
🐛 순수함수
수학에서의 함수란 꼴로 동일한 input x에 대해서 항상 동일한 output y를 가지는 것을 말한다. 이 개념을 프로그래밍으로 옮긴 것이 순수함수이다. 함수의 실행이 전체 프로그램의 실행에 영향을 미치면 안된다. 즉, 함수 내부에서 외부의 값을 변경하는 것과 같은 Side Effect(부수효과)가 나면 안된다.

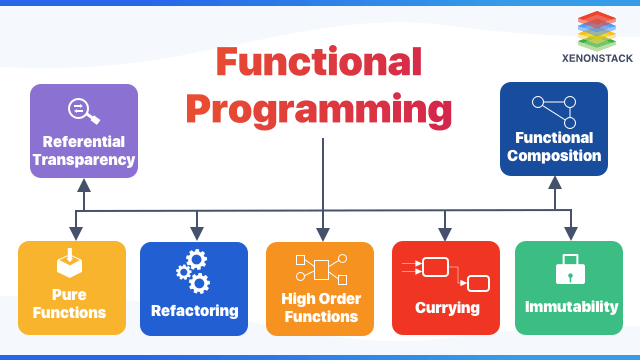
🧊 함수형 프로그래밍의 정의
함수형 프로그래밍(Functional Programming)은 코드를 작성하는 스타일 중 하나이다. 즉, 함수형 프로그래밍으로 설계된 언어가 따로 존재하지만(Clojure, Scala), 우리가 사용하는 모든 언어에 적용할 수 있으며 프로그래밍에 발생할 수 있는 여러 문제들을 해결할 수 있다.
다시 정리하면, 함수형 프로그래밍은 함수를 사용해서 데이터 처리의 참조 투명성을 보장하고, 상태와 가변 데이터 생성을 피하는 프로그래밍 패러다임이다.
객체지향은 동작하는 부분을 캡슐화해서 이해할 수 있게 하고, 함수형 프로그래밍은 동작하는 부분을 최소화해서 코드 이해를 돕는다. (마이클 페더스‘레거시 코드 활용 전략’)
함수형 프로그래밍의 특징
불변성 immutable
부수효과(Side Effect)는 함수의 반환값이 아닌, 외부의 상태에 영향을 미치는 것을 말하는데 이런 부수효과가 발생하지 않도록 함수를 작성해야 한다. 불변성은 상태가 변하지 않는 것을 의미하며, 메모리에 저장된 값을 변경하는 모든 행위에 대해 적용된다. 불변성을 지킨다면, 무분별한 상태의 변경을 막을 수 있고 상태가 어디서 변경되었는지 추적하기에도 용이하다. 실제 개발에서 불변성을 지키는 코드를 작성하기 위해서는 전역 변수의 사용을 줄이고 객체나 배열의 값을 변경해야 할 때는 함수 내에서 해당 object와 동일한 형태를 가지는 object를 생성하여 변경하면 된다.
아래는 순수하지 않은 함수와 부수효과가 있는 함수가 사용된 코드이다.
var z = 10 // 전역변수
fun impureFunction(x: Int, y: Int): Int = x + y + z //순수하지 않은 함수
fun withSideEffect(x: Int, y: Int) : Int {
z = y
return x + y
} // 부수효과가 있는 함수 (함수 밖의 전역변수인 z를 변경하고 있음)참조 투명성 referential transparency
참조 투명성이란, 프로그램의 변경 없이 어떤 표현식을 값으로 대체할 수 있다는 뜻이다. 수학의 함수로 설명하자면 순수함수 가 를 반환한다면, 는 로 대체될 수 있는 것이다. 참조 투명성을 만족하는 코드는 예외가 사라져서 간결해지고 버그가 발생할 가능성이 낮아진다. 멀티쓰레드 코드에서도 쓰레드 안전성에 대한 고민을 덜어준다.
일급 함수 first-class Function
객체지향언어에서는 일급 객체(first-class object)를 지원하는데, 일급 객체는 다음 세 가지 조건을 만족시킨다.
- 객체를 함수의 매개변수로 넘길 수 있다.
fun objectToParam(any: Any) {...}- 객체를 함수의 반환값으로 돌려 줄 수 있다.
fun objectToReturn(any: Any) {
return Any()
}- 객체를 변수나 자료구조에 담을 수 있다.
var anyList: List<Any> = listOf(Any())위 일급 객체의 개념을 그래도 함수에 적용한 것이 일급 함수이다. 프로그래밍 언어가 함수를 first-class citizen 취급하는 것을 말한다. Java는 일급 함수 언어가 아니지만, Kotlin은 일급 함수 언어이다. 일급함수를 사용한다면 추사화와 재사용성을 높일 수 있다.
이렇게 Kotlin에서 함수는 일급함수이므로 함수를 매개변수로 받거나 반환할 수 있는데, 이 두가지 조건 중 하나 이상을 만족하는 함수를 고차함수(higher order function) 라고 한다. 고차함수를 사용하면 코드의 재사용성을 높일 수 있고, 기능을 확장하기 쉬우며, 코드를 간결하게 작성할 수 있다.
// 고차함수를 사용하여 만든 간단한 계산기 프로그램
fun main(args: Array<String>) {
val sum: (Int, Int) -> Int = { x, y -> x + y }
val minus: (Int, Int) -> Int = { x, y -> x - y }
val product: (Int, Int) -> Int = { x, y -> x * y }
println(calcul(sum, 1, 5)) // 1 + 5 = 6
println(calcul(minus, 5, 2)) // 5 - 2 = 3
println(calcul(product, 4, 2)) // 4 * 2 = 8
}
// 매겨변수로 함수를 가지며, 함수를 반환한다
fun calcul(func: (Int, Int) -> Int, x: Int, y: Int): Int = func(x, y)커링 Currying
커링을 이해하기 위해서 먼저 부분함수에 대한 개념을 이해해야한다.
부분함수
부분함수란, 모든 가능한 입력 중에서 일부 입력에 대한 결과만 정의한 함수를 의미하며, 함수의 parameter가 특정한 값이나 범위 내에 있을 때만 함수를 정상적으로 작동시키기 위해 사용한다. 부분함수를 사용하면, 함수를 호출하는 쪽에서 호출하기 전에 함수가 정상적으로 작동하는지 미리 확인가능하고, 호출자가 함수가 던지는 예외나 오류값에 대해서 몰라도 된다. 그리고 부분 함수의 조합으로 부분 함수 자체를 재사용할 수 있고, 확장할 수도 있다. 하지만, 부분함수를 만들어야하는 상황을 만들지 않고 모든 입력에 대한 결과를 정의하는 것이 가장 좋다.
커링이란?
Currying은 여러 개의 매개변수를 받는 함수를 분리하여, 단일 매개변수를 받는 부분 적용 함수의 체인으로 만드는 방법이다. 커링에서 활용하는 함수들이 부분함수이며, 커링의 장점으로는 이런 부분 적용 함수를 다양하게 재사용할 수 있다는 점과 마지막 매개변수가 입력될 때까지 함수의 실행을 늦출 수 있다는 것이다.
// 두 개의 매개변수 중 큰 값을 반환하는 max 함수의 커링 버전
fun max(a: Int) = { b: Int -> if (a > b) a else b }
fun main() {
println(max(10)(20)) // 20 출력
}⚓️ 명령형 Imperative vs 선언형 Declarative
명령형 프로그래밍과 선언형 프로그래밍도 프로그래밍 패러다임 중 하나이다. 이 둘은 서로 반대되는 개념이기 때문에 차이점을 분석하면서 공부해보자
“Imperative programming is like how you do something,
and declarative programming is more like what you do, or something.”
즉, 명령형 프로그래밍은 어떻게 하는가에 초점을 맞췄다면, 선언형 프로그래밍은 무엇을 하는가에 초점을 맞춘 것이다. 그럼 이제 각각을 자세히 비교해보자
명령형 프로그래밍
절차적 프로그래밍이라고도 한다. 얻으려는 것에 대해 어떤 방법으로 접근할 것인지, 그 절차적인 방법을 작성하는 방법이다. 즉, 알고리즘을 명시하지만 목표는 명시하지 않는다. 우리가 배열 알고리즘 문제를 풀 때 반복문으로 각 인덱스에 접근하여 상태를 변경하던 것이 이 방식에 해당한다.
fun add(items: List<Int>) : Int {
var result: Int = 0
for (i in items)
result += i
return result
}선언형 프로그래밍
선언형 프로그래밍은 앞서 말했듯이 무엇을 하는가에 초점이 맞춰져 있다. 명령형으로 작성된 코드를 추상화하는 것이 선언형 프로그래밍의 솔루션이다. 위에 명령형으로 작성된 코드를 선언형으로 바꿔보자
fun add(arr: List<Int>): Int {
return arr.reduce { prev, curr -> prev + curr }
}보이는 것과 같이, 선언형 프로그래밍을 사용하면 코드를 추상화할 수 있어 앞서 배운 객체지향프로그래밍에 적합하고 해당 코드가 달성하고자 하는 것이 무엇인지만 알려주기 때문에 재사용성이 높다. (나는 reduce()함수가 무엇을 반환하는지는 알지만 내부적으로 어떻게 작동하는지는 모른다.)
