
Highest Revenue Movies
WITH 'Tom Hanks' AS theActor
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
WHERE p.name = theActor
AND m.revenue IS NOT NULL
// Use WITH here to limit the movie node to 1 and order it by revenue
RETURN m.revenue AS revenue, m.title AS title
위의 퀄리를 해석하면 Tom Hanks를 theActor라는 변수로 스코핑 하고, match 를 수행 한뒤에 revenue와 title을 반환하는 쿼리이다. 여기서 WITH으로 변수를 스코핑 해서 다음 쿼리 statement로 넘겼다는 것이 가장 키 포인트이다.
정답은 Toy Story 3로 맨 마지막에 ORDER BY m.revenu DESC를 추가해 주면 맨 첫번째에서 찾을 수 있다.
Top Movies
MATCH (n:Movie)
WHERE n.imdbRating IS NOT NULL and n.poster IS NOT NULL
// Add WITH clause to return custom data for each movie
ORDER BY n.imdbRating DESC LIMIT 4
RETURN collect(n)
반환되는 movie의 map projection을 수행하는 쿼리를 위에 주어진 쿼리를 수정하여 완성하라는 문제이다. 약간 햇갈리는 문제기는 하지만 아래의 쿼리를 수행하면
MATCH (g)<-[:IN_GENRE]-(n:Movie)<-[:ACTED_IN]-(a)
WHERE n.imdbRating IS NOT NULL and n.poster IS NOT NULL
WITH n {
title: n.title,
imdbRating: n.imdbRating,
actors: collect(DISTINCT a.name),
genres: collect(DISTINCT g.name)
}
ORDER BY n.imdbRating DESC LIMIT 4
WITH collect(n.actors) as nList
WITH reduce(actorNames=[], nItem in nList | actorNames + nItem) as actorName
UNWIND actorName as AN
WITH AN, count(*) as occ where occ > 1
return AN, occ # Al Pacino, 2먼저 첫번째 WITH 구문으로 map projection을 수행하여 actors의 list를 얻는다. 그런다음 actors list를 하나로 합친 다음(reduce 구문) UNWIND로 actor list를 node로 만들고, count(*)를 수행하면 node별 개수를 구할 수가 있다. 즉, 중복된 actor를 골라 낼 수 있고 그 결과는 Al Pacino를 얻을 수 있게 된다.
Using WITH for map projection to limit results
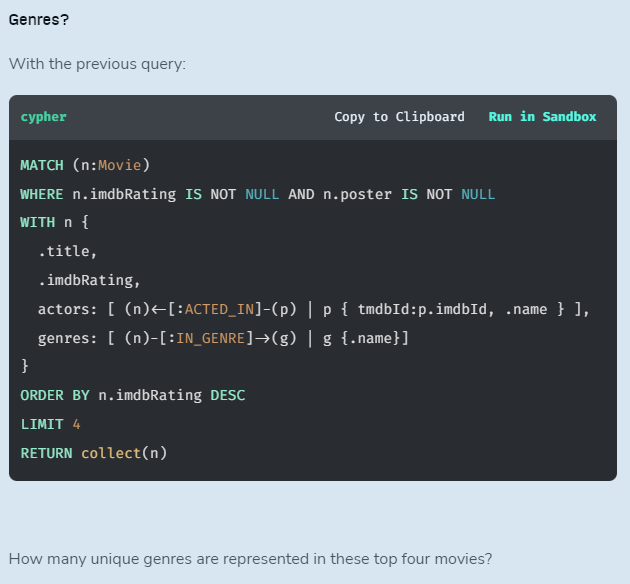
MATCH (n:Movie)
WHERE n.imdbRating IS NOT NULL AND n.poster IS NOT NULL
WITH n {
.title,
.imdbRating,
actors: [ (n)<-[:ACTED_IN]-(p) | p { tmdbId:p.imdbId, .name } ],
genres: [ (n)-[:IN_GENRE]->(g) | g {.name}]
}
ORDER BY n.imdbRating DESC
LIMIT 4
WITH collect(n.genres) as genres
WITH reduce(initgenre=[], g in genres | initgenre + g) as genres
UNWIND genres as gen
return distinct gen.name4개의 영화로부터 Unique 한 장르만을 가져와야 하는 문제이다. genres가 list로 되어 있어, collect를 수행학데되면 2차원 list가 되는 문제가 있다. 이를 해결하기 위해 reduce로 flat하게 핀 다음에 unwind로 instance화 한다. 그러면 distinct를 쓸 수 있기 때문에 return distinct 로 unique한 장르만을 가져올 수 있다. 그 결과는 4개의 데이터가 나온다.
Highest Rated Tom Hanks Movie
Write and execute a query to determine the highest average rating by a user for a Tom Hanks Movie. Use avg(r.rating) to aggregate the rating values for all movies that Tom Hanks acted in, where you use the pattern (m:Movie)←[r:RATED]-(:User).

Tom Hanks가 출연한 영화중에 user로부터 받은 rating의 평균이 가장 높은 영화를 출력하라는 문제이다.
match (a:Actor{name: "Tom Hanks"})-[:ACTED_IN]-(m), (m)<-[rel:RATED]-(u:User)
where rel.rating is not null
with m, avg(rel.rating) as averageRating
return m.title, averageRating
order by averageRating DESC
limit 1WITH clause로 movie와, rating을 avg 함수로 aggregation해서 넘긴다.
Using UNWIND pass on intermediate results
MATCH (m:Movie)
UNWIND m.languages AS lang
WITH m, trim(lang) AS language
// this automatically, makes the language distinct because it's a grouping key
WITH language, collect(m.title) AS movies
RETURN language, movies[0..10]
위의 쿼리를 수정해서 각 나라에서 개봉된 영화의 숫자를 반환하라는 문제이다.
movie properties에 country가 있음으로 languages 를 country로 바꾸고 나머지도 country로 바꿔주면 해결된다.
MATCH (m:Movie)
UNWIND m.countries AS country
WITH m, trim(country) AS country
WITH country, collect(m.title) AS movies
with country, size(movies) as numMovies where country = 'UK'
return country, numMovies