💡 ETL :
Extract/Transform/Load. 다양한 데이터 소스로부터 데이터를 수집 및 처리하는데 사용되는 데이터 파이프라인
데이터 분석가들이 분석에 사용할 데이터를 정의하게 되면, 데이터 엔지니어에게 요청을 해서 해당 데이터를 처리해주길 원한다.
<업무 프로세스>
- 데이터 명세서 작성(분석가)
- 데이터 추출
- 데이터 변환
- 데이터 적재
대용량 데이터(e.g. 10,000,000 rows)를 한번에 처리하는 걸 데이터베이스 요청을 했다면 어떻게 처리해야 될까?
만약에 데이터 분석가가 Pandas를 이용해서 데이터를 처리하기로 정했을 때, 어떻게 처리할까?
이런 것들을 해결하는 방법이 data pipelining이다.
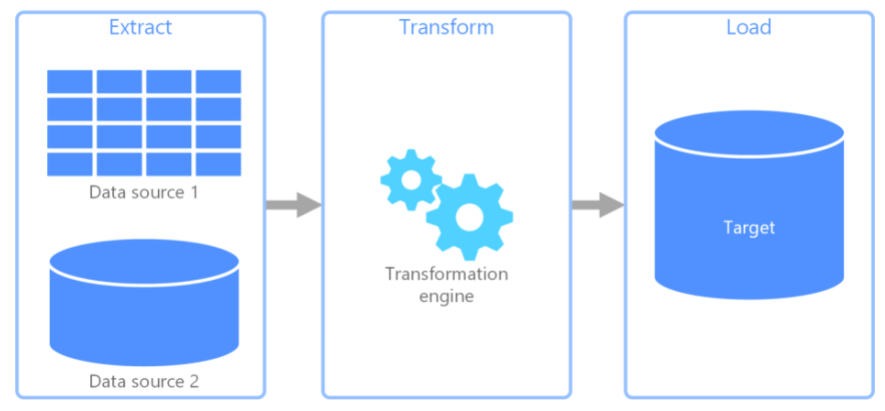
Extract(추출)
- 데이터를 원본 소스로부터 가져오는 작업
- SQL의 SELECT, 엑셀의 VLOOKUP 과 유사
- 원본 소스가 꼭 RDB일 필요는 없음 (RDB가 최대효율)
- 분석가가 정의한 모든 데이터를 다 가져옴
Transform(변환)
- 추출한 데이터를 분석에 필요한 형태로 변환
- 데이터의 포맷을 통일
- 분석 요청 사항에 맞는 형태로 저장 (Data Warehouse의 Schema 정의)
Load(적재)
- 변환된 데이터를
Data Warehouse(DW)에 저장 - 저장된 데이터를 분석가가 편의에 따라 자유롭게 사용 가능 (주로 API 형태로 제공)
- 원본 데이터의 정보 보존
특징
- ETL은 데이터 엔지니어의 손을 많이 탄다.
- 데이터 엔지니어가 직접 각 프로세스마다 처리 방식을 모두 구현해주어야한다.
- 명세사항이 변경된 경우에는 그에 맞춰서 변환을 다시 해야 한다.
- 대신에 솔루션 사용자 입장에서는 맞춰진 프로세스에 따라 편하게 데이터를 처리 및 사용이 가능하다.
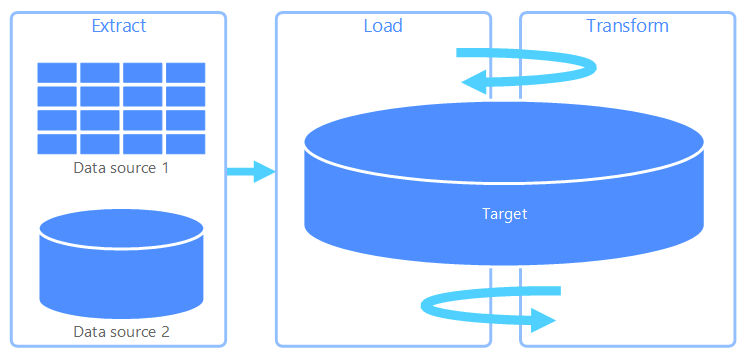
💡 ELT : Extract / Load / Transform. 변환이 일어나는 위치만 ETL과 다른 데이터 파이프라인.
특징
- ELT는 ETL과 각 단계의 정의는 동일 (Extract, Load, Transform)
- ELT는 ETL과 달리, 데이터를 일단 적재한 다음에 변환을 수행
- 데이터를 먼저 올려놓기 때문에 DW보다는
Data Lake(DL)가 적합 - DL은 정형/비정형/반정형 데이터 모두 자유롭게 적재가 가능하기 때문에 높은 저장 효율성
- 다양한 데이터 타입을 모두 저장할 수 있다.
- 단, 처리 속도가 ETL에 비해 느리다. (왜냐면 저장된 이후에 Transform을 제일 마지막에 하기 때문에)
- 대신에 저장의 유연성과 명세사항 변경에 따른 유연한 대처 가능
요약
- ETL에서 ELT로 트랜드 전환
- ETL에서는 DW 구성, ELT에서는 DL 구성

데이터 사이언티스트를 꿈꾸는 3년차 제품총괄입니다.