
문제배경
Human knot 이라는 것을 보신적이 있으신가요?

knot 이 매듭이라는 뜻이므로, 위의 사진과 같이 여러사람이 모여 서로 손을 마치 매듭처럼 붙잡는 것입니다. 그렇다면, 여러명의 사람이 둥글게 모여 모든 사람이 다른 사람과 손을 붙잡는다고 칩니다. 그 때, 서로의 팔이 교차되지 않도록 붙잡는 방법은 몇가지나 있을까요? 이 질문이 Catalan Numbers 문제의 핵심입니다.
RNA folding이라고 들어보셨나요? RNA folding은 RNA의 2차 구조가 형성되는 것을 의미합니다.
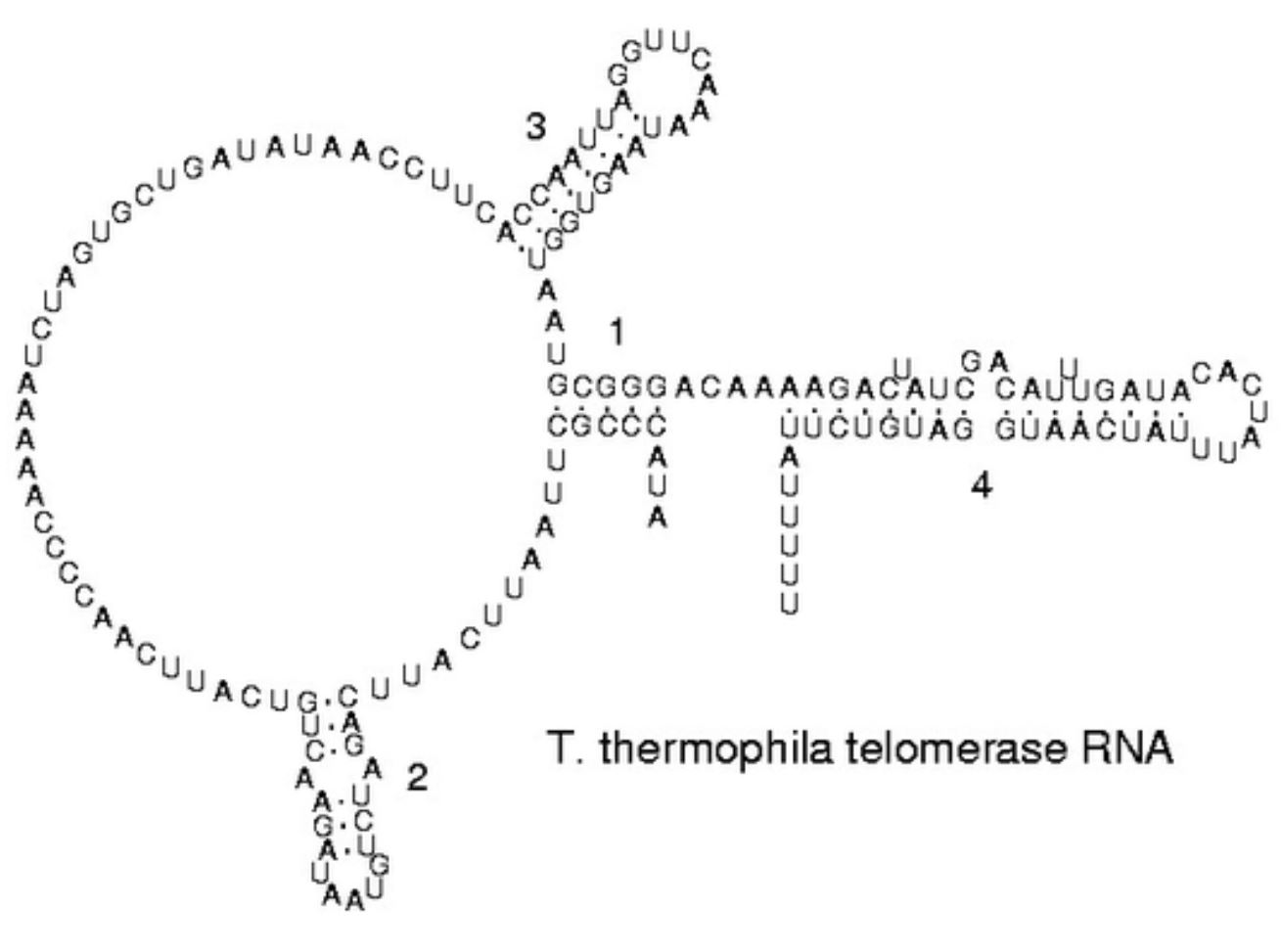
위의 그림은 T.thermophila telomerase RNA의 RNA folding의 모습입니다. 그림을 보면 RNA가 base pair를 이루며 매듭 모양을 엮인 것을 볼 수 있습니다. 이를 pseudoknot, 또는 hairpin loop라고 부릅니다. RNA는 선형구조를 지녔습니다. 그래서 RNA folding이 생성될 때 서로 교차할 수 없습니다. 예를 들면 10개의 염기가 있을때( 와 가 base pair를 이루었다면(), 은 과 base pair를 이룰 수 없습니다. 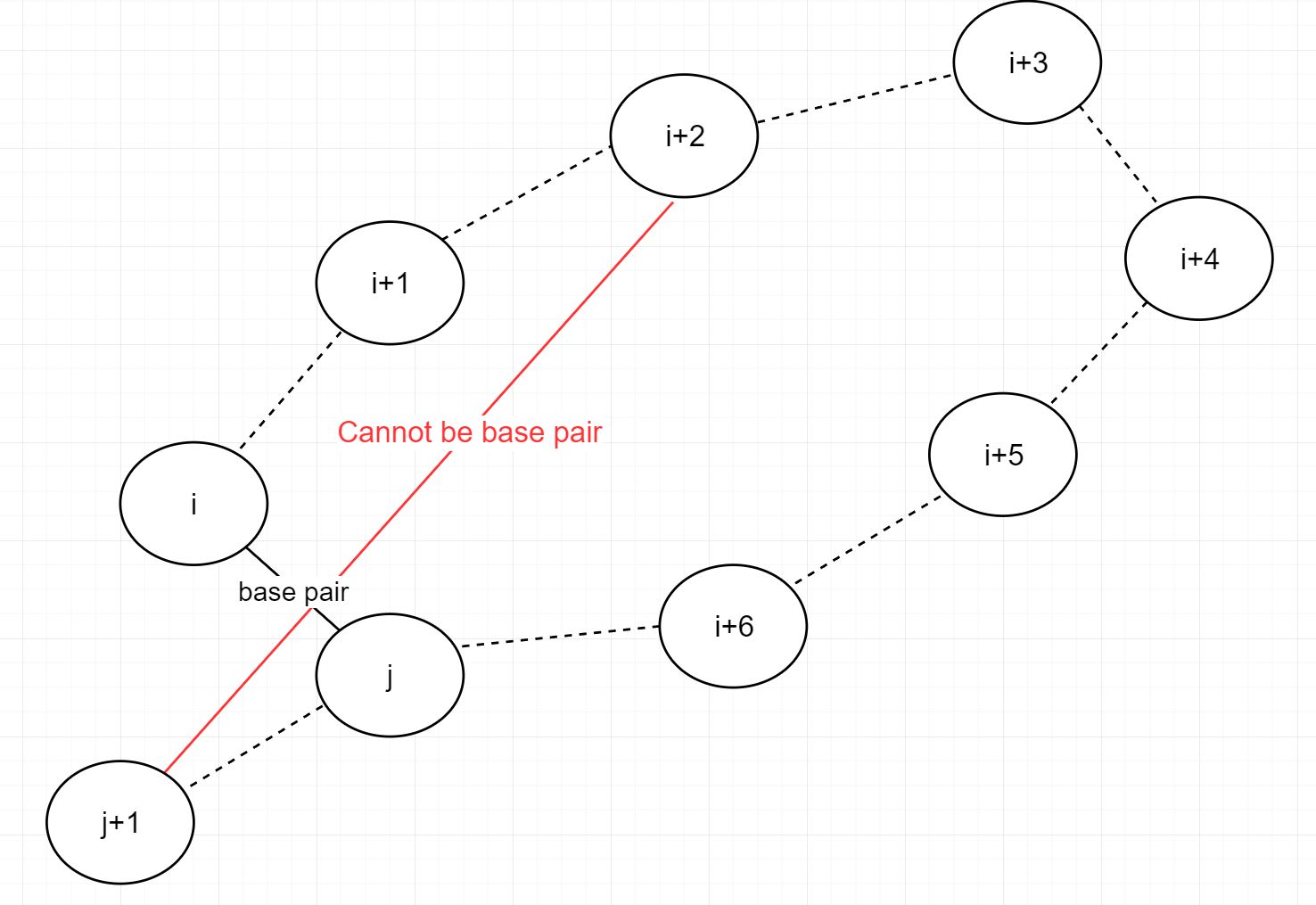 그 이유는 근본적으로 RNA는 선형이기 때문입니다.
그 이유는 근본적으로 RNA는 선형이기 때문입니다.
RNA가 선형이라는 점과 RNA가 RNA끼리 base pair를 이룰 수 있다는 점은 위에서 언급한 human knot 문제와 비슷합니다. 이 경우에는 팔이 겹치지 않게 하는 것이 아니라 팔 대신 base pair로 바뀔뿐입니다.
이 문제를 이용하여 RNA folding이 어떤 모양을 할지를 예측할 수 있습니다. 다행히 이번 문제에서는 RNA folding이 이루어질 수 있는 경우의 수만 예측하는 것입니다. 전체의 node 가 모두 연결되었지만 edge가 서로 교차하지 않은 전체 경우의 수를 Catalan Numbers 라고 합니다.
문제해설
원문
A matching in a graph is noncrossing if none of its edges cross each other. If we assume that the n nodes of this graph are arranged around a circle, and if we label these nodes with positive integers between 1 and n, then a matching is noncrossing as long as there are not edges {i,j} and {k,l} such that i<k<j<l.
A noncrossing matching of basepair edges in the bonding graph corresponding to an RNA string will correspond to a possible secondary structure of the underlying RNA strand that lacks pseudoknots.
In this problem, we will consider counting noncrossing perfect matchings of basepair edges. As a motivating example of how to count noncrossing perfect matchings, let denote the number of noncrossing perfect matchings in the complete graph . After setting , we can see that should equal 1 as well. As for the case of a general , say that the nodes of are labeled with the positive integers from 1 to 2n. We can join node 1 to any of the remaining 2n−1 nodes; yet once we have chosen this node (say m), we cannot add another edge to the matching that crosses the edge {1,m}. As a result, we must match all the edges on one side of {1,m} to each other. This requirement forces m to be even, so that we can write m=2k for some positive integer k.
There are 2k−2 nodes on one side of {1,m} and 2n−2k nodes on the other side of {1,m}, so that in turn there will be different ways of forming a perfect matching on the remaining nodes of . If we let m vary over all possible n−1 choices of even numbers between 1 and 2n, then we obtain the recurrence relation . The resulting numbers counting noncrossing perfect matchings in are called the Catalan numbers, and they appear in a huge number of other settings.
Given: An RNA string s having the same number of occurrences of 'A' as 'U' and the same number of occurrences of 'C' as 'G'. The length of the string is at most 300 bp.
Return : The total number of noncrossing perfect matchings of basepair edges in the bonding graph of s, modulo 1,000,000.
해설
원문만 봐서는 이해가 안되실것으로 생각합니다. 저도 이해를 하는데 시간이 걸렸습니다. 길게 설명해 놨지만 문제는 간단하게 설명이 됩니다. 염기서열을 주어졌을때, 이 염기서열의 catalan numbers를 구하라는 것입니다. 즉, 염기서열의 모든 염기를 base pair로 맞췄을 때, base pair가 서로 겹치는 경우가 없는 경우의 수를 구하라는 것입니다.
문제의 설명에서는 단순하게 linear한, 요소끼리의 제약사항 없이 연결 할 수 있는 경우의 수를 구하는 것이 묘사되어 있습니다. 하지만 이 문제에서는 한가지 제약사항이 있는데, A-U, G-C 끼리만 base pair를 이룰 수 있다는 것입니다. 이 제약 사항 안에서 Catalan numbers를 구하는 것이 문제의 핵심입니다.
문제해결
이 문제는 dynamic programming으로 해결할 수 있습니다. 그러기 위해서는 가장 작은 문제로 돌아가야 합니다. 가장 작은 문제는 바로 염기가 2개가 있고, 이 두개의 염기의 base pair를 열결하는 경우의 수입니다. 당연하게도 두개의 염기의 Catalan numbers는 1이 됩니다. 그렇다면 RNA sequence를 쪼개고 쪼개서 가장 작은 단위까지 쪼갠 뒤에, 이 작은 문제들을 더 큰 RNA sequence로 올라가며 해결 할 수 있지 않을까요?
문제를 해결하기 위해 사용한 전략은 아래의 그림으로부터 시작합니다.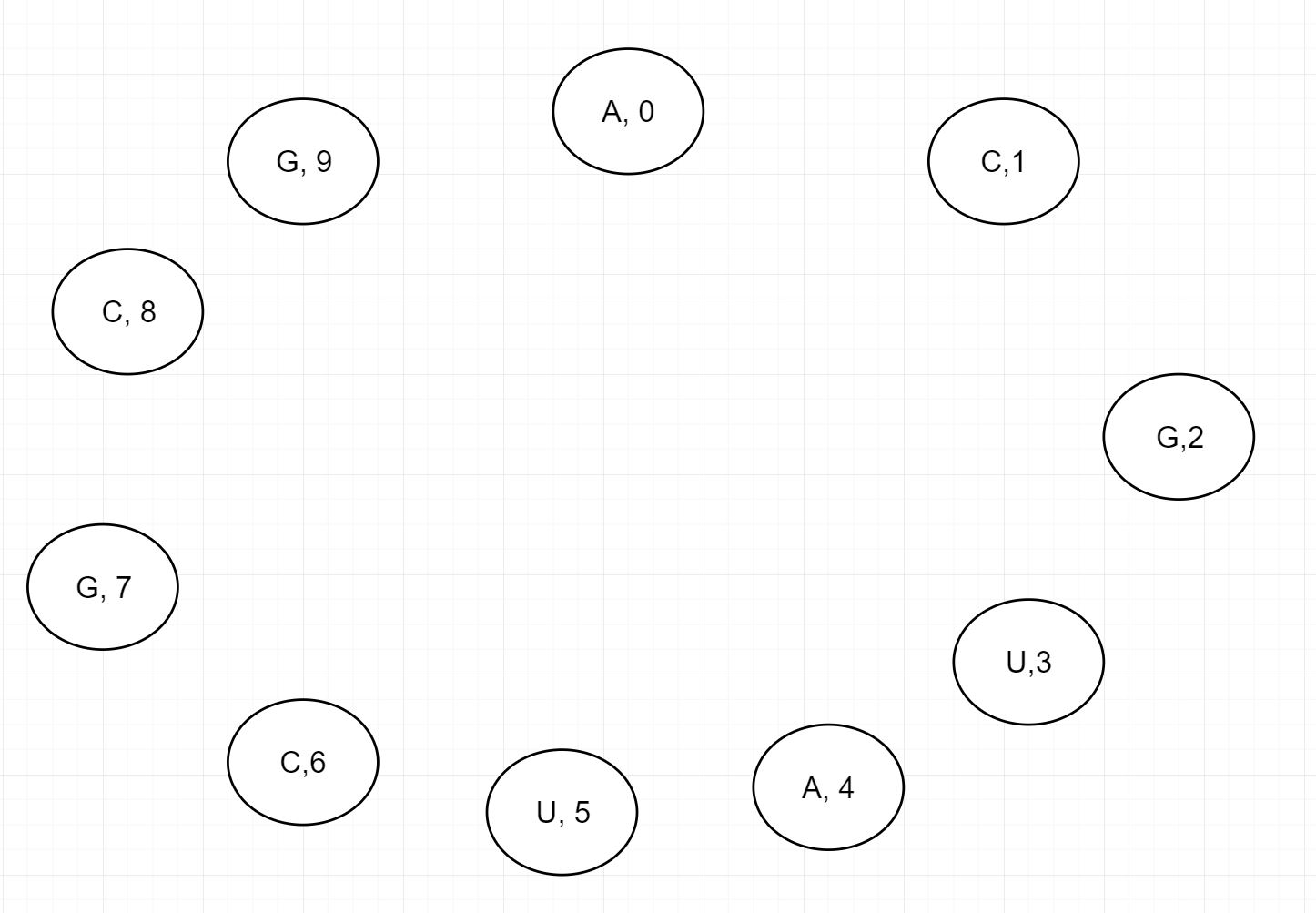
위의 그림과 같은 염기 서열이 주어졌을때 먼저 할 일은 일단 첫번째 서열인 A를 U와 짝을 짓는 것입니다.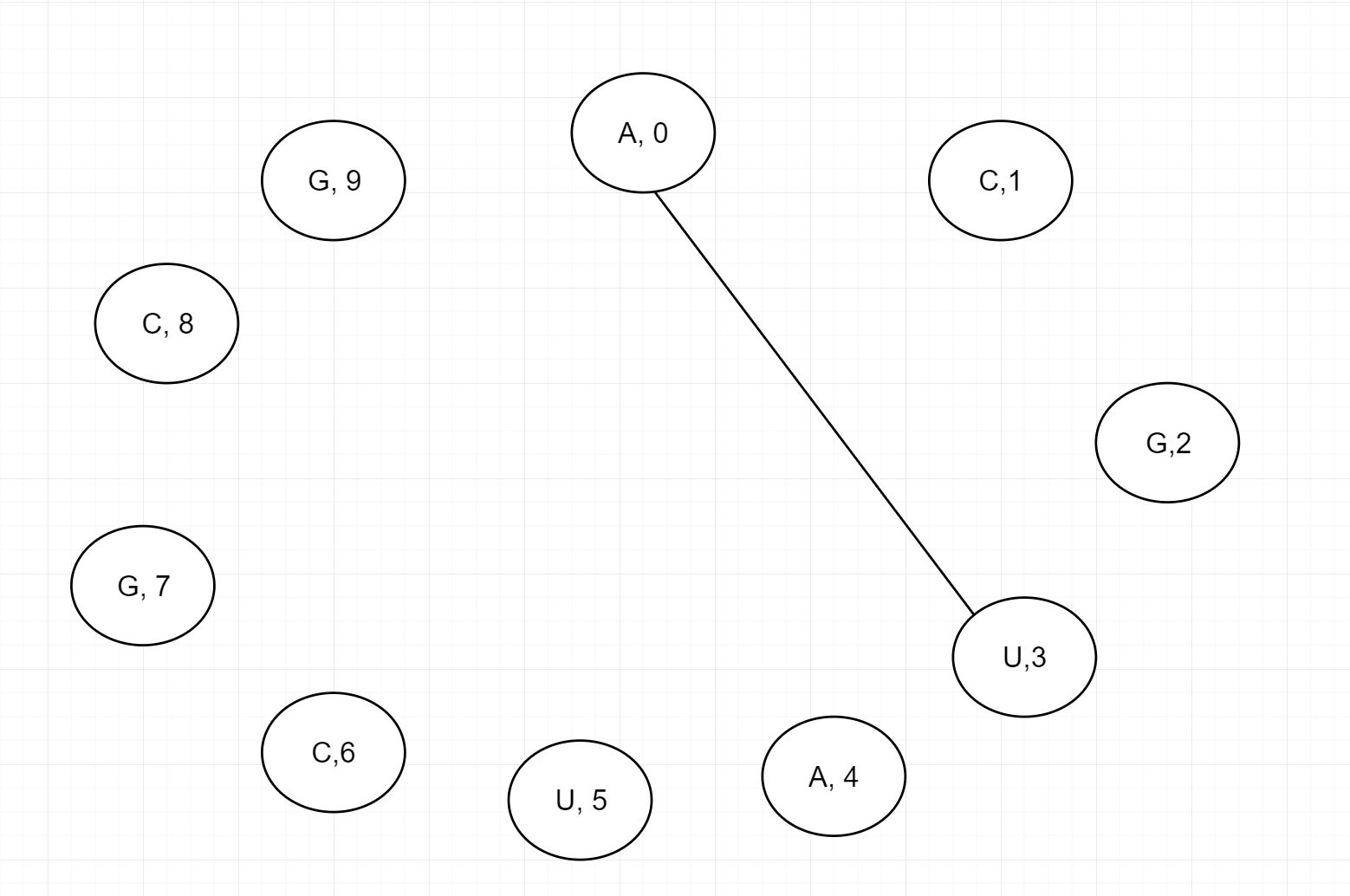
이렇게 A0과 U3를 base pair로 이어 붙이니 전체는 2 구역으로 쪼개집니다. 첫번째는 C1과 G2가 존재하는 오른쪽 구역. 두번째는 AUCGCG의 서열이 있는 왼쪽 구역입니다. 먼저 첫번째 구역부터 봅시다. C1과 G2가 있네요. 이 둘 밖에 없으니 가장 작은 문제에 해당해서 오른쪽에서는 1가지 경우의 수만 나올 수 있을 것입니다. 이제는 왼쪽 구역을 보면 AUCGCG가 있고 이는 문제가 더 작아 질 수 있음을 의미합니다. 그러면 왼쪽 구역에서 A4와 U5를 이어보겠습니다.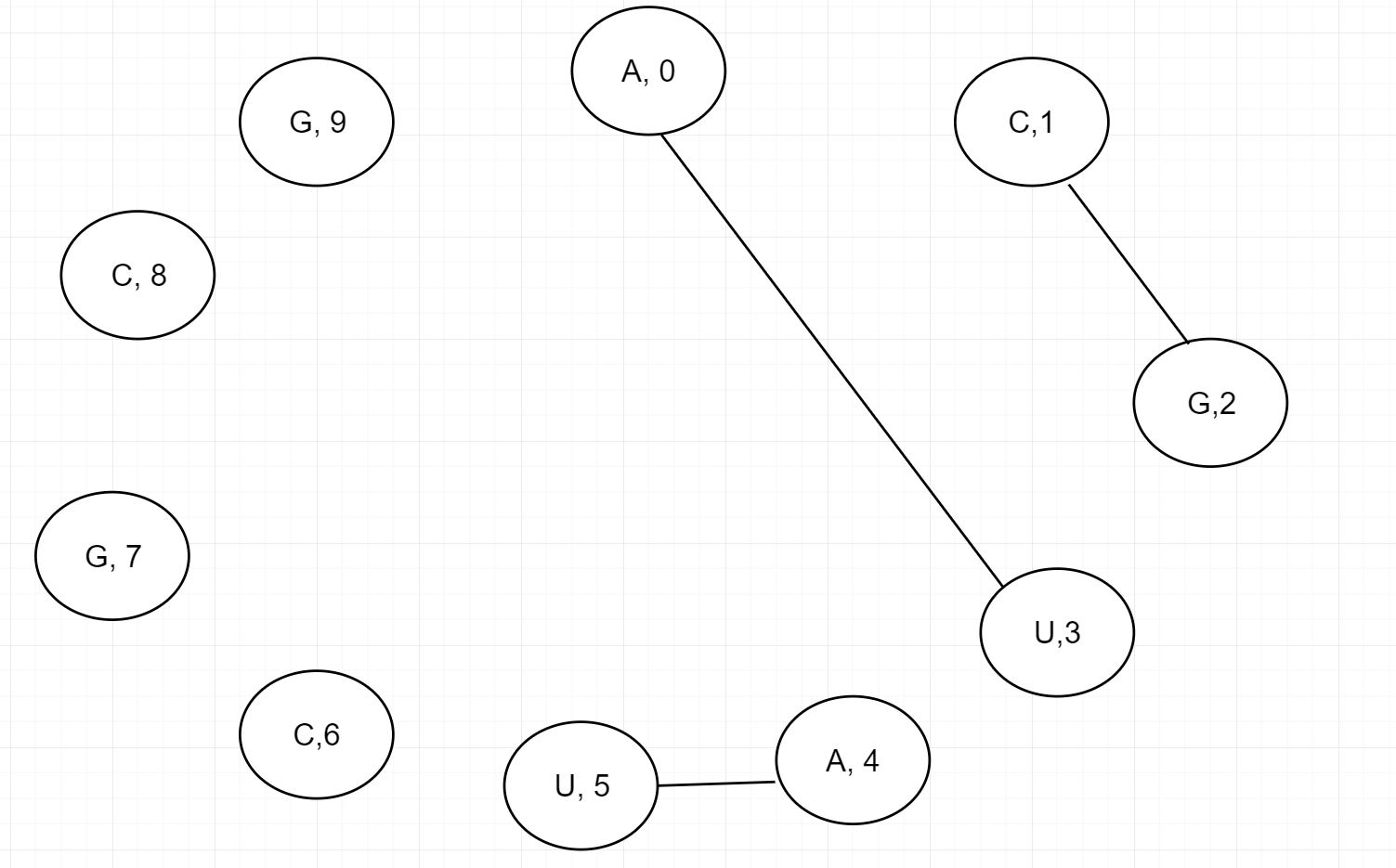
A4와 U5를 연결함으로써 2구역으로 또다시 나뉩니다. 첫번째는 아무것도 없는 아래구역, 그리고 오른쪽은 CGCG가 있는 왼쪽구역으로요. CGCG도 마찬가지입니다. C6와 G7을 연결하면 또다시 2 구역으로 나뉘고, 가장 작은 문제로 다시 귀결됩니다.
CGCG 구역에서는 C6가 G7 뿐만 아니라 G9와도 연결 될 수 있습니다. 그러므로 CGCG 구역에서 catalan numbers는 2가 됩니다.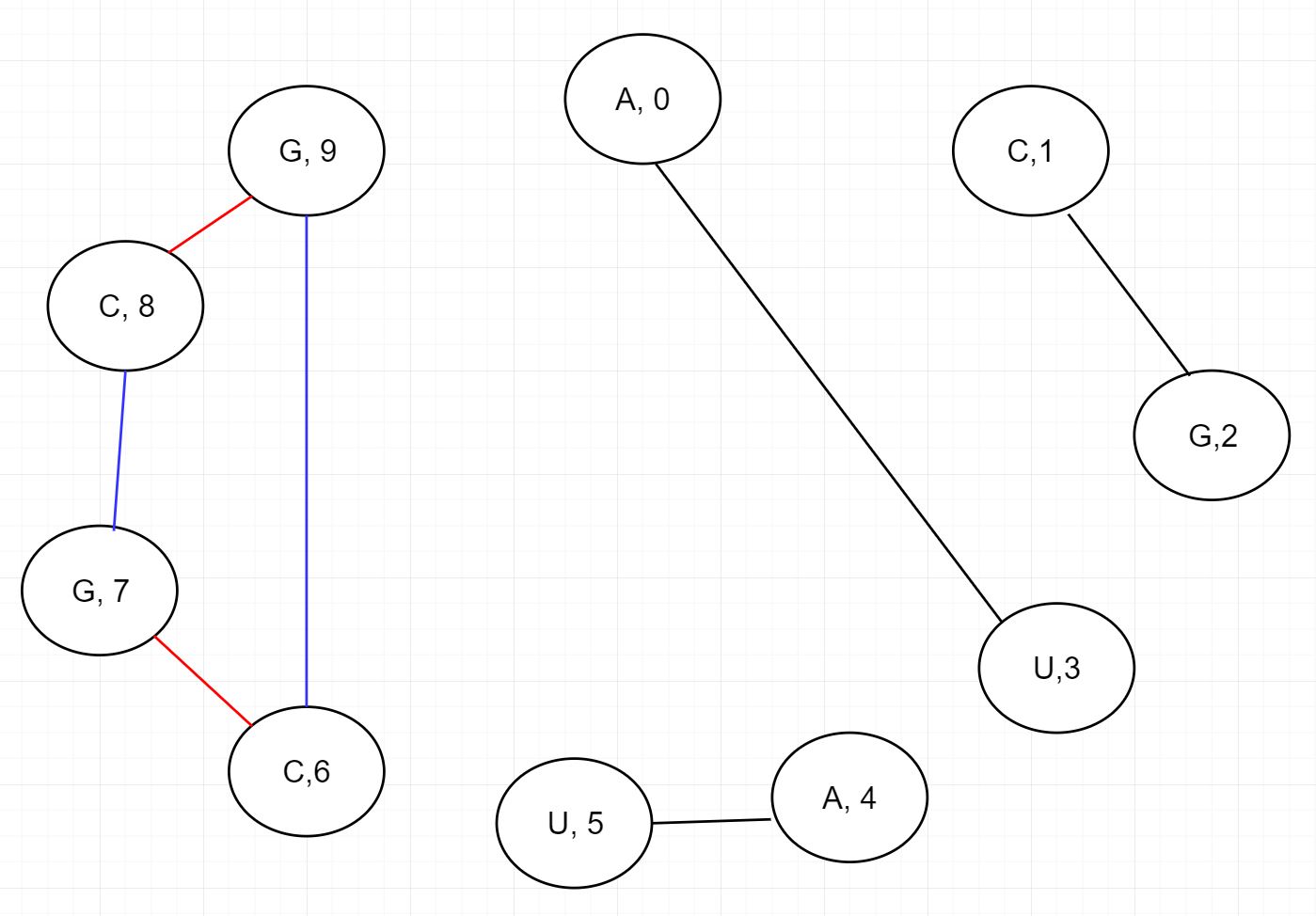
이제 다시 돌아가면 됩니다. A4 - U5 연결에서 두가지 구역으로 나뉘는데 한 구역에서는 2가지, 한 구역에서는 1가지가 나옵니다.(아무것도 없는 곳에서는 1입니다.) 그러므로 두 구역에서 나올 수 있는 경우의 수는 2 X 1 = 2 입니다. 이로써 우리는 A0 - U3의 왼쪽 구역의 경우의 수를 구할 수 있었습니다. A0 - U3의 오른쪽 구역은 1가지였음으로 다시 왼쪽 구역 경우의 X 오른쪽 구역 경우의 수를 하여 A0 - U3에서 나올 수 있는 Catalan numbers는 2가지 입니다.
위와 마찬가지로 A0 - U5의 연결도 마찬가지 방식으로 catalan numbers를 구할 수 있습니다. 하지만 실제로 이를 구현하여 코드를 돌려보면 한없이 돌아가는 session을 볼수 있습니다. 이를 해결하기 위해 이전에 방문했던 염기서열에 대해서 기억을 해둘 필요가 있습니다.
예를들어 A0-U3 연결에서 CGCG 염기서열을 방문하였고, 이때 결과는 2였습니다. 이 정보를 저장해 놓았다가 A0 - U5 연결에서 또다시 CGCG를 방문하려고 할때, CG까지 내려가지 않고 CGCG가 2였다는 것을 기억하고 있으면 바로 결과를 얻을 수 있습니다. 이전 결과를 기억해 둠으로써 프로그램의 러닝타임을 획기적으로 줄일 수 있습니다.
전체 코드는 github에 있습니다.
