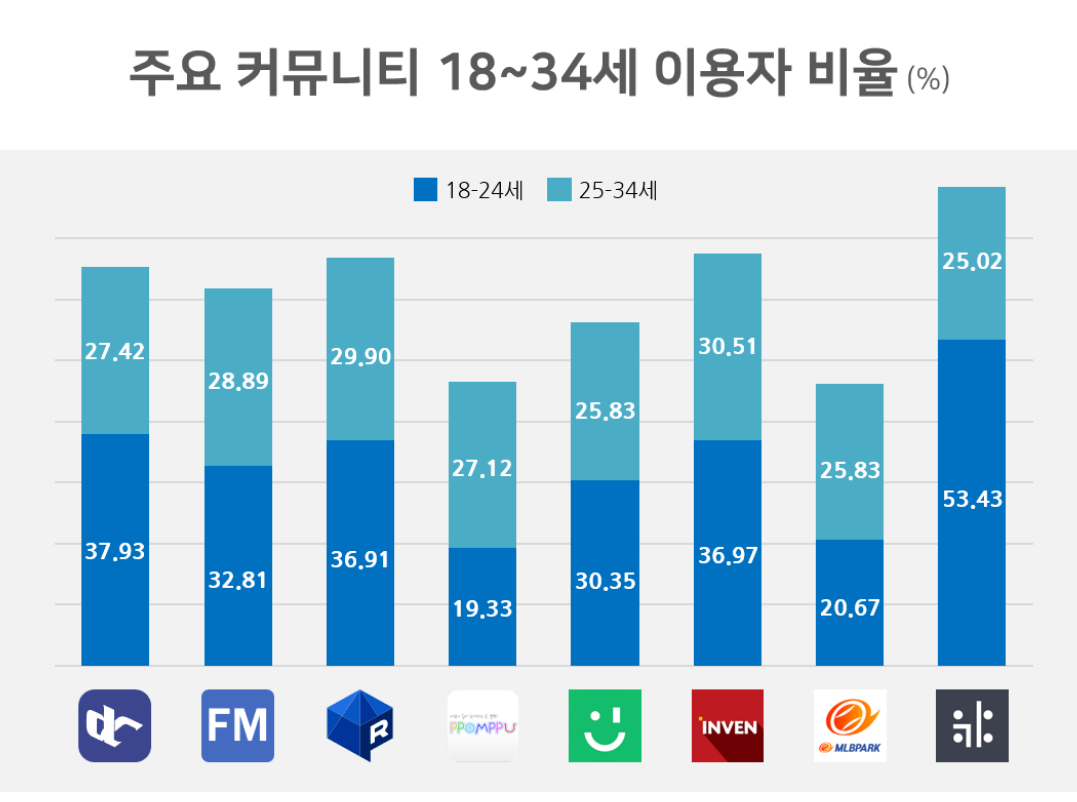
사회적 분위기
특정 서비스들은 비용을 요구하기 보다 광고등으로 수익을 내는 서비스들이 많다. 유저의 접근성이 편한 서비스로써 최적인 것이다. 특히, 대용량 트래픽을 증진하고 광고 전환율을 증진 시키는 서비스는 수익과 직결된다. 이런 부분에 집중을 하고 이서비스를 만들게 되었다.
계기
커뮤니티 블로그는 어디에나 존재하는 일반적인 아이디어이다. 하지만, 이를 서비스로 직접 구상하고 다양한 도구를 활용하여 대용량 데이터를 처리하는 경험을 쌓고 싶어 이 서비스를 접하게 되었다. 추가적으로 용의주도한 알고리즘을 활용하여 높은 접속률을 달성하기 위한 서비스도 개발하기 위해 이 프로젝트에 돌입 하였다.
2. 구상 방법
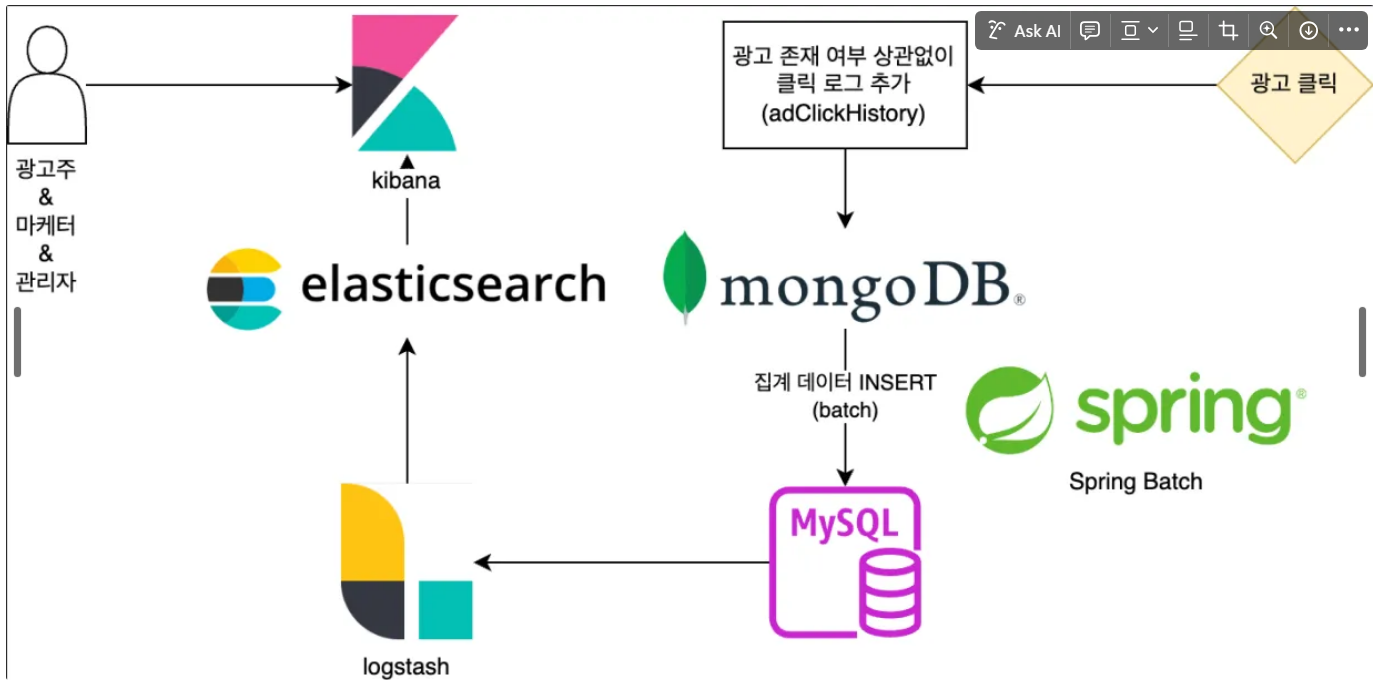
해결의 목적 - 대용량 트래픽을 빠르게 조회하고 처리하기 위한 커뮤니티 블로그 서비스로써 트래픽이 급증해도 안정적으로 동작하는 구조를 설계하는 것이 중요하다고 생각된다.
어떻게 해결 했는가? - 다양한 도구를 적용하고 코드를 만드는데 있어서 어려움이 있었다.
- 어려움 1 비동기 기능(WebFlux + Mono) 활용으로 대량의 요청을 구상하는데 있어서 데이터 정합성을 유지하는 방법의 어려움
- 어려움 2 ELK를 유동적으로 활용해서 실시간 로그 분석과 광고 데이터를 관리하는 구성의 어려움
- 어려움 3
Elasticsearch를 활용하여 대량 데이터 실시간 검색 속도 증진하는 방법에 대한 구성의 어려움이 있었다.
어려움 1의 해결법
- 비동기 기능(WebFlux + Mono) 활용으로 대량의 Redis 캐싱 활용으로 광고 조회 및 클릭 데이터를 Redis에 임시 저장하여 MySQL과 MongoDB에 대한 직접적인 부하를 줄였다.
- @Scheduled를 활용하여 일정 주기로 Redis 데이터를 MySQL과 MongoDB로 동기화하였다.
- WebFlux 환경에서 Reactor Context를 적용하여 요청별 트랜잭션 ID를 관리하였다. 데이터 정합성 유지 및 변환 오류 개선에 신경을 썻다.
어려움 2의 해결법
- 불필요한 필드는 저장하지 않고, 필요한 데이터만 Logstash에서 선별하여 적재 하였다
- 광고 조회 이력 중 중요 필드만 유지하여 MongoDB와 Elasticsearch의 데이터 크기를 최적화 하였다
실시간 저장이 아닌, 일정 주기로 Batch 처리하여 MongoDB에 데이터 적재
JPA 기반의 정형 데이터와 연계하여 조회 속도를 향상 시켰다.
어려움 3의 해결법
- Multi-Index를 활용하여 검색 성능 최적화 및 Db 테이블dmf full-text 형식으로 관리 하였다.
- 자주 검색되는 키워드는 Redis에 캐싱하여 Elasticsearch의 부하를 감소시켰다.
- Elasticsearch의 샤드 수를 조정하여 데이터를 분산 저장 하였다.
3. 그 외의 어려움?
여러 형태의 config 적용 및 분리형 클래스 전략
여러 형태의 config 클래스를 구성하는 부분이 어렵진 않았으나, 많은 시간을 들여 세팅하는 부분과 오류를 수정하는 시간이 많이 걸렸다. 그에 맞게 RabbitMQ의 pub/sub등의 구성과 분리형 클래스 전략에 세심한 신경을 쓰는게 번거로운 부분이었다. 더하여 데이터의 완전한 모니터링 기능을 잘 활용하지 못한 부분의 아쉬움도 있었다.
