.png)
actiavation function → 출력을 지정하는 함수
ex) softmax, sigmoid, linear...
Dense(8, input_dim = 4, init = 'uniform', activation = 'relu') → 32개의 가중치를 학습해야함(input*output)
- 첫번째 인자 : 출력 뉴런의 수
- input_dim : 입력 뉴런의 수
- init : 가중치 초기화 방법을 설정
- uniform : 균일 분포
- normal : 가우시안 분포
- activation : 활성화 함수 설정
- linear : 디폴트 값, 입력 뉴런과 가중치로 계산된 결과값이 그대로 출력
- relu : rectifier함수, 은닉층에 주로 쓰음
- sigmoid : 시그모이드 함수, 이진 분류 문제에서 출력층에 주로 쓰임
- softmax : 소프트맥스 함수, 다중 클래스 분류 문제에서 출력층에 주로 쓰임
metrics를 지정해주면 학습과정을 볼 수 있다.
mae → mean absolute error 평균 절대 오차
epochs → 반복 횟수
batchsize → 몇 개를 잘라서 학습 할 지
코드 실습
get_weight
weight, bias를 출력해준다.
데이터셋 구성
- X
- 걸음 수
- 이동 거리
- 정적인 시간(분)
- 약간 활동적인 시간(분)
- 상당히 활동적인 시간(분)
- 매우 활동적인 시간(분) - Y
- 칼로리 소모량
다음과 같이 데이터셋을 구성합니다. - 훈련셋: 1번째 ~ 100번째 샘플
- 시험셋: 101번째 ~ 125번째 샘플
x = df[['걸음 수', '이동 거리', '정적인 시간(분)', '약간 활동적인 시간(분)', '상당히 활동적인 시간(분)', '매우 활동적인 시간(분)']]
y = df['칼로리 소모량']
x_train = x[:100]
y_train = y[:100]
x_test = x[100:]
y_test = y[100:]
데이터 전처리
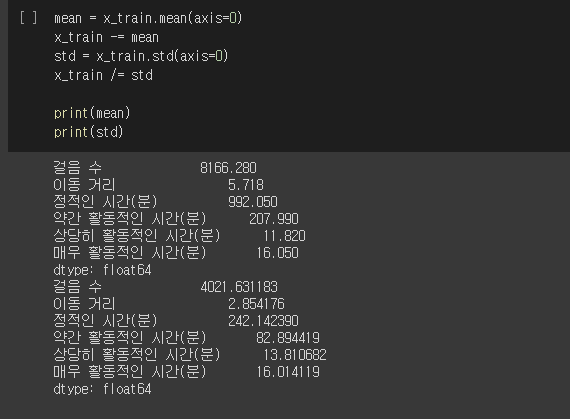
속성별로 다른 스케일을 가진 데이터를 입력하면 스케일이 큰 속성에 영향을 많이 미치는 경우가 발생하기 때문에, 정규화 과정을 해주게 된다. 속성별로 평균을 구하고 각 인스턴스에 평균을 빼고 표준 편차로 나누어주었다.
-> 시험셋을 입력할때도 필요하는 값을 저장해둠
mean = x_train.mean(axis=0)
x_train -= mean
std = x_train.std(axis=0)
x_train /= std
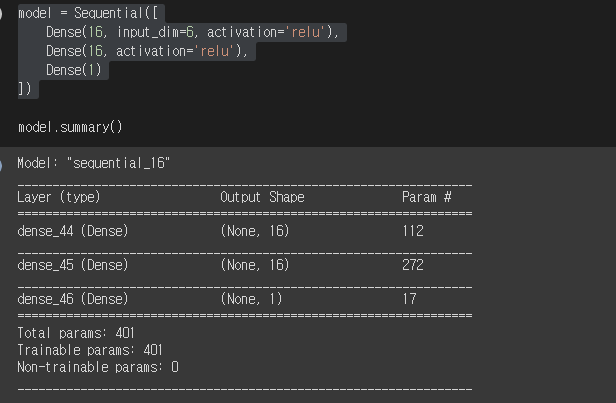
모델 network 설계
model = Sequential([
Dense(16, input_dim=6, activation='relu'),
Dense(16, activation='relu'),
Dense(1)
])
모델 complie
model.compile(loss='mse', optimizer='rmsprop', metrics=['mae']) # 수치예측은 보통 mse다.
모델 훈련
model.fit(x_train, y_train, epochs=5000, batch_size=32)
시험셋으로 평가
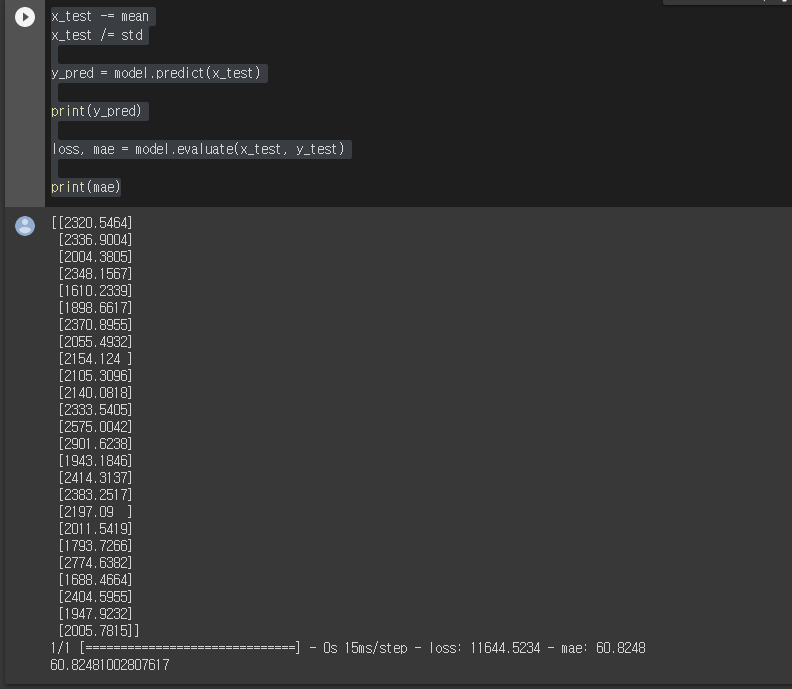
x_test -= mean
x_test /= std
y_pred = model.predict(x_test)
print(y_pred)
loss, mae = model.evaluate(x_test, y_test)
print(mae)