매일 끊김없는 온라인 강의의 늪이 시작되었다!
오늘의 수업 일정은 이러했다.
이제 열심히 함 달려보자!
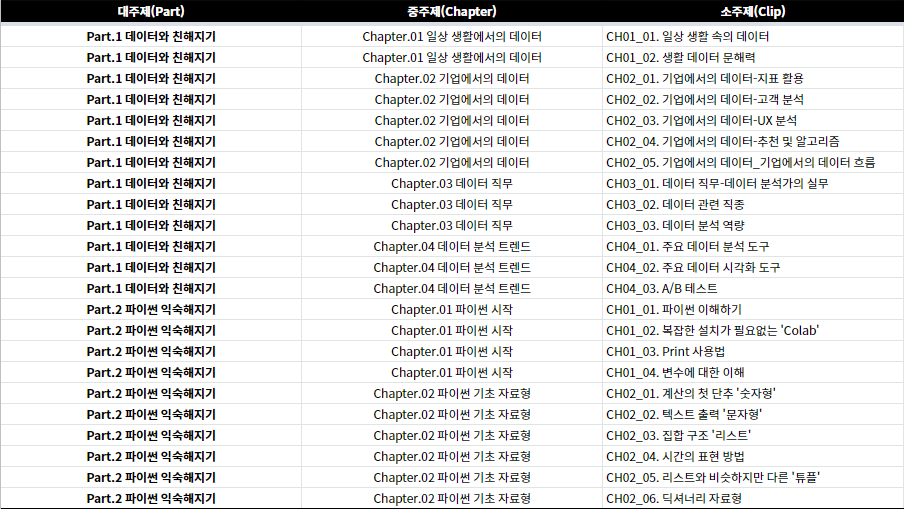
Part1. 데이터와 친해지기
Ch1. 일상 생활에서의 데이터
Ch1-1. 일상 생활 속의 데이터
데이터를 사용한다는 것은 마냥 어려운 일은 아니다!
다이어트를 하는 사람들이 매일 식단을 기록하는 것도 데이터 기록이고, 정리한 식단표를 보고 내 식습관을 진단하는 것은 데이터 분석이라고 할 수 있다.
즉 우리는 하루하루 생활하면서도 데이터를 끊임없이 만들고 살아간다.
수업에서의 예시는 다음과 같았다.
- 교육 : 시험 및 수업성적, 수업자료 등
- 미디어 : 기사, 구인공고, 광고 등
- 온라인 서비스 : 쇼핑, 게임, 메일, 음악, 웹서핑 등
- 그 외 : 금융거래 등
우리는 넘쳐나는 데이터를 잘 이해하고 활용할 필요가 있다!
Ch1-2. 생활 데이터 문해력
데이터의 오해 사례를 하나 들어주면서 데이터 문해력의 중요성을 이야기했다.
1940년대 소아마비 환자수의 시계열 데이터를 분석하던 중 아이스크림 섭취 시계열 데이터와의 상관관계를 발견하여 아이스크림이 소아마비에 영향이 있다고 무려 보건전문가들이 주장했다.
이것이 날씨라는 외생 변수에 의해 공통적인 영향을 받았다는 것이 무려 30년이나 지나서 입증되었다고 한다.
이처럼 데이터는 잘쓰면 훌륭하지만, 반대로 잘못 해석해도 단순한 의견보다 반박하기가 어렵기 때문에 위험한 무기가 될 수도 있다는 뜻이다.
데이터 이해의 기본은 4가지가 있다.
- 데이터 출처 확인
- 데이터 사용 목적 이해
- 데이터가 만들어진 내용 이해
- 누락된 부분 파악
데이터 활용은 '논리'가 없이는 이루어질 수 없기 때문에 데이터는 제대로 되었는지, 허점은 없는지, 해석논리에 문제는 없는지 잘 살펴봐야 한다.
Ch2. 기업에서의 데이터
기업에서의 데이터 사용은 크게 4가지로 나눌 수 있다.
- 지표 파악
- 고객 분석
- 사용성 분석
- 새로운 기능
각 활용에 대해 알아보도록 하자.
Ch2-1. 지표 파악
좋은 지표에 대해서 이렇게 설명한다.
- 비즈니스와 현 상황을 고려해서 적합한 지표 생성
- 회사의 단계와 목표가 잘 반영되어야 함
- 비율로 나타낼 수 있을 것
- 시간에 따른 비교가 가능한 형태로 만들 것
- 이를 통해 어떤 결론을 설명하고 다음 행동에 반영이 가능할 것
- 너무 많은 지표를 사용하지 말 것
Ch2-2. 고객 분석
기업은 고객에게 서비스를 제공하고 이윤을 창출하는 것이 제1의 목적이다.
고객을 잘 이해하고 이에 맞는 서비스를 제공하는 것이 좋은 서비스를 만들어 나가는 데 필수적이다. 이때 데이터를 활용하는 경우가 많다.
실제 창업을 하게 된다면, 처음에 다들 Segmentation을 경험하게 될텐데 이것이 바로 시장의 플레이어들을 그룹으로 나누어 특징을 분석하는 과정이다.
이 제품을 사용하는 고객의 분포는 어떻게 되는가?
고객들이 가지고 있는 공통적인 특징이 있을까?
실제 저러한 질문에 답을 얻기 위해 다양한 분석이 활용된다.
분석 방안 사례는 다음과 같다.
-기여도 분석: 구매 전환율, 방문 정도 등
-코호트 분석(Cohort analysis): 유사 행동 집단의 그룹핑
-고객 행동 패턴 분석
-교차 분석: 서비스가 여러 플랫폼에서 제공될 때, 데이터를 교차하여 보다 넓은 범위의 사용자 분석
Ch2-3. 사용성 분석
UX(User experience)는 사용자 경험을 의미한다. 디자인 쪽에서 많이 쓰이는 용어로 단순히 이쁜 것을 넘어 제품의 사용성이 디자인에 중요한 요소라는 인식이 생기면서 등장한 용어라고 할 수 있다.
고객이 서비스를 잘 활용하고 있는지, 어느 부분에서 어려움을 느끼고 있는지를 세부적으로 다양한 방법으로 살펴보고 어려움을 해소해주는 일련의 과정을 의미한다.
목적
- 서비스 사용자 페르소나 설정, 검층, 관찰
- 사용자의 행동 데이터를 통한 실제 상황 이해
- 실제 사용자의 UX를 이해해서 숨어있는 현상 파악
사용 방안
- 상세 지표 해석: 페이지뷰, 페이지 히트맵, 리텐션 등
- User flow에 따른 Funnel(깔때기) 분석
- 활동 정보 상세 파악: 클릭, 터치, 스크롤, 체류시간 등
Ch2-4. 새로운 기능
데이터를 활용하여 모델링을 사용하는 경우다. 이 케이스는 대부분 기업의 서비스인 경우가 많다.
구글 : 검색엔진
유투브 : 추천알고리즘
루닛(Lunit) : X-ray, CT 이미지 분석을 통한 폐암진단
돌봄드림 : 심박 및 움직임 분석을 통한 ASD(자폐) 이상행동 감지
(돌봄드림 화이팅!ㅎㅎ)
여러 AI를 활용한 서비스와 제품들이 시장에 급격하게 늘어나고 있는 추세다.
Ch2-5. 추천 및 알고리즘
구글이 선도하고 있는 분야로 대부분의 대기업들은 모두 활용하고 있다고 보면 된다.
국내에서는 쿠팡을 대표 예시로 들 수 있다.
개인이 구매했던 내역과 클릭했던 상품을 토대로 다른 상품들을 추천하는 알고리즘을 탑재하고 있다.
추천 알고리즘의 핵심은 큐레이션이다.
제품 및 고객을 분류하고 데이터를 수집하여 구조화하는 것이 굉장히 중요하기 때문이다.
그 외에도 많이 쓰이는 알고리즘은 이상 탐지(anomaly detection)다.
어떤 특정한 도메인에서 일반적으로 예상되는 특징을 따르지 않는 데이터나, 정상으로 규정된 데이터와 다른 특징을 가지는 데이터를 찾아내는 것으로 제조업, 물류업, 금융업, 의료 등 다양한 분야에서 많이 활용되고 있다.
세부 활용 예시는 다음과 같다.
- 금융 및 게임에서의 부정 거래 및 사기 파악
- 공장에서의 제품 불량, 공정 이상 사례 탐지
- 의료에서의 이상 패턴 감지 후 질병 등 진단
Ch2-6. 기업에서의 데이터 흐름
기업 내부에서 관리하는 데이터 유형은 다음과 같다.
- Transaction
- Log
- Metadata
- Data Mart
기업에서 수집하는 외부 데이터 유형은 다음과 같다.
- GA(Google Analytics)
- 마케팅 툴
- 외부 통계 매체
데이터를 수집하고 관리하는 일련의 라인을 데이터 파이프라인 라고 부른다.
예전에는 ETL(Extract, Transform, Load) 이라는 표현을 많이 사용했지만, 다양한 프레임워크와 서비스들의 등장으로 복잡도가 늘고 비정형 데이터를 활용하는 경우가 많아 조금 더 포괄적인 용어인 데이터 파이프라인을 활용하는 것이 추세다.
- Capture(데이터 기록)
- Process(전처리 및 가공)
- Store(적재)
- Analysis(분석)
- Use(분석된 데이터를 바탕으로 활용 e.g. 시각화, 리포팅, 의사결정)
비즈니스 이해, 데이터 수집, 가공, 모델링, 개발 각각의 단계가 서로 유기적으로 구성되는 것이 데이터의 라이프사이클이라고 할 수 있다.
이는 머신러닝 모델링의 흐름과도 유사하다.
문제 정의 -> 데이터 수집 -> 전처리 -> 훈련 -> 기존모델(오픈소스)을 활용하여 알고리즘 구성 > 데이터 입력 > 예측 데이터 확인 > 평가 > 개선 > 추가 훈련
이 과정을
while True:
if you_are_dead():
break하면 된다.
Ch3. 데이터 직무
이 파트는 이미 첫날 들은 이야기들이었기 때문에 패스!
Ch4. 데이터 분석 트렌드
Ch4-1. 주요 데이터 분석 도구
데이터 분석에 다양한 도구가 쓰인다.
Python, R, SQL, Excel, GA(Google Analytics), FB(Firebase) 등이 있다.
그 중에서도 압도적 1위가 바로
Python
이다.
Python
오픈소스 프로그래밍 언어로 배우기 쉽고, 무료이며, 다양한 라이브러리가 있고, 어떤 환경에서든 사용할 수 있어서 여러 방면에서 널리 사용되고 있다.
데이터 분석에서의 python
- 프로그래밍 언어 중 배우기 용이하며, 다른 프로그래밍으로 확장 및 연계가 가능해서 사용자 증가 추세
- 과학 프로그래밍용으로 다양하게 활용할 수 있는 각종 라이브러리 제공
- 데이터 처리 및 기본 통계: Numpy, SciPy, Pandas, Scikit-learn 등
- 데이터 시각화: matbplotlib, seaborn 등
R
오픈소스 통계용 프로그래밍 언어로 다양한 데이터와 호환성이 좋고 기존부터 통계 분석에 활용되었어서 관련 기능이 많다. matlab이라는 유사하지만 과학에 특화된 언어도 있다.
- 통계 및 비전공자에게 상대적으로 진입 장벽이 낮은 언어
- 시각화, 시스템화를 위한 각종 편의 도구 제공
- 오픈소스 -> 무료
- 데이터 분석 관련 유용한 패키지 다수 제공
SQL
DB(Database)에 사용하는 언어로 DB 데이터를 조회 및 관리하기 위해 만들어진 언어다.
프로그래밍 언어보다 직관적이고 데이터를 다양하게 다룰 수 있어서, 데이터를 사용하는 여러 분야에서 활용도가 높다.
Google Analytics (Firebase)
웹/앱 분석 서비스로 최근 Firebase를 인수한 듯하다.
- 웹/앱 분석 서비스분야 시장점유율 압도적 1위
- 웹/앱 로그를 이용한 상세한 트래픽 및 방문자 분석 제공
- 여러 직군에서 다용도로 활용
- 유료 서비스
Excel (Spreadsheets)
표 형식으로 데이터의 조직, 분석, 저장을 가능케 하는 상호작용 컴퓨터 애플리케이션로 그래프 및 간단한 자료 관리, 회계, 통계 처리 기능, 값 예측, 자동화(매크로) 기능을 제공한다.
참고로VBA(Visual Basic for Application)라는 자체 언어를 가지고 매크로를 만들 수 있다.
필자는 6년전 VBA를 독학해서 기상관측 일일보고자료를 자동으로 제작하는 프로그램을 만들어놓고 1년간 꿀을 빤 전적이 있다.
각 툴들은 다음 목적에 맞게 활용하면 된다.
Data visualization -> R, Python, Visualization tools
Modeling -> Python, R
Data processing -> SQL, R, Python, Excel, Google Analytics
Data acquisition -> SQL (SQL-based query engine)
파이썬은 DB말고는 다 활용할 수 있으니 그냥 파이썬 하나만 확실히 파도 될 것 같다.
Ch4-2. 주요 데이터 시각화 도구
데이터 분석만큼 중요한게 데이터 시각화다.
내가 분석한 자료를 가공해서 이쁘고 보기 좋게 만들어서 상사에게 보고해야 짤리지 않기 때문이다.
시각적으로 보는 것만으로도 결과를 이해하기 쉽고, 인사이트가 떠오를 수 있으며 잘못된 부분을 찾을 수도 있기 때문에 중요한 것이다.
게다가 빠른 의사결정에 도움이 될 뿐더러 커뮤니케이션에도 강력한 도구가 된다.
시각화에 쓰이는 툴의 종류는 다음과 같다.
1. Tableau
전세계적으로 BI Dashboard 부문 시장점유율 1위인 솔루션이다!
직관적이고 사용하기 쉬운 Drag & Drop 기반의 사용자 인터페이스를 가지고, 다양한 종류의 시각화 기능 및 인터랙션 제공한다.
2. Google Data Studio
구글의 데이터 시각화 도구로 스프레드시트, 구글 애널리틱스, Google Ads, 빅쿼리, 유튜브 애널리틱스 등의 데이터를 쉽게 연결할 수 있어 구글 생태계를 활용할 수 있다는 것이 가장 큰 장점이다.
또한, 웹 베이스로 빠르고 공유 및 관리가 용이하고, 데이터 커넥터를 다양하게 지원하며, 유저관리/공동작업/권한관리가 용이하다.
3. Apache Superset
아파치 재단에서 만든 오픈소스 데이터 시각화 도구로 무료라는 점이 장점이다.
다양한 데이터 소스 지원과 다양한 계정 통합 방식 지원이 큰 장점이다.
Apache Spark, Storm, Kafka 등을 만든 아파치 재단이 만든 툴인만큼 빅데이터를 시각화할 때 좋다.
이 외에도 Grafana 여러 툴들이 있다.
대시보드를 제작할 때 가장 신경써야 할 점은 일관성, 목적성이다.
이 점을 명심하고 시각화 툴을 활용하자!
Ch4-3. A/B 테스트
A/B 테스팅이란 임의로 나눈 두 집단에게 서로 다른 컨텐츠를 제시한 후, 두 집단 중 어떤 집단이 더 높은 성과를 보이는지 정량적으로 평가하는 방식으로 '무작위 비교 연구'라 불리는 방법을 서비스에 적용한 방법론이다.
실제 마케팅에서 정말 많이 사용된다.
테스트 과정은 다음과 같다.
- 테스트 주제선정
- 두 포맷의 테스트 자료제작
- 실제 대상자를 두 그룹으로 분리
- 나눈 두 자료를 A, B 그룹에 각각 제공
- 결과가 우수한 내용을 실전에 반영
테스트 진행 시 고려사항은 다음과 같다.
- 테스트 목적 정립
- 평가할 지표 사전 정립 (ex. 클릭 수, 체류 시간 등)
- 사용자에 대한 사전 파악 (사용자의 숫자, 밸런스 있는 분포, 무작위 구분 보장을 어떻게 할 것인지)
- 외부요인 통제(중요)
다만, 많은 경우 여러가지 요소가 복합적으로 작용한다.
외부 변수의 영향으로 명확한 요인 및 원인 분석이 어려움
많은 실제 상황(실무)의 경우, 내생성을 위한 시스템을 일부 요소만으로 구축하기 어렵다.
상관관계는 인과관계를 나타내지 않는다는 점을 잊지 말자!
