
📌 목표
자바가 제공하는 제어문을 학습한다
📌 학습할 것
- 선택문
- 반복문
📌 과제
- JUnit 5를 학습한다
- live-study 대시 보드를 만드는 코드를 작성한다
- LinkedList를 구현한다
- Stack을 구현한다
- ListNode를 사용해서 Stack을 구현한다
- Queue를 구현한다
🧩 선택문
switch문
if문은 경우의 수가 많아질 경우 'else if'를 계속 추가해야하는 번거로움이 존재한다
이러한 if문과 달리 switch문은 단 하나의 조건식으로 많은 경우의 수를 처리할 수 있고 표현도 간결하다는 장점이 있다
다만, 제약사항이 있기 때문에 울며겨자먹기로 if문을 써야만 할 때도 있다
🙌 switch문의 제약사항
✔ switch문의 조건식 결과는 정수 또는 문자열이어야 한다
✔ case문의 값은 정수 상수만 가능하며(변수와 실수는 불가), 중복되지 않아야 한다
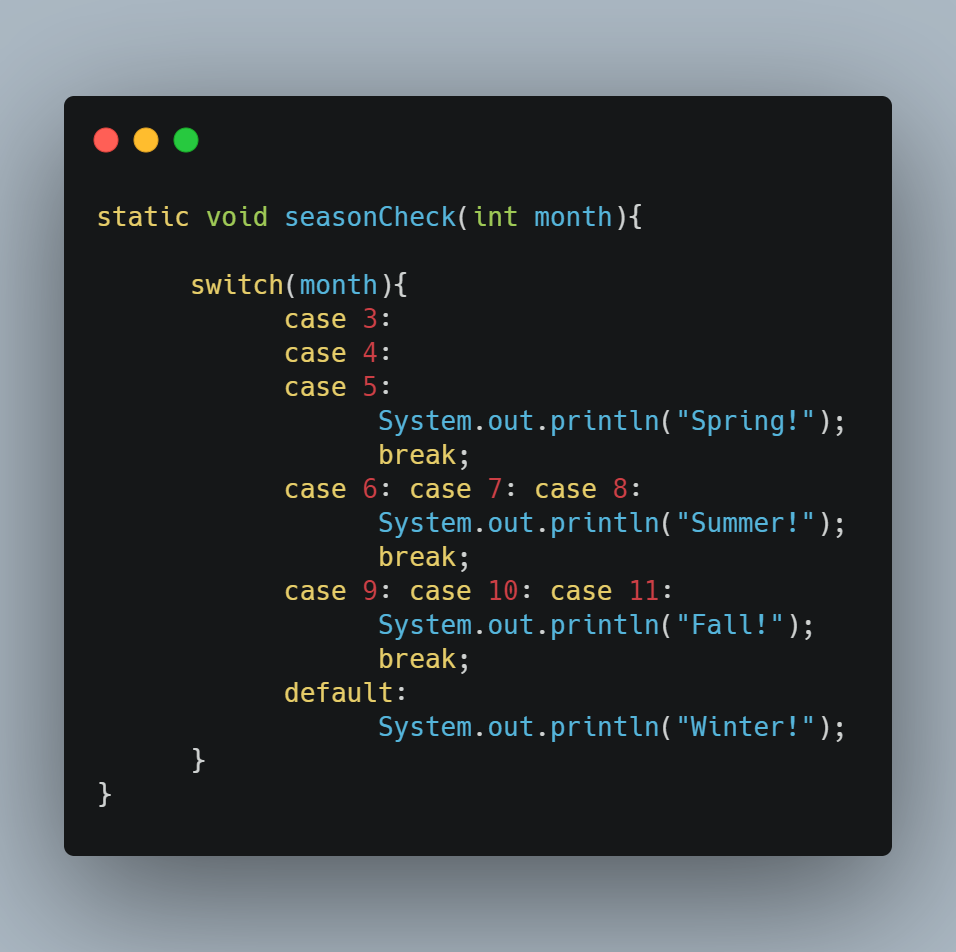
💨 코드 설명
- switch문은 switch 바로 옆의 괄호( ) 안에 있는 조건식을 먼저 계산하고, 그 결과와 일치하는 case문으로 이동한다
- 이동한 case문 아래에 있는 문장들을 수행하며, break문을 만나면 전체 switch문을 빠져나온다
- 조건식의 결과와 일치하는 case문이 없는 경우, default문으로 이동한다. if문에서의 else블럭과 같은 역할을 한다고 생각하면 된다
- default문은 switch문 어디에든 위치해도 되지만 보통 가장 아래에 넣는 것이 대부분이고, 그 이유로 break문을 생략하기도 한다
- break문은 각 case문의 영역을 구분하는 역할을 한다
- 만약 break이 없다면❓❗다른 break문을 만나거나 switch문 블럭{ }의 끝을 만날 때까지 나오는 모든 문장들을 모두 수행한다
- 각 case문의 마지막에 break을 빼먹지 않도록 주의해야하는데, 고의적으로 break을 적지 않은 경우도 있다

↳ 로그인한 사용자의 등급을 체크하여 그에 맞는 권한을 주는 코드이다.
권한등급이 3인 사용자는 삭제,쓰기,읽기 권한 모두를 가지게 되고, 권한등급이 1인 사용자는 읽기 권한만 가지게 된다.
🧩 반복문
for문
for문은 반복 횟수를 알고 있을 때 적합하다
for문의 구조는 초기화, 조건식, 증감식, 블럭{ }으로 이루어져 있다.
초기화, 조건식, 증감식의 경우 생략할 수 있으며, 생략하더라도 괄호( )안의 ';'는 항상 두 개가 있어야 한다
for(초기화; 조건식; 증감식){
블럭
}
- 초기화
- 반복문에 사용될 변수를 초기화하는 부분
- 보통 변수 하나만 사용하지만, 둘 이상의 변수가 필요할 때는 ','를 구분자로 하여 사용할 수 있다(단, 두 변수의 타입은 같아야 한다❗)
- 조건식
- 조건식의 값이 true면 반복을 계속하고, false이면 반복을 중단하고 for문을 벗어난다
- 증감식
- 반복문을 제어하는 변수의 값을 증가 또는 감소시키는 식
- 주로 '++'나 '--'와 같은 연산자가 사용되지만, op=연산자도 사용될 수 있다
- ','를 이용해서 두 개의 변수에 대해 증감식을 수행할 수 있다
향상된 for문
JDK1.5부터 새롭게 추가된 문법이다
for(타입 변수명 : 배열 또는 컬렉션){
블럭
}위의 형식에서 타입은 배열 요소의 타입 또는 컬렉션 요소의 타입이어야 한다
배열 또는 컬렉션에 저장된 값이 매 반복마다 하나씩 순서대로 읽혀서 변수에 저장된다
그리고 중요한 것은, 반복문의 블럭에서는 이 변수를 사용해서 코드를 작성해야 한다
다음의 두 코드는 서로 출력 결과가 같다
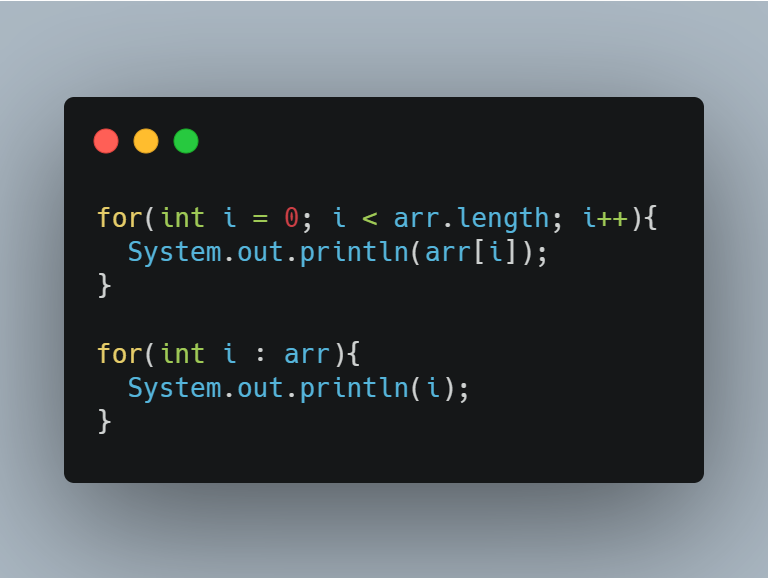
while문
구조부터 살펴보자면 다음과 같다
while(조건식){
블럭
}괄호( ) 안의 조건식이 true인 동안, 즉 조건식이 거짓이 될 때까지 블럭의 내용을 반복한다
for문에서와 달리 while문에서는 조건식을 생략할 수 없다
따라서 while문의 조건식이 항상 참이 되게 하려면 true를 적어주면 된다
같은 내용의 코드를 for문과 비교해보면 다음과 같다
/*for문*/
for(int i = 1; i <= 10; i++){
System.out.println(i);
}
/*while문*/
int i = 1; //초기화
while(i <= 10){ //조건식
System.out.println(i);
i++; //증감식
}💥초기화나 증감식이 필요하지 않는 경우라면 while문이 더 간결하겠지만, 반대의 경우 for문이 더 적합하다
😯조건식에 증감식을 넣을 수 있다
int i = 5;
while(i--!=0){
System.out.println(i);
}i의 값이 0이 아닐 때까지 i를 1씩 감소시키다가 0이 되면 조건식은 false가 되어 while문을 벗어난다
do-while문
while문의 변형으로 기본적인 구조는 같으나 조건식과 { 블럭 }의 순서를 바꿔놓은 것이다
블럭을 먼저 수행한 후에 조건식을 평가한다
따라서, 최소한 한번은 블럭을 수행하는 것이 보장된다
do{
블럭
} while(조건식);💥조건식 끝에 ; 붙이는 것을 잊지 않도록 주의하자💥
➕ break문
break문을 사용하면 자신이 포함된 가장 가까운 반복문을 벗어난다
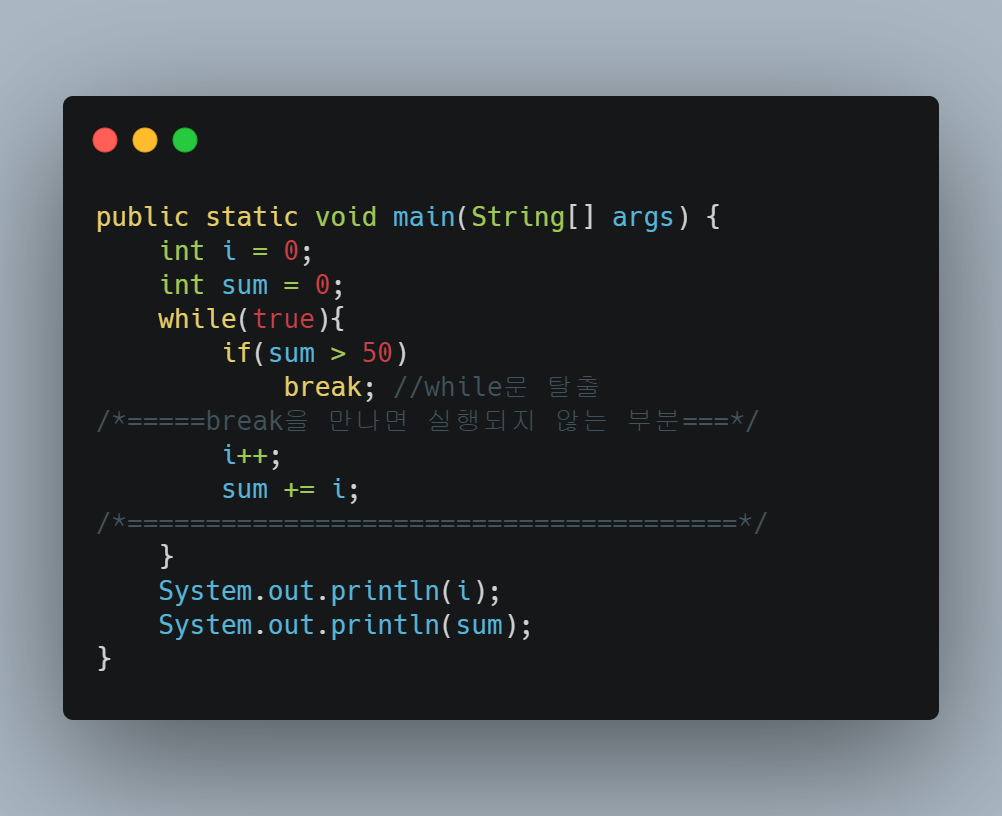
출력값
i = 10
sum = 55
➕ continue문
반복이 진행되는 도중에 continue문을 만나면 반복문의 끝으로 이동하여 다음 반복으로 넘어간다
- for문의 경우 : 증감식으로 이동
- while문의 경우 : 조건식으로 이동
continue를 만나면 이후의 문장들을 수행하지 않는다는 부분이 break문과 비슷하지만,
반복문을 벗어나는 것이 아니라 다음 반복으로 넘어가서 계속 진행한다는 것이 POINT❗
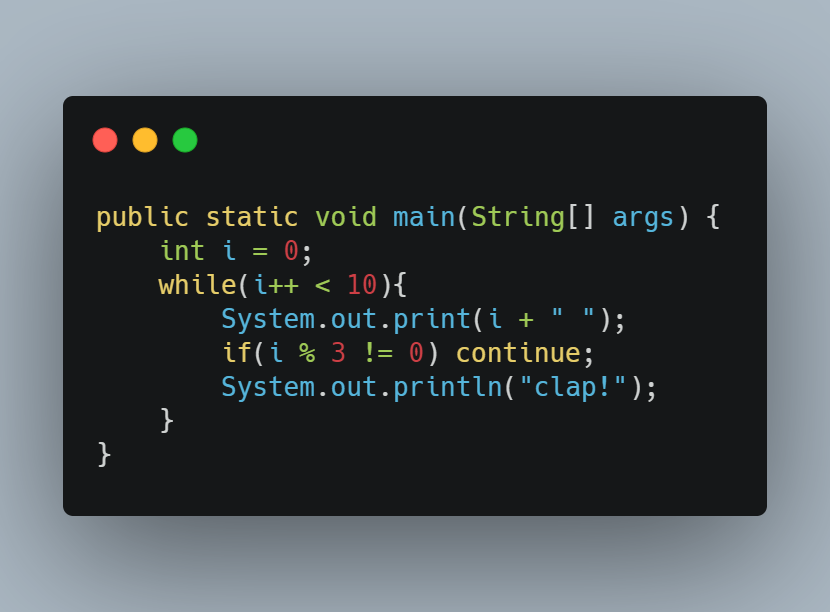
💨 i가 3의 배수이면 i 옆에 clap!을 출력하고 다음 줄로 커서를 옮기는 코드이다
i % 3 != 0이 true가 되면 continue문을 만나 clap!을 출력하지 않고 다음 반복으로 넘어간다
출력값
1 2 3 clap!
4 5 6 clap!
7 8 9 clap!
10
➕ 이름 붙은 반복문
break문은 근접한 단 하나의 반복문만 벗어날 수 있기 때문에, 여러 개의 반복문이 중첩된 경우에는 break문으로 중첩 반복문을 완전히 벗어날 수 없다.
이럴 때는 중첩반복문에 이름을 붙이고 break문 혹은 continue문 옆에 이름을 붙여줘서 반복문을 벗어날 수 있다
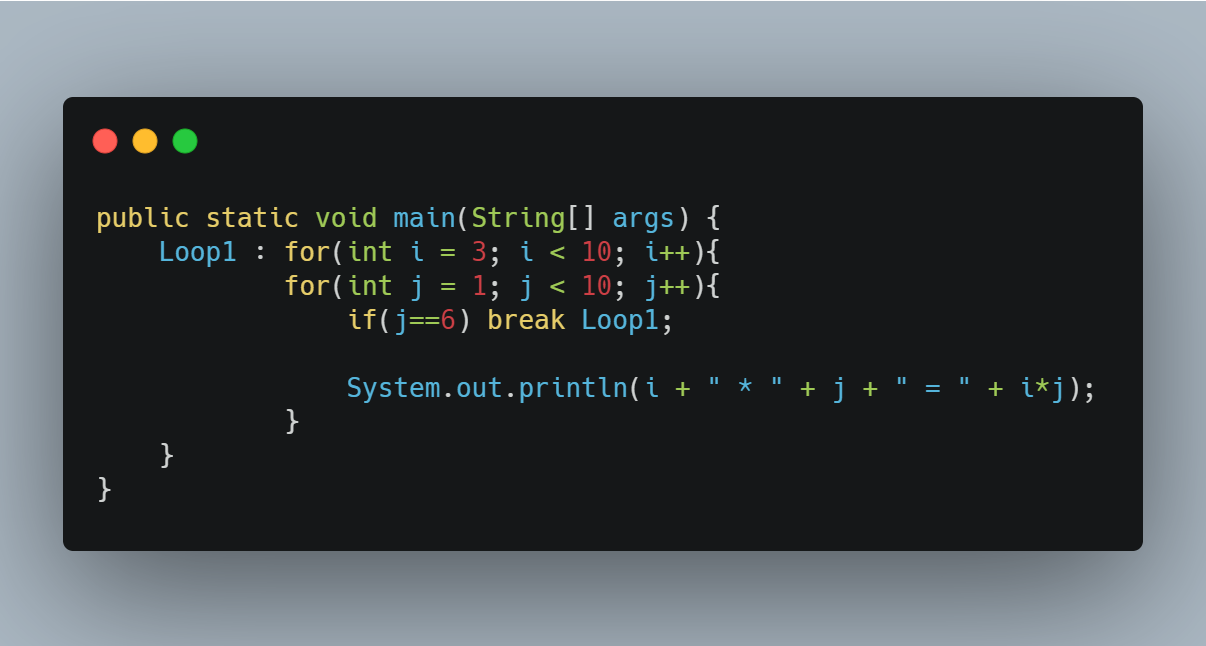
출력값
3 * 1 = 3
3 * 2 = 6
3 * 3 = 9
3 * 4 = 12
3 * 5 = 15
원래는 i와 j가 각각 9일 때까지 반복을 해야하지만
j==6일 때 break Loop1문을 만나서 outer for문을 탈출하고 모든 반복을 종료한다
🧩 과제 0. JUnit 5를 학습한다.
📖 JUnit 5
단위테스트?
이번에 JUnit을 학습하면서 '단위테스트'라는 말을 처음 들어봤다. JUnit을 공부하기 전에, 먼저 단위테스트가 무엇을 의미하는지 알고 가자
단위테스트, "unit test"라고도 한다. 단위 테스트는 소스코드의 모듈이나 어플리케이션 안에 있는 개별적인 코드 단위가 의도한 대로 정확히 작동하는지 검증하는 절차다
즉, 모든 메소드에 대한 Test case를 작성하는 절차를 말한다
단위테스트에서 테스트들은 서로 분리되어 테스트 되고 있는 코드와도 분리되어 있고, 자동적으로 실행되며, 어플리케이션의 같은 부분을 테스트하는 테스트들은 그룹화되어 한번에 처리된다
단위테스트에는 몇 가지 장점이 존재한다
- 단위테스트의 목적은 어플리케이션의 각 부분을 고립시켜서 각각의 부분이 정확하게 동작하는지 확인하는 것이다. 프로그램을 작게 쪼개서 문제가 발생하는지 확인하므로 어느 부분이 잘못되었는지 빠르게 확인할 수 있다. 그리고 프로그램의 안정성이 높아진다.
- 단위테스트는 개발 시간을 증가시키는 것처럼 보이지만 개발에서 큰 부분을 차지하는 디버깅 시간을 단축시키는 역할을 한다.
- 코드를 작성할 때 리팩토링 과정을 거치는데, 리팩토링 후에도 모듈이 원래대로 작동하고 있다는 것을 확신할 수 있다. 이것을
회귀 테스트(Regression testing)이라고 한다. 지속적으로 단위테스트 환경을 만들면 코드에 어떠한 변화를 주더라도 코드가 의도한대로 실행되는지 확인할 수 있다.- 단위테스트는 unit 자체의 불확실성을 제거해주므로 상향식 테스트 방식에서 유용하다. 후에 unit들을 모두 합쳐서 진행하는 통합 테스트(Integration test)에서 효과적이다.
JUnit?
JUnit은 Java의 단위 테스트 도구, 즉 단위테스트 framework 중 하나이다.
Java에서 System.out으로 디버깅할 필요없이 단위테스트를 수행할 수 있게 해준다.
JUnit은 @Test 메서드가 호출할 때 마다 새로운 인스턴스를 생성하여 독립적인 테스트가 이루어지게 한다. 테스트 결과를 확인하는 것 이외 최적화된 코드를 유추해내는 기능도 제공한다.
JUnit 5와 JUnit 4의 차이점 (참고자료)
- IDE에 대한 강한 결합도를 해결
- 부족했던 확장성 해결
➡ 하나의 @Runwith에 여러 Rule을 사용하여 확장하고, Runwith들이 결합되지 못했다 - 하나의 Jar에 포합되어 있던 코드를 분리하였다.
실습
IntelliJ IDEA YouTube와 관련 포스팅을 참고했다
🟢 1. Gradle 기반의 프로젝트를 생성한다
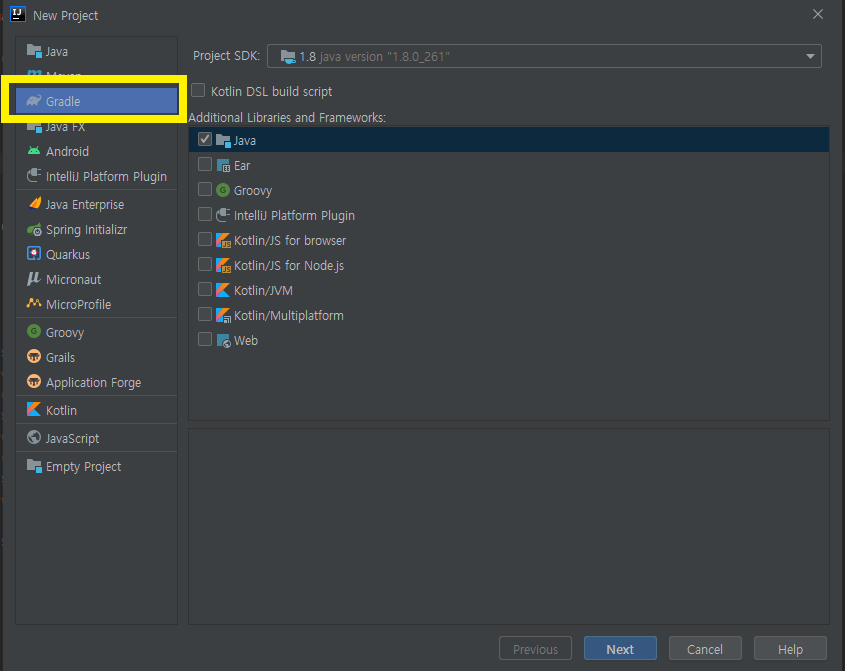
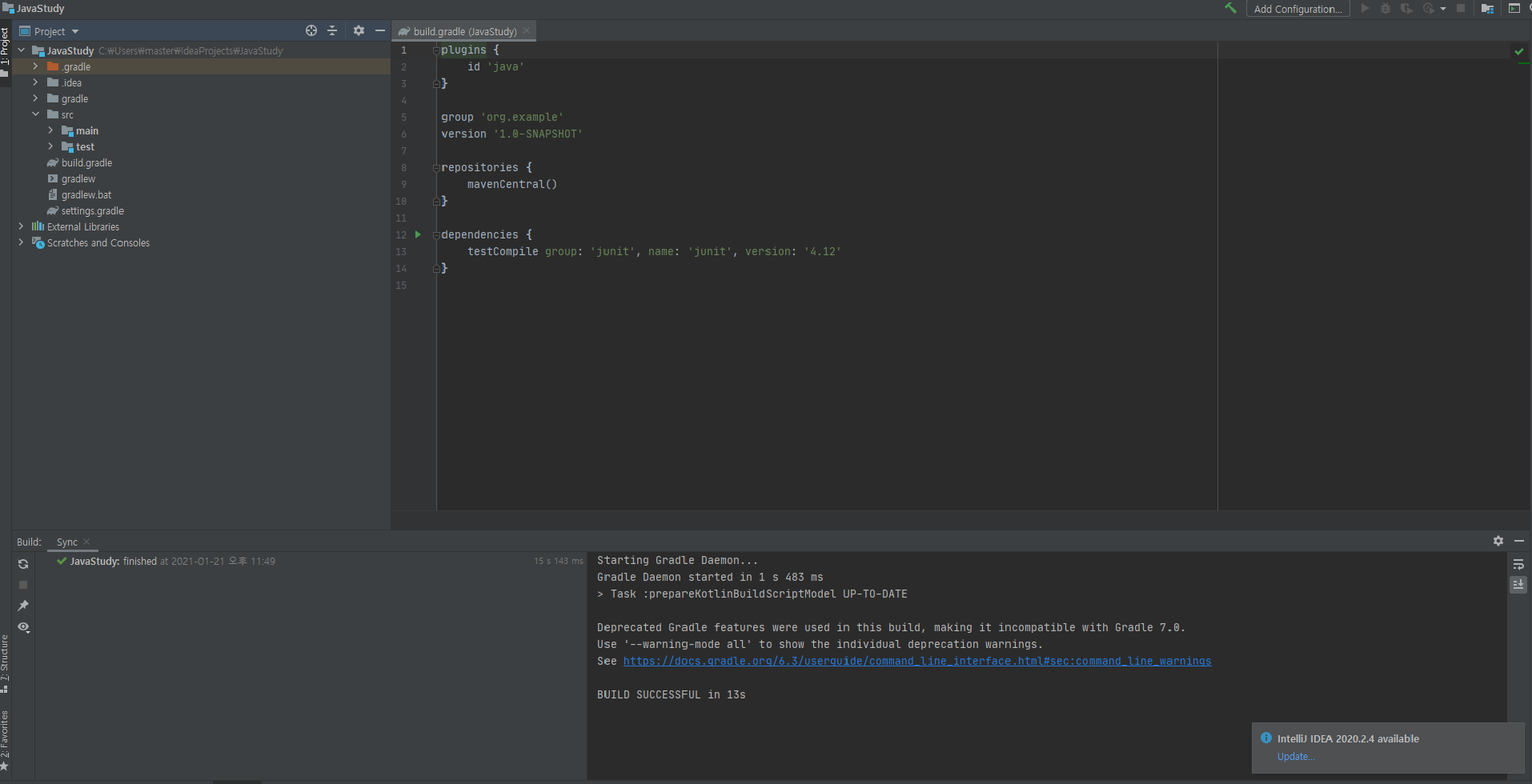 생성하면 다음과 같이 만들어진다.
생성하면 다음과 같이 만들어진다.
🟢 2. dependency를 추가한다
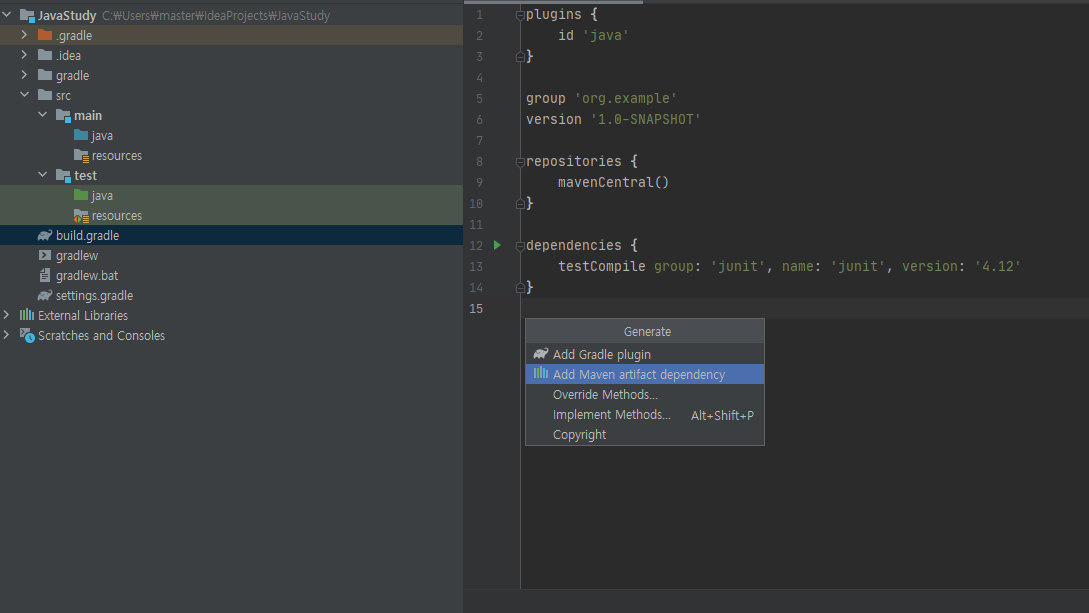
Alt + Ins를 입력하면 아래와 같이 Generate 창이 나온다
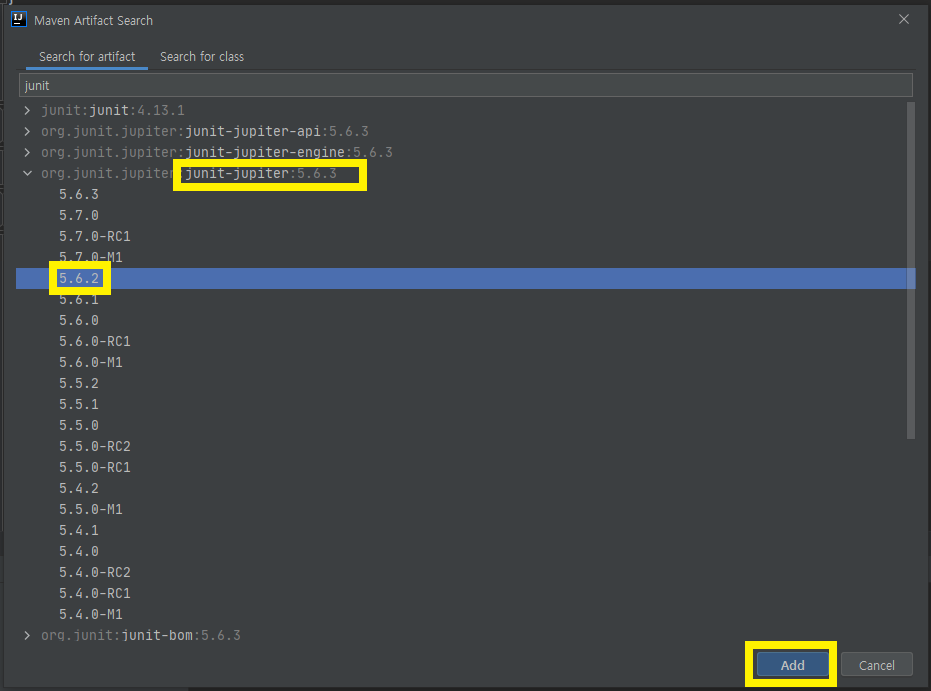 junit을 검색해서 아래와 같이 5.6.2버전을 추가한다
junit을 검색해서 아래와 같이 5.6.2버전을 추가한다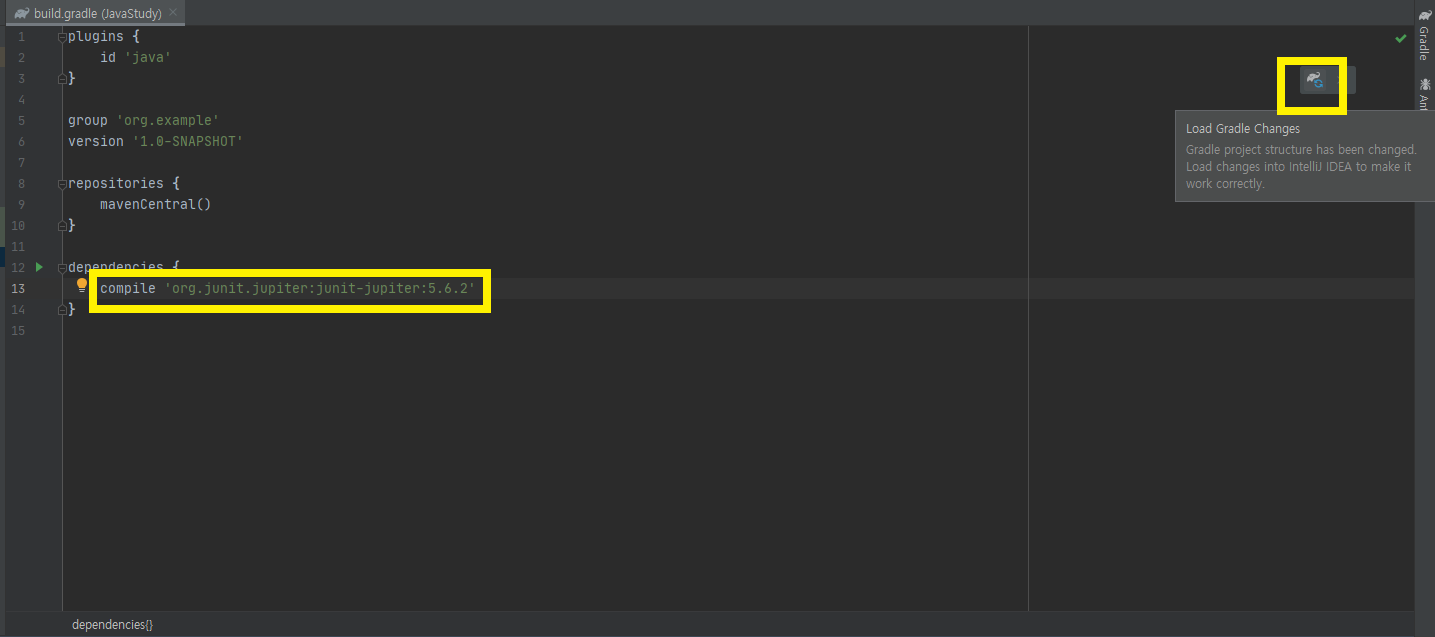 영상과 같은 환경에서 실습하기 위해 기존에 있던 testcompile 항목은 삭제했다. 그리고 나서 위와 같이 gradle을 업데이트 시켜준다
영상과 같은 환경에서 실습하기 위해 기존에 있던 testcompile 항목은 삭제했다. 그리고 나서 위와 같이 gradle을 업데이트 시켜준다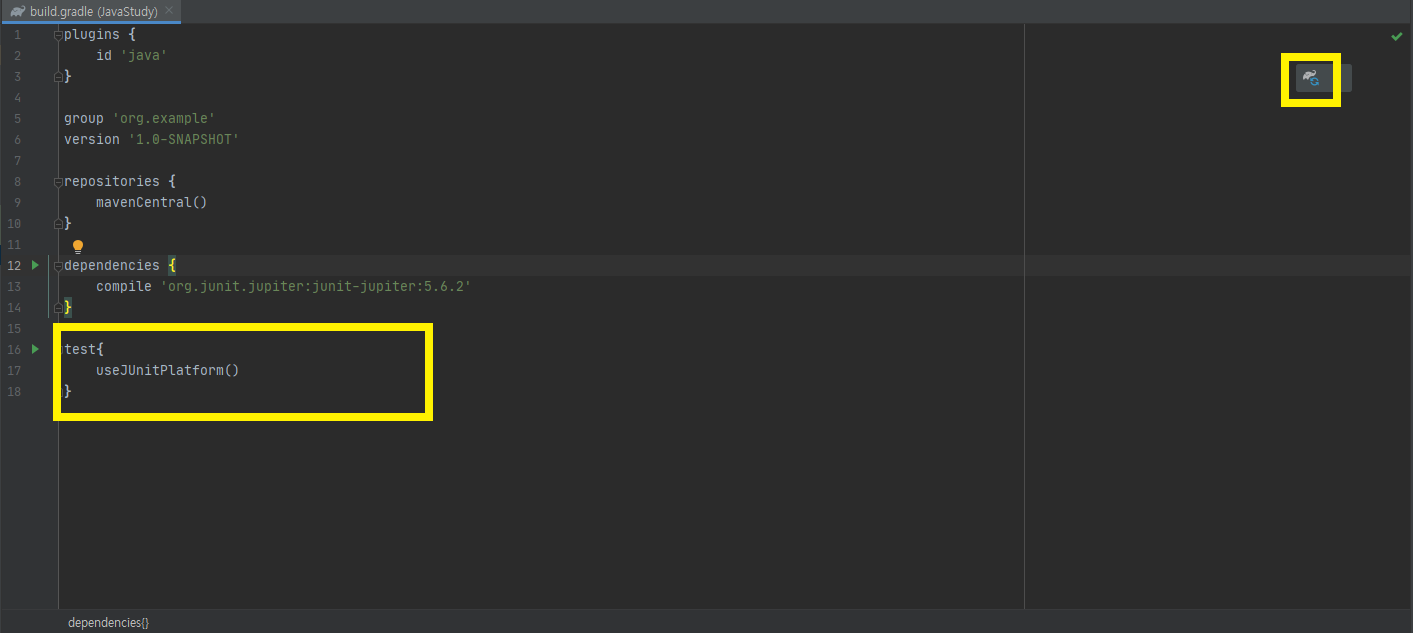 위와 같이 타이핑 한 후 업데이트 해준다
위와 같이 타이핑 한 후 업데이트 해준다
🟢 3. test 메서드 작성
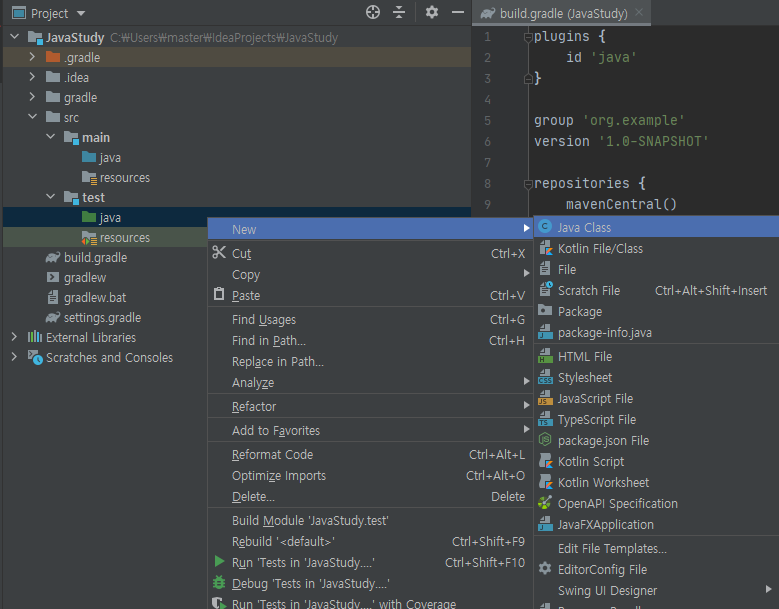 test 메서드를 위한 Java 클래스를 하나 만들어준다
test 메서드를 위한 Java 클래스를 하나 만들어준다 스크린샷을 따로 찍지는 않았지만 프로젝트창에서 볼 수 있듯이 package를 따로 만들어주었다. 그리고 아까와 마찬가지로
스크린샷을 따로 찍지는 않았지만 프로젝트창에서 볼 수 있듯이 package를 따로 만들어주었다. 그리고 아까와 마찬가지로 Alt + Ins를 입력한 후 Test Method에서 Enter를 입력!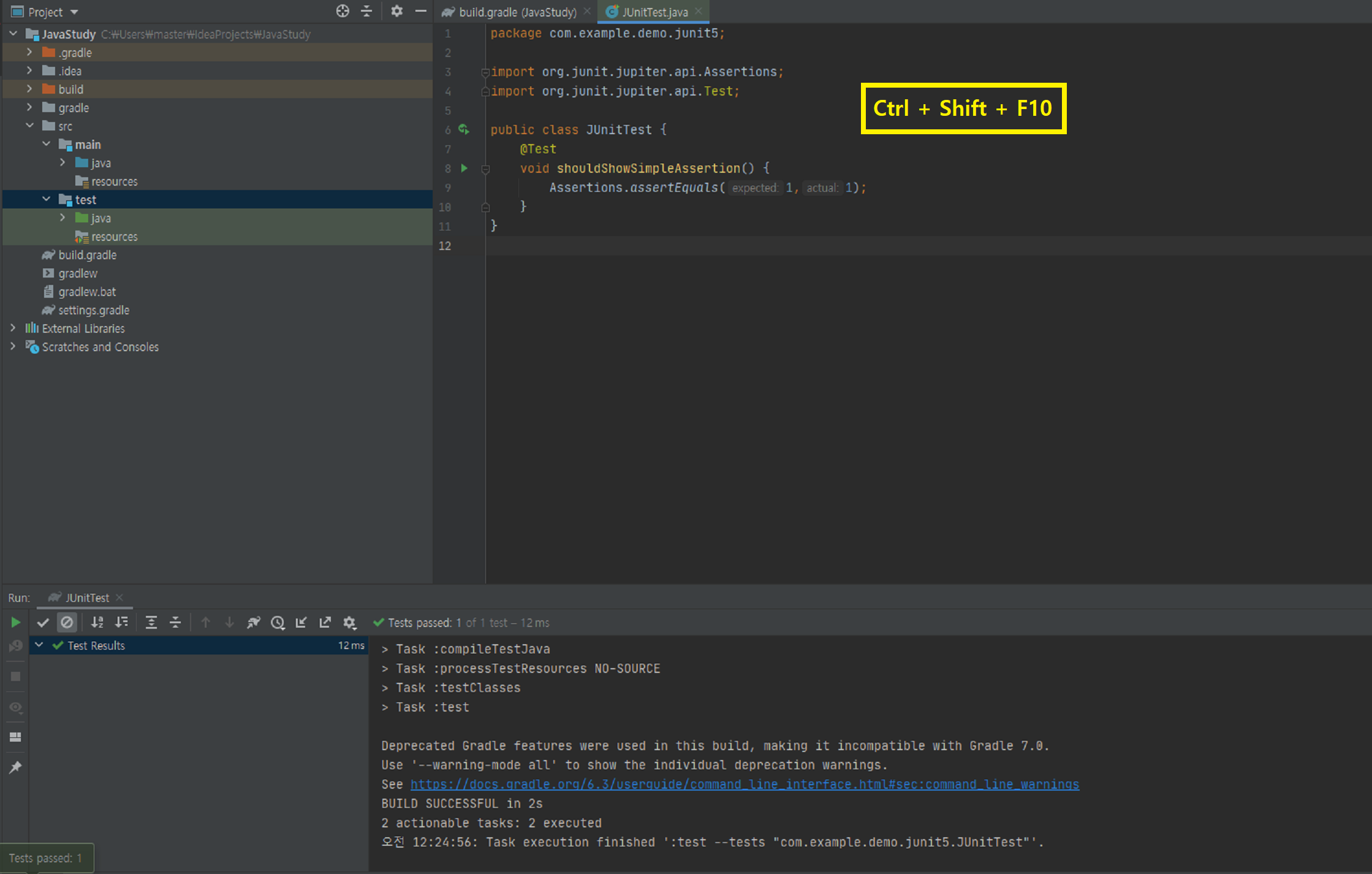 JUnit 5에서는 우리가 자주 사용하는(사용하게 될) assertion 메소들을 위한 클래스가 존재한다. 그 중 한 가지로 테스트를 해보자!
JUnit 5에서는 우리가 자주 사용하는(사용하게 될) assertion 메소들을 위한 클래스가 존재한다. 그 중 한 가지로 테스트를 해보자!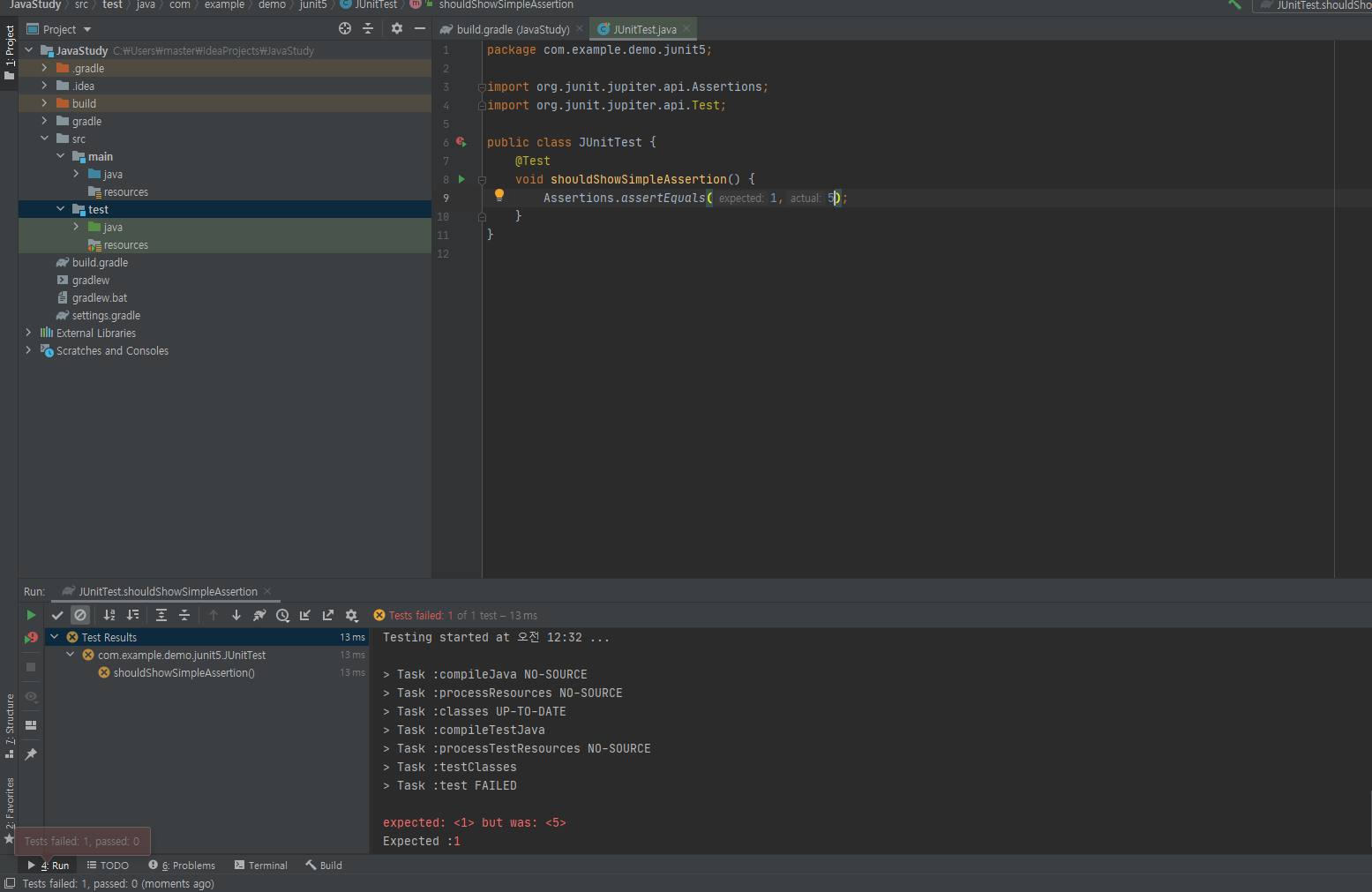 그렇다면 테스트가 실패할 때는 어떨까? actual값을 5로 바꾸고 실행해 보았다. 테스트가 실패했다는 것을 볼 수 있고 콘솔 창에 에러의 원인을 알려준다
그렇다면 테스트가 실패할 때는 어떨까? actual값을 5로 바꾸고 실행해 보았다. 테스트가 실패했다는 것을 볼 수 있고 콘솔 창에 에러의 원인을 알려준다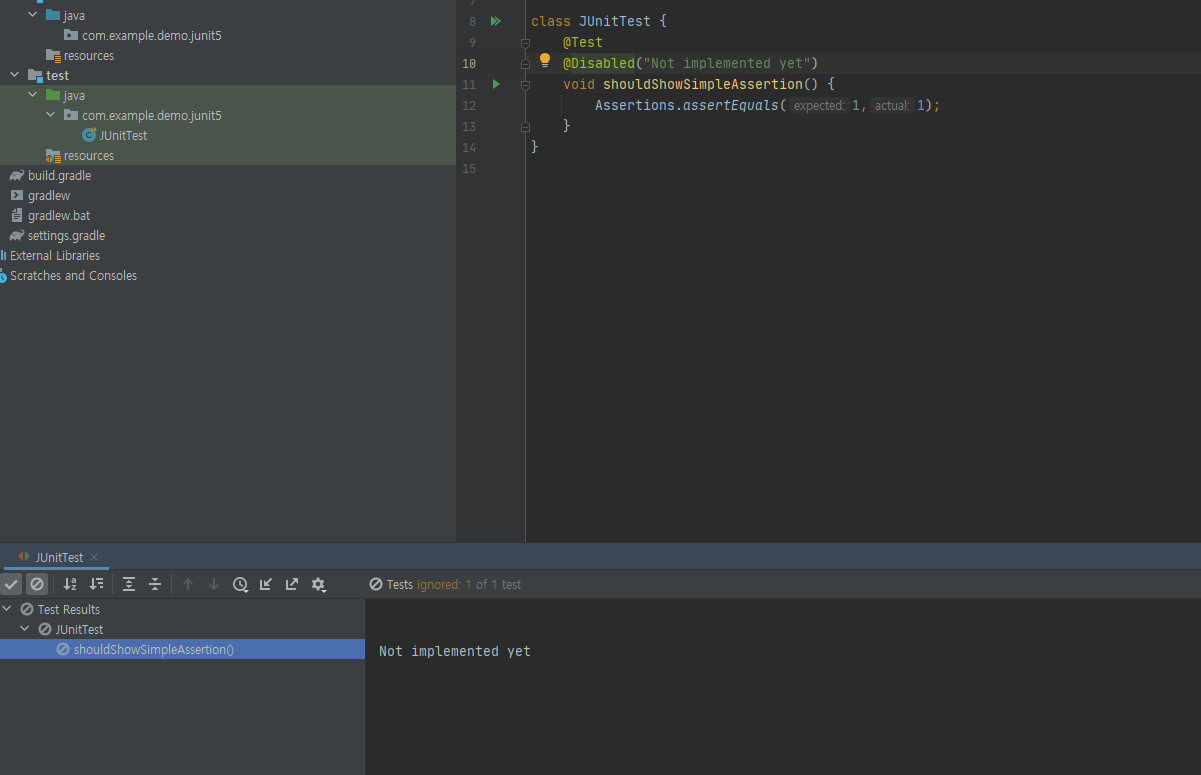 또한 다음과 같이
또한 다음과 같이 @Test 밑에 @Disabled("msg")를 입력하면 테스트가 중단되고 msg의 내용이 출력창에 출력된다
혹시 출력창에 저와 같이 출력이 안되시는 분은 Settings에서 다음과 같이 설정해주면 정상적으로 출력이 될 것이다
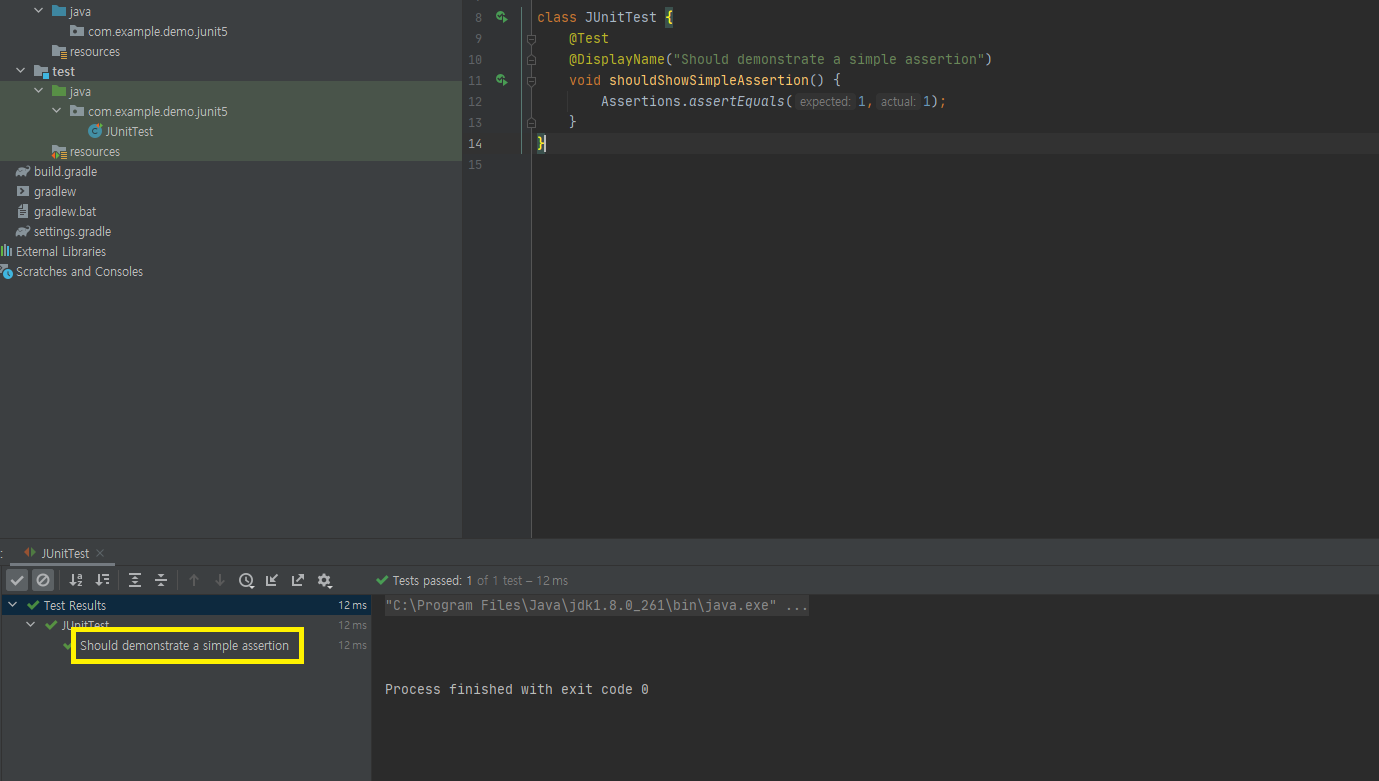 또한,
또한, @Test 밑에 @DisplayName("msg")를 입력하면 진행한 테스트의 내용(이름)을 보여줄 수 있다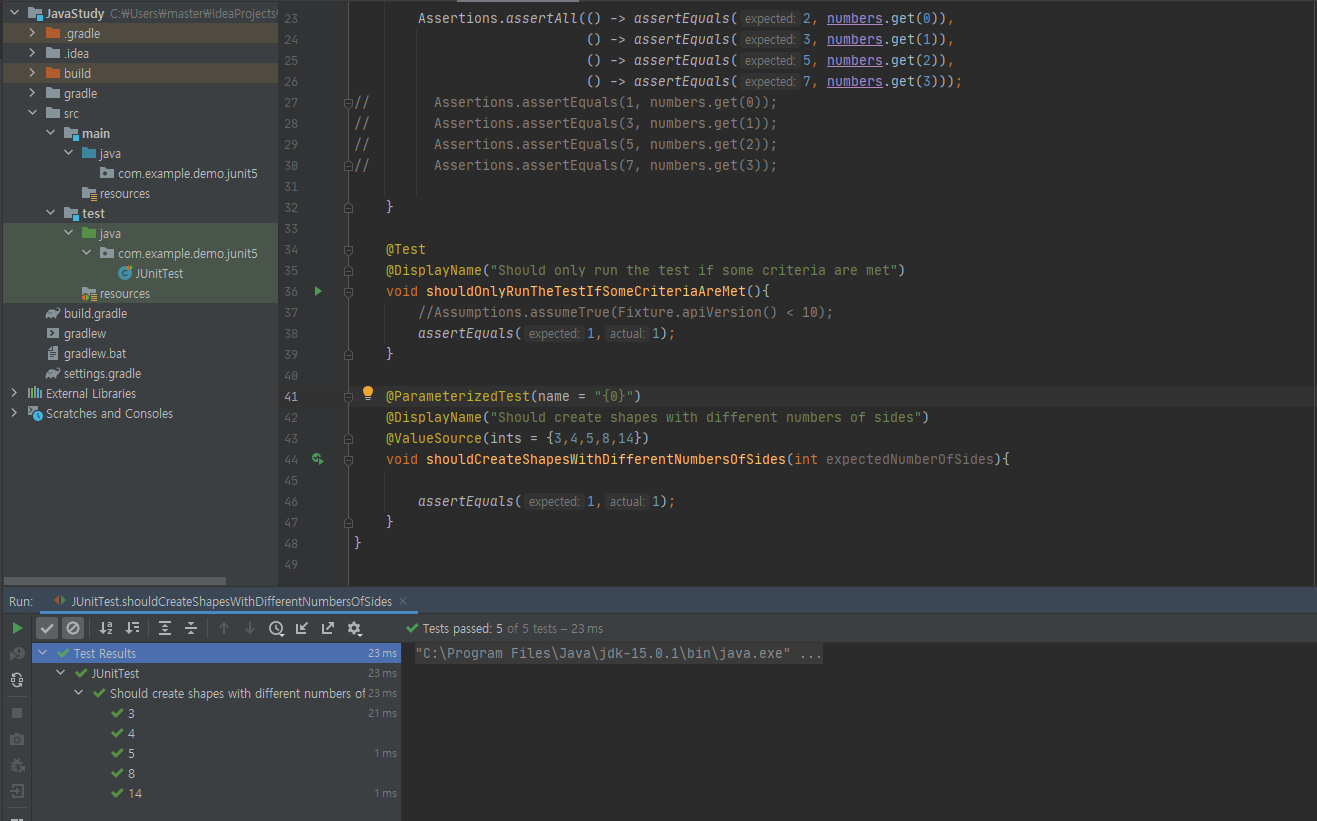
@ParameterizedTest와 @ValueSource annotation을 이용하여 간단한 배열을 파라미터 값으로 지정해서 테스트를 진행한다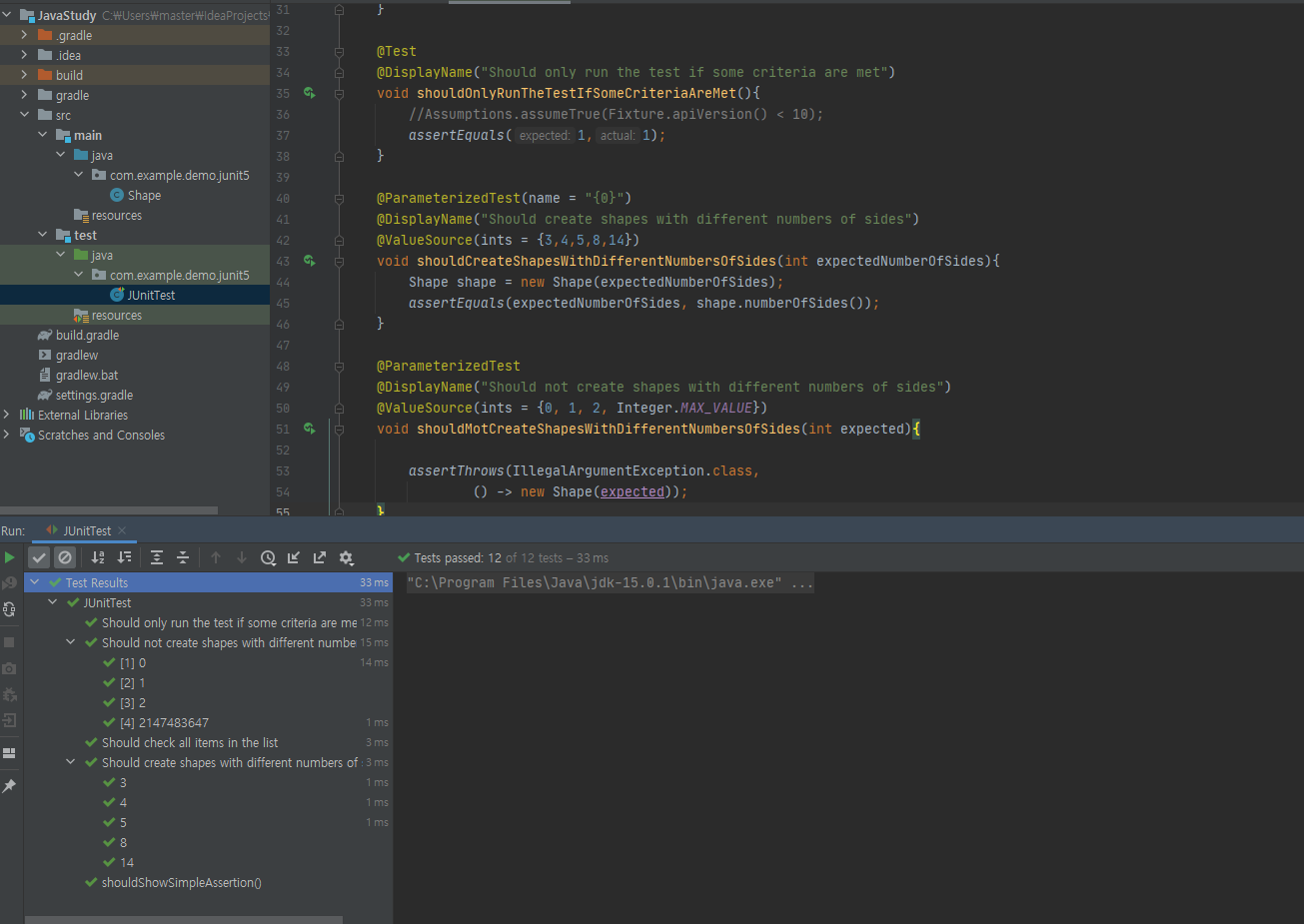
아래는 제가 작성한 코드입니다
1. JUnitTest.java
package com.example.demo.junit5;
import org.junit.jupiter.api.*;
import org.junit.jupiter.params.ParameterizedTest;
import org.junit.jupiter.params.provider.ValueSource;
import java.util.List;
import static org.junit.jupiter.api.Assertions.*;
class JUnitTest {
@Test
void shouldShowSimpleAssertion() {
Assertions.assertEquals(1,1);
}
@Test
@DisplayName("Should check all items in the list")
void shouldCheckAllItemsInTheList(){
List<Integer> numbers = List.of(2, 3, 5, 7);
Assertions.assertAll(() -> assertEquals(2, numbers.get(0)),
() -> assertEquals(3, numbers.get(1)),
() -> assertEquals(5, numbers.get(2)),
() -> assertEquals(7, numbers.get(3)));
// Assertions.assertEquals(1, numbers.get(0));
// Assertions.assertEquals(3, numbers.get(1));
// Assertions.assertEquals(5, numbers.get(2));
// Assertions.assertEquals(7, numbers.get(3));
}
@Test
@DisplayName("Should only run the test if some criteria are met")
void shouldOnlyRunTheTestIfSomeCriteriaAreMet(){
//Assumptions.assumeTrue(Fixture.apiVersion() < 10);
assertEquals(1,1);
}
@ParameterizedTest(name = "{0}")
@DisplayName("Should create shapes with different numbers of sides")
@ValueSource(ints = {3,4,5,8,14})
void shouldCreateShapesWithDifferentNumbersOfSides(int expectedNumberOfSides){
Shape shape = new Shape(expectedNumberOfSides);
assertEquals(expectedNumberOfSides, shape.numberOfSides());
}
@ParameterizedTest
@DisplayName("Should not create shapes with different numbers of sides")
@ValueSource(ints = {0, 1, 2, Integer.MAX_VALUE})
void shouldMotCreateShapesWithDifferentNumbersOfSides(int expected){
assertThrows(IllegalArgumentException.class,
() -> new Shape(expected));
}
@Nested
@DisplayName("When a shape has been created")
class WhenShapeExists{
private final Shape shape = new Shape(4);
@Nested
@DisplayName("Should allow")
class ShouldAllow{
@Test
@DisplayName("seeing the number of sides")
void seeingTheNumberOfSides(){
assertEquals(4, shape.numberOfSides());
}
@Test
@DisplayName("seeing the description")
void seeingTheDescription(){
assertEquals("Square", shape.description());
}
}
@Nested
@DisplayName("Should not")
class ShouldNot{
@Test
@DisplayName("be equal to another shape with the same number of sides")
void beEqualToAnotherShapeWithTheSameNumberOfSides(){
assertNotEquals(new Shape(4), shape);
}
}
}
}- Shape.java
package com.example.demo.junit5;
public class Shape {
private final int numberOfSides;
public Shape(int numberOfSides){
if(numberOfSides < 3 || numberOfSides == Integer.MAX_VALUE){
throw new IllegalArgumentException();
}
this.numberOfSides = numberOfSides;
}
public int numberOfSides(){
return numberOfSides;
}
public String description(){
String s = "";
if(numberOfSides == 4) {
s += "Square";
}
return s;
}
}끝으로 JUnit의 annotation들을 설명해 둔 포스팅을 첨부한다
🧩 과제 1. live-study 대시 보드를 만드는 코드를 작성한다.
- 깃헙 이슈 1번부터 18번까지 댓글을 순회하며 댓글을 남긴 사용자를 체크 할 것.
- 참여율을 계산하세요. 총 18회에 중에 몇 %를 참여했는지 소숫점 두자리가지 보여줄 것.
- Github 자바 라이브러리를 사용하면 편리합니다.
- 깃헙 API를 익명으로 호출하는데 제한이 있기 때문에 본인의 깃헙 프로젝트에 이슈를 만들고 테스트를 하시면 더 자주 테스트할 수 있습니다.
우선 나는 갑자기 이런 API를 만들게 될 줄 몰랐고, 깃헙 라이브러리가 있다는 것도 몰랐다...
그래서 좀 오랜 시간이 걸릴지라도 차근차근 해봤다.
- 깃험API를 이용해서 깃헙과의 연결에 필요한 변수들을 설정한다
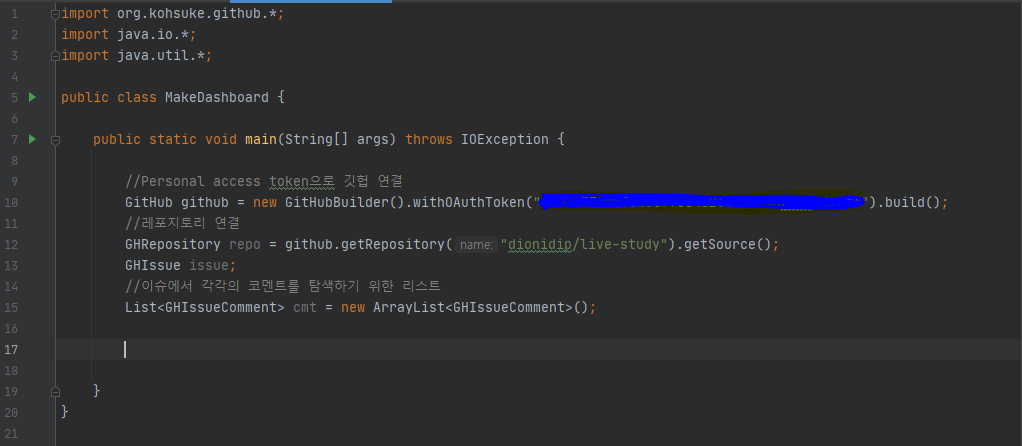 파란 부분에는 자신의 Personal access token을 입력한다
파란 부분에는 자신의 Personal access token을 입력한다
- 각 이슈에서 코멘트를 단 아이디를 파악하기 위해(중복제거) 필요한 알고리즘을 고민해봤다.
- HashSet
- Set 인터페이스의 구현 클래스이다.
- 중복을 제거해서 객체들을 저장할 수 있다.
- HashMap
- Map 인터페이스를 구현한 Map 컬렉션이다.
- Map은 키와 값으로 구성된 Entry 객체를 저장하는 구조를 가지고 있는 자료구조이다.
- 값은 중복될 수 있지만, 키는 중복될 수 없다.
- 해시함수를 통해 Key와 Value가 저장되는 위치가 결정된다
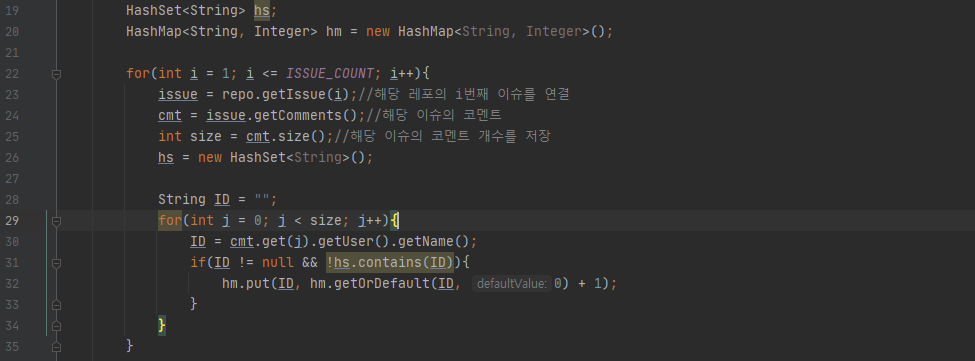 각각의 이슈에서 HashSet을 초기화하고 HashSet에 해당 코멘트의 ID가 없을 때 HashMap에 추가한다. 다음의 이슈에서 같은 ID의 코멘트가 있을 경우 HashMap에서 해당 Key값의 Value를 +1 해준다.
각각의 이슈에서 HashSet을 초기화하고 HashSet에 해당 코멘트의 ID가 없을 때 HashMap에 추가한다. 다음의 이슈에서 같은 ID의 코멘트가 있을 경우 HashMap에서 해당 Key값의 Value를 +1 해준다.
-
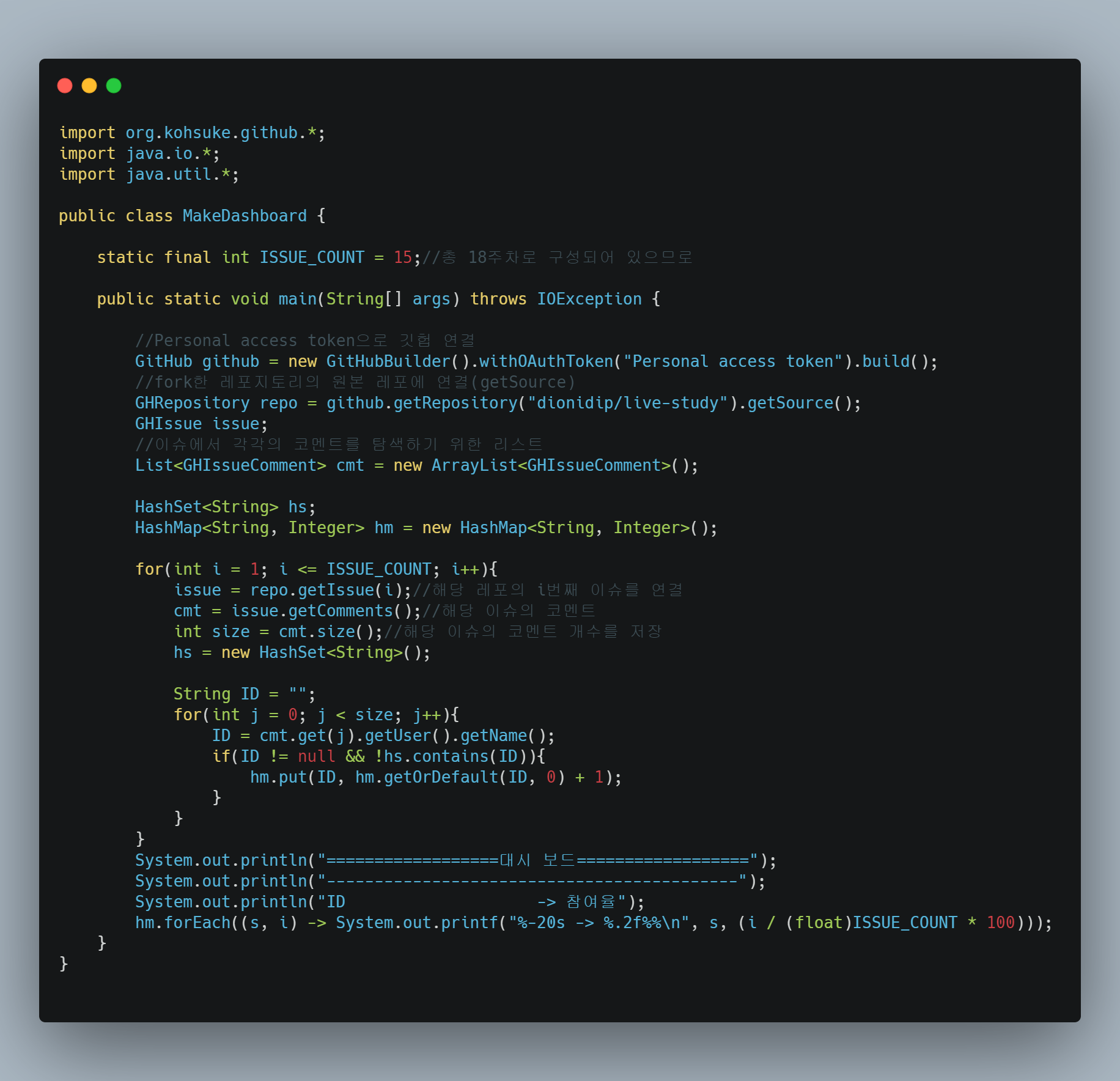
소스코드
-
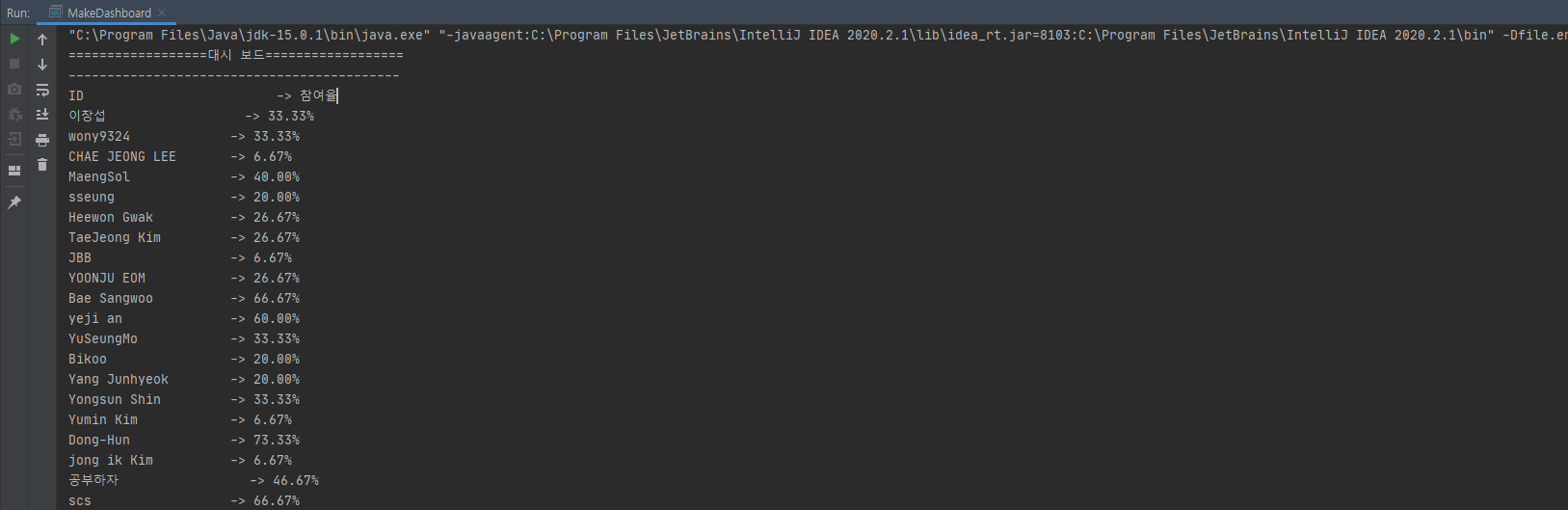
결과
🧩 과제 2. LinkedList를 구현하세요.
✔ LinkedList에 대해 공부하세요.
기본적인 형태의 자료구조로 '배열'이 있다.
하지만 배열은 한번 생성된 후에는 크기를 변경할 수 없고, 비순차적인 데이터의 추가 또는 삭제에 많은 시간이 소요된다는 단점이 있다.
이러한 배열의 단점을 보완하기 위해 만들어진 자료구조가 LinkedList이다.
배열은 모든 데이터가 연속적으로 존재하지만,
LinkedList는 불연속적으로 존재하는 데이터를 서로 연결한 형태로 구성되어 있다.
즉, LinkedLis의 각 요소(node)들은 자신과 연결된 다음 요소에 대한 참조값(주소값)과 데이터로 구성된다.
그림으로 나타내면 다음과 같다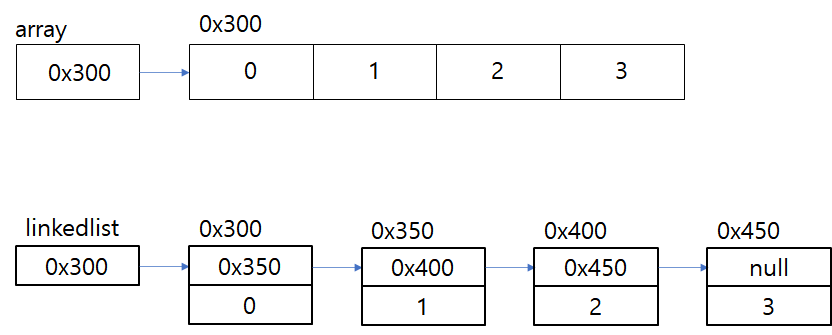
데이터 삭제
그렇다면 LinkedList에서 데이터의 삭제는 어떻게 하는 것일까?
생각보다 간단한데, 삭제하고 싶은 요소의 이전요소가 삭제하고자 하는 요소를 건너뛰고 다음 요소를 가리키도록 하면 된다.
단 하나의 참조만 변경하고 데이터의 복사가 없으므로 배열보다 처리속도가 빠르다.
그림으로 나타내면 다음과 같다
데이터 추가
LinkedList에서 데이터를 추가하기 위해서는 몇 가지 단계가 필요하다.
1. 새로운 요소를 생성한다
2. 추가하고자 하는 위치의 이전요소의 참조를 새로운 요소에 대한 참조로 변경한다
3. 추가한 요소가 그 다음 요소를 참조하도록 변경한다
이 또한 많은 연산이 필요한 것이 아니므로 처리속도가 굉장히 빠르다.
그림으로 나타내면 다음과 같다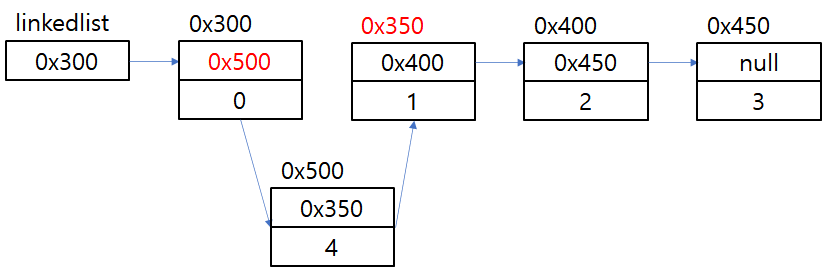
Doubly Linked List
LinkedList는 이동방향이 단방향이라서 다음 요소로의 접근은 쉽지만 이전 요소로의 접근은 어렵다.
이런 단점을 보완하기 위한 것이 Doubly Linked List(이중 연결리스트)이다.
단순히 LinkedList에 참조변수(이전 요소의 주소를 저장)를 하나 더 추가하였는데 다음 요소 뿐만 아니라 이전 요소에 대한 참조가 가능한 것이다.
Doubly Linked List는 LinkedList보다 각 요소에 대한 접근과 이동이 쉽기 때문에 LinkedList보다 더 많이 사용된다.
Doubly Circular Linked List
Doubly Linked List보다 접근성을 향상시킨 것이 Doubly Circular Linked List(이중 원형 연결리스트)이다.
단순히 리스트의 첫번째 요소와 마지막 요소를 연결시킨 것이다.
즉, 첫번째 요소의 이전요소가 마지막 요소가 되고, 마지막 요소의 다음요소가 첫번째 요소가 된다
✔ 정수를 저장하는 ListNode 클래스를 구현하세요.
1. 소스코드
package week4;
import java.util.*;
/*정수를 저장하는 원형 이중 연결 리스트를 구현해보자*/
public class ListNode {
private int data;
private ListNode prev;
private ListNode next;
private boolean isHead;
//생성자(더미노드)
ListNode(){
this.data = 0;
this.prev = this.next = this;
this.isHead = true;
}
//생성자(데이터)
ListNode(int n, ListNode prev, ListNode next){
this.data = n;
this.prev = prev;
this.next = next;
this.isHead = false;
}
public int size(){
if(!this.isHead){
return -1;
}
int size = 0;
ListNode list = this;
while(list.next != this){
size++;
list = list.next;
}
return size;
}
/* 특정 노드가 비어있는지 확인 */
public boolean isEmpty(ListNode head){
return head.next == head;
}
/* 특정 위치에 노드를 삽입 */
public ListNode add(ListNode head, ListNode nodeToAdd, int position){
//nodeToAdd를 넣을 위치 position을 결정
for(int i = 0; i < position-1; i++){
head = head.next;
}
nodeToAdd.next = head.next;
head.next = nodeToAdd;
nodeToAdd.prev = head;
return nodeToAdd;
}
/* 특정 노드를 삭제 */
public ListNode remove(ListNode head, int positionToRemove){
if(!isEmpty(head)){
ListNode delNode = head.next;
ListNode beforeNode = head;
for(int i = 0; i < positionToRemove-1; i++){
beforeNode = delNode;
delNode = delNode.next;
}
beforeNode.next = delNode.next;
return delNode;
}
return null;
}
public boolean contains(ListNode head, ListNode nodeToCheck){
int size = head.size();
while(size > 0){
if(head.data == nodeToCheck.data){
return true;
}
head = head.next;
size--;
}
return false;
}
}
내가 클래스를 효율적으로 구현했는지는 잘 모르겠다...😅
하지만 여러가지로 고민해봤고 몇 가지 필요한 메서드들을 만들어 보았다.
2. 테스트 코드
package week4;
import org.junit.jupiter.api.*;
public class ListNodeTest {
ListNode head;
ListNode node;
@BeforeEach
void before() {
head = new ListNode();
node = new ListNode(5, head, head);
head.add(head, node, 0);
}
@Test
@DisplayName("add Test")
void addTest() {
ListNode addNode = new ListNode(10, node, head);
Assertions.assertEquals(addNode, head.add(head, addNode, 2));
}
@Test
@DisplayName("remove Test")
void removeTest() {
Assertions.assertEquals(head, head.remove(node, 1));
}
@Test
@DisplayName("Contain Test")
void containTest() {
ListNode ctn = new ListNode();
head.add(head, ctn, 2);
Assertions.assertEquals(true, head.contains(head, ctn));
}
}
3. 결과
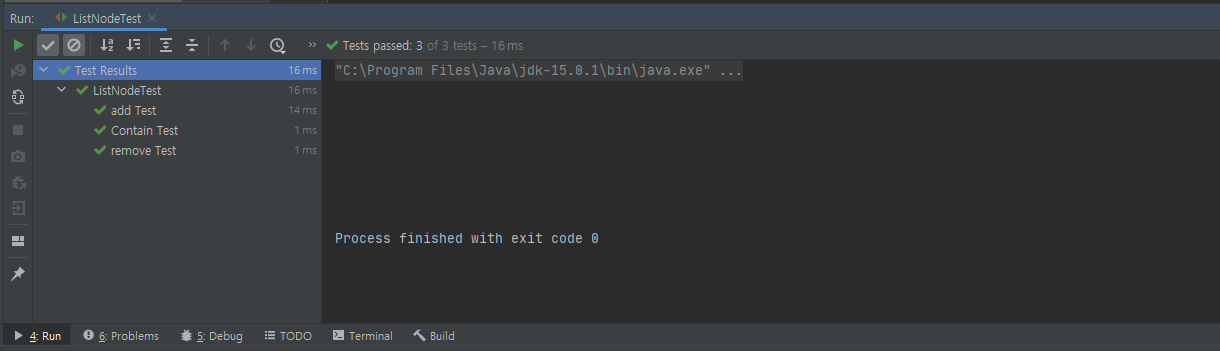 모든 테스트가 에러없이 잘 작동한다
모든 테스트가 에러없이 잘 작동한다
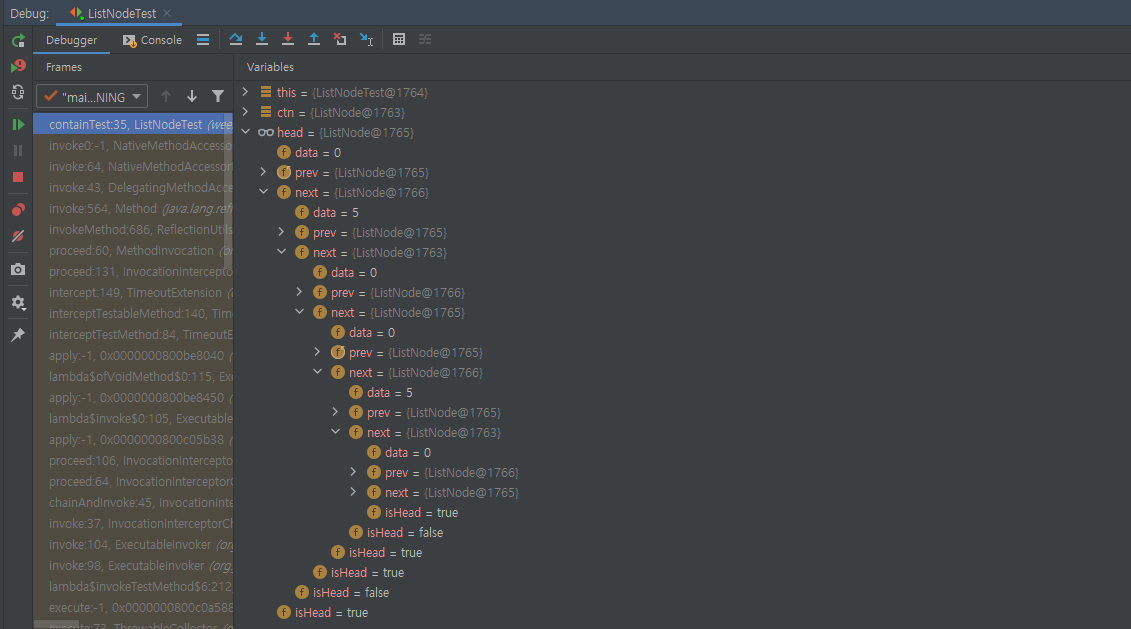
Assertions.assertEquals(true, head.contains(head, ctn))에서 breaking point를 설정하고 디버깅했을 때의 결과다.
계획했던대로 Doubly Circular Linked List의 모습이 나타난다.
🧩 과제 3. Stack을 구현하세요.
✔ int 배열을 사용해서 정수를 저장하는 Stack을 구현하세요
Stack은 마지막에 저장한 데이터를 가장 먼저 꺼내게 되는 LIFO(Last In First Out)구조를 가지는 자료구조이다.
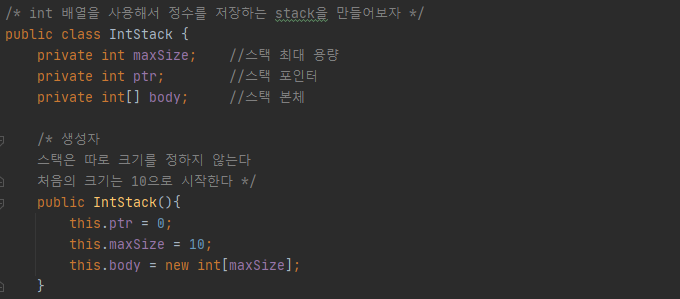 위와 같이 생성자를 만들었다.
위와 같이 생성자를 만들었다.
스택의 기본 크기는 10으로 잡았다.
✔ void push(int data)를 구현하세요.
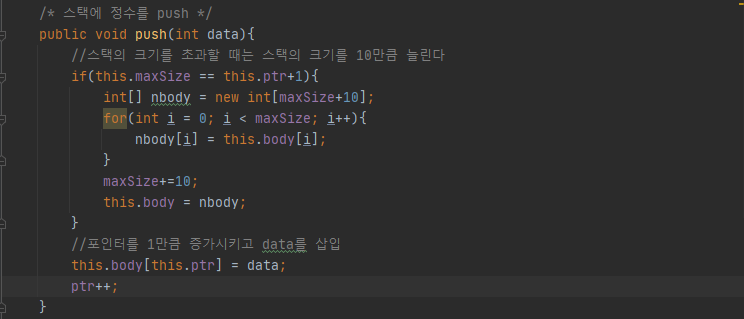 java에서 스택의 크기는 따로 설정하지 않고 일정 용량이 넘어가면 자동적으로 변한다고 알고 있어서 이를 적용해 보았다.
java에서 스택의 크기는 따로 설정하지 않고 일정 용량이 넘어가면 자동적으로 변한다고 알고 있어서 이를 적용해 보았다.
✔ int pop()을 구현하세요.
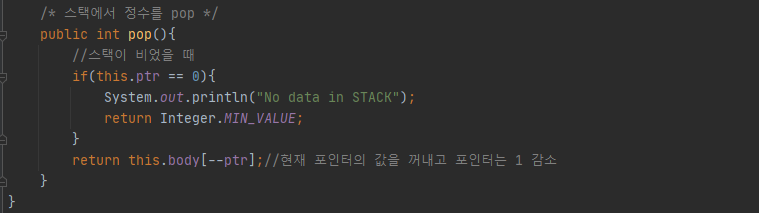 스택이 비었을 때를 예외사항으로 두었고 나머지에 대해서는 값을 빼내고 포인터 값을 -1 하는 것으로 했다.
스택이 비었을 때를 예외사항으로 두었고 나머지에 대해서는 값을 빼내고 포인터 값을 -1 하는 것으로 했다.
1. 소스코드
package week4;
import java.util.*;
/* int 배열을 사용해서 정수를 저장하는 stack을 만들어보자 */
public class IntStack {
private int maxSize; //스택 최대 용량
private int ptr; //스택 포인터
private int[] body; //스택 본체
/* 생성자
스택은 따로 크기를 정하지 않는다
처음의 크기는 10으로 시작한다 */
public IntStack(){
this.ptr = 0;
this.maxSize = 10;
this.body = new int[maxSize];
}
/* 스택에 정수를 push */
public void push(int data){
//스택의 크기를 초과할 때는 스택의 크기를 10만큼 늘린다
if(this.maxSize == this.ptr+1){
int[] nbody = new int[maxSize+10];
for(int i = 0; i < maxSize; i++){
nbody[i] = this.body[i];
}
maxSize+=10;
this.body = nbody;
}
//포인터를 1만큼 증가시키고 data를 삽입
this.body[this.ptr] = data;
ptr++;
}
/* 스택에서 정수를 pop */
public int pop(){
//스택이 비었을 때
if(this.ptr == 0){
System.out.println("No data in STACK");
return Integer.MIN_VALUE;
}
return this.body[--ptr];//현재 포인터의 값을 꺼내고 포인터는 1 감소
}
}2. 테스트 코드
package week4;
import org.junit.jupiter.api.*;
import org.junit.jupiter.params.ParameterizedTest;
import org.junit.jupiter.params.provider.ValueSource;
import static org.junit.jupiter.api.Assertions.*;
public class StackTest {
IntStack intStack;
@BeforeEach
public void before() {
intStack = new IntStack();
for(int i = 1; i <= 10; i++){
intStack.push(i * 3);
}
}
@ParameterizedTest
@DisplayName("Stack Push Test")
@ValueSource(ints = {100, 101, 102, 103})
void StackPushTest(int v) {
assertDoesNotThrow(() -> intStack.push(v));
}
@Test
@DisplayName("Stack Pop Test")
void StackPopTest() {
for(int i = 10; i > 0; i--){
assertEquals(i * 3, intStack.pop());
}
assertEquals(Integer.MIN_VALUE, intStack.pop());
}
}3. 테스트 결과
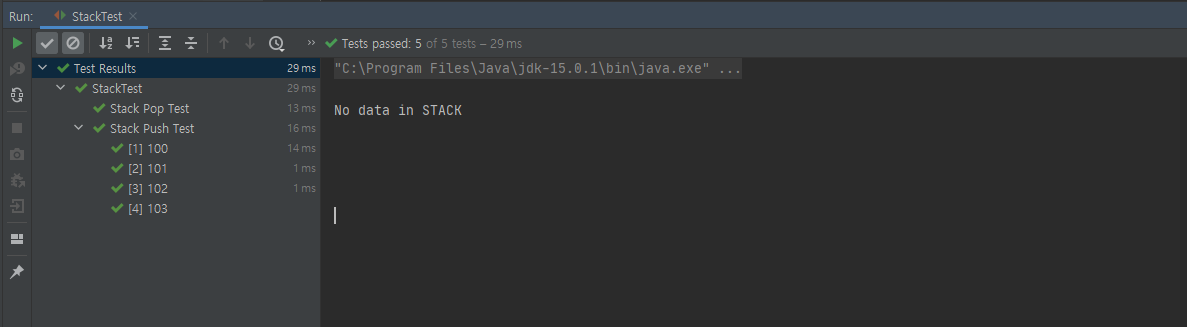
🧩 과제 4. 앞서 만든 ListNode를 사용해서 Stack을 구현하세요.
✔ ListNode head를 가지고 있는 ListNodeStack 클래스를 구현하세요.
 위에서 ListNode를 이중 원형 연결리스트로 만든 것을 후회하게 되는 과제다...
위에서 ListNode를 이중 원형 연결리스트로 만든 것을 후회하게 되는 과제다...
그래도 포인터를 두면 Stack의 LIFO를 구현할 수 있지 않을까해서 도전해봤다.
✔ void push(int data)를 구현하세요.
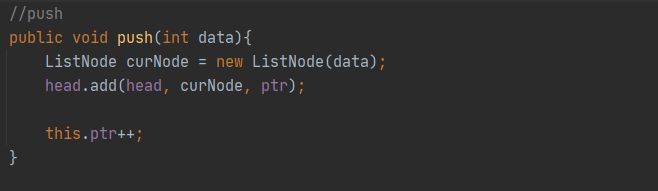 좀 더 간결한 방법이 뭐가 있을까 고민하다가 앞서 만든 ListNode 클래스에 data 파라미터를 가지는 생성자를 하나 더 만들어주었고, 그것을 사용했다. 그리고 push를 한 후에는 포인터를 1만큼 증가시킨다.
좀 더 간결한 방법이 뭐가 있을까 고민하다가 앞서 만든 ListNode 클래스에 data 파라미터를 가지는 생성자를 하나 더 만들어주었고, 그것을 사용했다. 그리고 push를 한 후에는 포인터를 1만큼 증가시킨다.
✔ int pop()을 구현하세요.
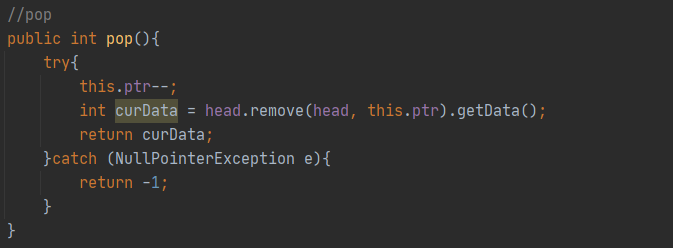 pop을 실행하기 전에 포인터를 1만큼 감소시킨다. 앞서 push에서 포인터를 1만큼 증가시켰으므로 감소한 후 pop을 해야 위치가 정확하다.
pop을 실행하기 전에 포인터를 1만큼 감소시킨다. 앞서 push에서 포인터를 1만큼 증가시켰으므로 감소한 후 pop을 해야 위치가 정확하다.
1. 소스코드
package week4;
public class ListNodeStack {
ListNode head;
int ptr;
public ListNodeStack(){
head = new ListNode();
ptr = 0;
}
//push
public void push(int data){
ListNode curNode = new ListNode(data);
head.add(head, curNode, ptr);
this.ptr++;
}
//pop
public int pop(){
try{
this.ptr--;
int curData = head.remove(head, this.ptr).getData();
return curData;
}catch (NullPointerException e){
return -1;
}
}
}2. 테스트 코드
package week4;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.api.Test;
public class ListNodeStackTest {
@Test
@DisplayName("Push & Pop Test")
void PushPopTest() {
ListNodeStack lns = new ListNodeStack();
lns.push(10);
lns.push(20);
lns.push(30);
Assertions.assertEquals(30, lns.pop());
Assertions.assertEquals(20, lns.pop());
}
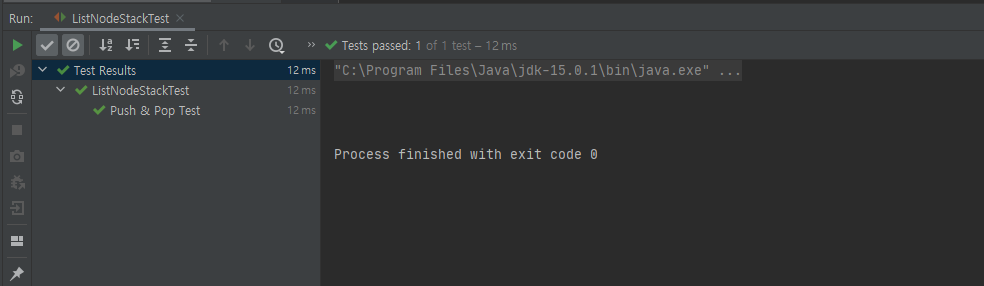
}3. 테스트 결과
🧩 과제 5. Queue를 구현하세요.
큐(Queue)는 스택과 반대로 처음에 저장한 데이터를 먼저 꺼내게 되는 FIFO(First In First Out)구조이다.
스택에서 저장과 추출을 각각 push, pop이라고 했다면,
큐에서는 offer(혹은 enqueue), poll(혹은 dequeue)이라고 한다.
군대에서 자바 언어로 되어있는 자료구조 서적을 공부했었는데 흐릿한 기억을 되짚어보며 작성해보았다...
✔ 배열을 사용해서
1. 소스코드
package week4;
public class QueueByArr {
private int max; //큐의 용량
private int num; //현재 데이터 수
private int[] queue; //본체
private int front; //큐의 첫번째 커서
private int rear; //큐의 마지막 커서
//생성자-큐의 용량을 파라미터로 가진다
public QueueByArr(int size){
this.max = size;
this.num = this.front = this.rear = 0;
try{
this.queue = new int[max];
}catch (OutOfMemoryError e){
this.max = 0;
}
}
//enqueue
public void enqueue(int data){
if(this.num >= this.max){
int[] nQueue = new int[this.max+10];
for(int i = 0; i < this.max; i++){
nQueue[i] = this.queue[i];
}
rear = this.max;
this.max += 10;
this.queue = nQueue;
}
this.queue[this.rear++] = data; //새로운 데이터를 넣어주고 큐의 마지막 요소 포인터를 1 증가
this.num++; //큐에 담신 데이터의 수를 1 증가
if(this.rear == this.max) this.rear = 0;//링 버퍼를 사용하므로 rear == max인 경우는 한 바퀴 돌았다는 의미
}
//dequeue
public int dequeue() throws EmptyQueueException{
if(this.num <= 0)
throw new EmptyQueueException();//큐가 비어있을 때
int data = this.queue[front++]; //가장 앞에 있는 데이터를 빼내고 포인터 커서를 1 증가
this.num--; // 큐에 담긴 데이터 수 1 감소
if(front == max) front = 0; // 한바퀴 돌았다는 의미
return data;
}
//큐가 비어있을 때의 예외사항
public class EmptyQueueException extends RuntimeException{
public EmptyQueueException(){}
}
}2.테스트 코드
package week4;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.api.Test;
public class QueByArrTest {
@Test
@DisplayName("Enqueue and DequeueTest")
void EnqueueDequeueTest() {
QueueByArr que = new QueueByArr(1);
que.enqueue(5);
que.enqueue(4);
que.enqueue(3);
Assertions.assertEquals(5,que.dequeue());
}
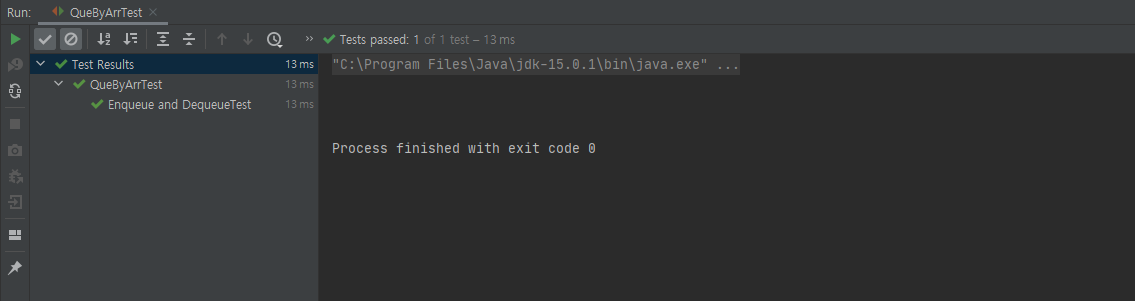
}3. 테스트 결과
✔ ListNode를 사용해서
앞서 작성했던 ListNode 코드에서는 오류를 찾지 못했는데 ListNode로 큐를 만들려고하니 오류가 발견되었다...!
여러가지 테스트가 이래서 중요한 것인가 실감함😁
바로 size() 메서드에서 변수 size의 초기값을 1로 세팅하는 것!
그래야 리스트에 데이터를 추가할 때 첫번째 노드부터 차례대로 저장이 된다.
size를 0으로 초기화했을 때는 두번째 enqueue를 했을 때 첫번째 노드로 enqueue 되는 오류가 발생한다.
1.소스코드
package week4;
public class QueueByLN {
ListNode head;
public QueueByLN(){
head = new ListNode();
}
public void enqueue(int data){
head.add(head, new ListNode(data), head.size());
}
public int dequeue(){
return head.remove(head, 0).getData();
}
}2. 테스트 코드
package week4;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.api.Test;
public class QueueByLNTest {
@Test
@DisplayName("enqueue and Dequeue Test")
void enqueueDequeueTest() {
QueueByLN list = new QueueByLN();
list.enqueue(5);
list.enqueue(4);
list.enqueue(3);
Assertions.assertEquals(5, list.dequeue());
}
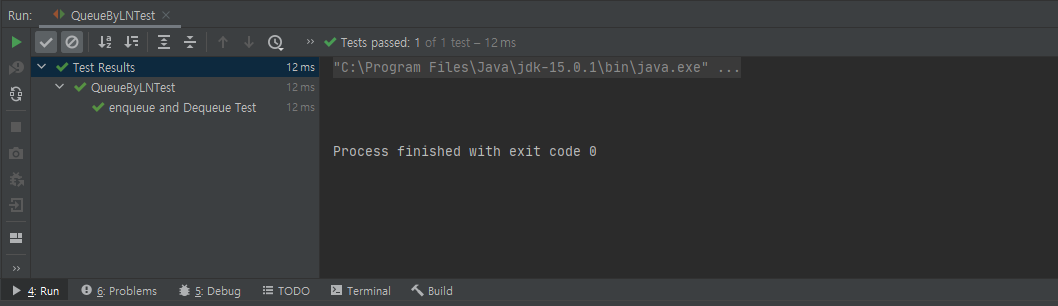
}3. 테스트 결과

애썼다 자라