🙏내용에 대한 피드백은 언제나 환영입니다!!🙏
개발 환경 : jdk17, Spring Boot, jjwt 0.12.3
🚨 트러블 내용
JWT를 사용하여 Access Token으로 권한을 인증하는 과정에서 문제가 생겼다.
PostMan을 통해 테스트를 진행할다면, 헤더에 Access Token을 넣고 인증이 필요한 Restful API에 접근하는 것이 일반적이다.
하지만, 여기서 문제가 발생했다. 토큰의 맨 끝에. 즉, '서명' 부분에 특수문자가 들어가도 정상적으로 작동하는 것이었다.
예를 들어, 원래 토큰이 aaaa.bbbb.cccc였다면, aaaa.bbbb.cccc!@이러한 특수문자가 들어가도 정상적인 토큰으로 인지하고 권한은 인증되었다.
(jwt 토큰에 사용되는 '.', '-', '_'를 제외한 다른 특수문자들에 관한 내용이다.)
API 플랫폼 PostMan에서만의 문제인지 확인하기 위해 네트워크에 입력하여 넣어보니 같은 결과가 나왔다.
간단한 동작 사진이다.
1. 정상적인 토큰에 대한 흐름
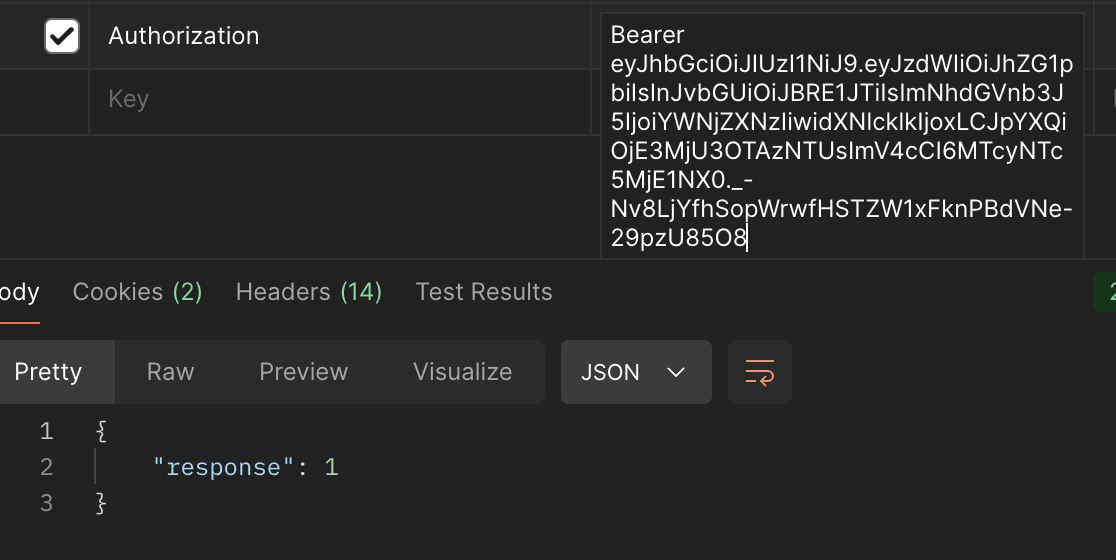
2. accessToken 뒤에 특수문자를 넣는 경우. (정상적으로 작동)
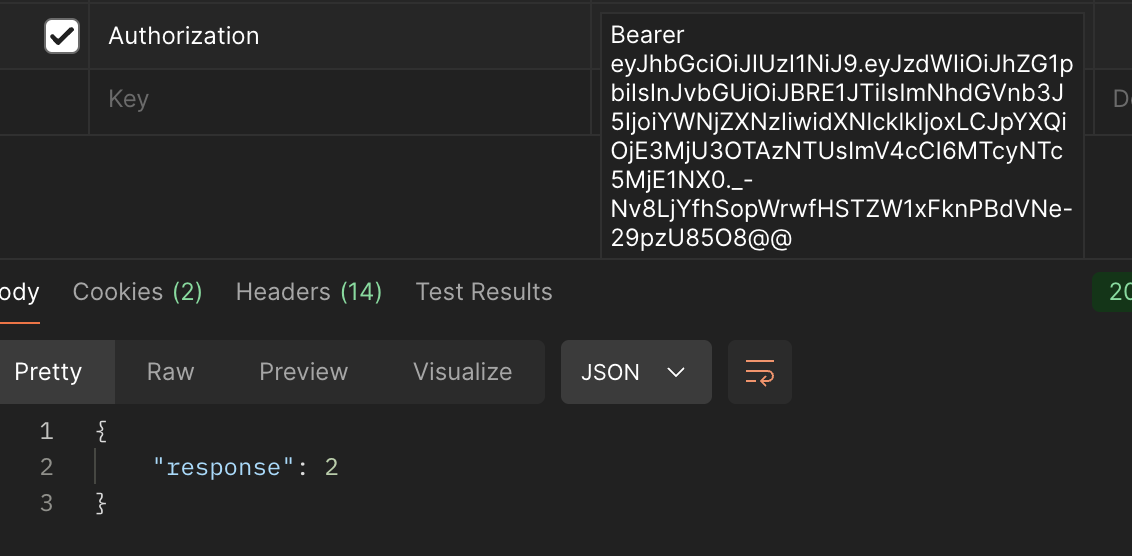
2번에 대한 accessToken의 로그
INFO 2994 --- [nio-8080-exec-5] c.p.t.j.filter.JwtAuthenticationFilter : accessToken: eyJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJhZG1pbiIsInJvbGUiOiJBRE1JTiIsImNhdGVnb3J5IjoiYWNjZXNzIiwidXNlcklkIjoxLCJpYXQiOjE3MjU3OTAzNTUsImV4cCI6MTcyNTc5MjE1NX0._-Nv8LjYfhSopWrwfHSTZW1xFknPBdVNe-29pzU85O8@@❓ 왜 그런 것일까?
구글링, 공식 문서 등 다양한 내용을 찾아보았지만, 찾지 못했다. 그래서 초기에는 아래와 같은 생각을 가졌다.
❓ 토큰 디코딩 관대함. (나의 생각)
JWT은 보통 영문자, 숫자, '_', '-', '.' 등의 내용으로 이루어진다. 그래서, 디코딩 하는 과정에서 맨 뒤에 붙은 !@#이러한 특수문자는 제외시키는 일이 일어난다는 생각을 하였다. (물론, 맨 뒤를 제외하고 사이사이에 특수문자가 들어가면 잘못된 토큰임을 인지한다.)
❓ 서명 검증에서의 통과. (나의 생각)
JWT는 헤더, 페이로드, 서명으로 이루어 지고, 서명은 헤더와 페이로드 + secretKey를 통해서 만들어진다.
그래서, 서버는 수신된 헤더와 페이로드, secretKey를 사용하여 서명을 조합해 서명이 올바른지 확인하며 '무결성'을 확인한다.
이러한 과정에서 서명이 올바르다면 뒤에 특수문자와 상관없이 그대로 인증을 통과시킨다고 생각을 하였다. (1번과 이유가 비슷한가..?)
이후에 행한 방법은 2가지였다.
- 코드 분석
- GitHub 오픈 소스 설명 및 이슈 탐색
1. 코드분석
디버깅을 통해서 코드를 타고 들어가면 Base64클래스를 볼 수 있다.
디코딩 과정에서 필요한 내용을 보자면 아래와 같다.
final class Base64 {
private static final char[] BASE64_ALPHABET = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/".toCharArray();
private static final char[] BASE64URL_ALPHABET = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_".toCharArray();
private static final int[] BASE64_IALPHABET = new int[256];
private static final int[] BASE64URL_IALPHABET = new int[256];
.
.
.
private final char[] ALPHABET;
private final int[] IALPHABET;
private Base64(boolean urlsafe) {
this.urlsafe = urlsafe;
this.ALPHABET = urlsafe ? BASE64URL_ALPHABET : BASE64_ALPHABET;
this.IALPHABET = urlsafe ? BASE64URL_IALPHABET : BASE64_IALPHABET;
}
byte[] decodeFast(CharSequence seq) throws DecodingException {
.
.
.
} else {
int sIx = 0;
int eIx;
for(eIx = sLen - 1; sIx < eIx && this.IALPHABET[seq.charAt(sIx)] < 0; ++sIx) {
}
while(eIx > 0 && this.IALPHABET[seq.charAt(eIx)] < 0) {
--eIx;
}
int pad = seq.charAt(eIx) == '=' ? (seq.charAt(eIx - 1) == '=' ? 2 : 1) : 0;
int cCnt = eIx - sIx + 1;
int sepCnt = sLen > 76 ? (seq.charAt(76) == '\r' ? cCnt / 78 : 0) << 1 : 0;
int len = ((cCnt - sepCnt) * 6 >> 3) - pad;
byte[] dArr = new byte[len];
int d = 0;
int i = 0;
int r = len / 3 * 3;
.
.
.
}
}
static {
IALPHABET_MAX_INDEX = BASE64_IALPHABET.length - 1;
Arrays.fill(BASE64_IALPHABET, -1);
System.arraycopy(BASE64_IALPHABET, 0, BASE64URL_IALPHABET, 0, BASE64_IALPHABET.length);
int i = 0;
for(int iS = BASE64_ALPHABET.length; i < iS; BASE64URL_IALPHABET[BASE64URL_ALPHABET[i]] = i++) {
BASE64_IALPHABET[BASE64_ALPHABET[i]] = i;
}
.
.
.
}
}주석에 적으면 불편하니 위의 코드 중에서도 의미하는 것을 하나씩 보겠다.
a. 클래스 변수
private static final char[] BASE64_ALPHABET = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/".toCharArray();
private static final char[] BASE64URL_ALPHABET = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_".toCharArray();
private static final int[] BASE64_IALPHABET = new int[256];
private static final int[] BASE64URL_IALPHABET = new int[256]; 위에서 BASE64_ALPHABET과 BASE64URL_ALPHABET는 각각 Base64, Base64URL에 사용되는 내용들이다.
그리고, BASE64_IALPHABET과 BASE64URL_IALPHABET는 아스키 코드 0 ~ 255를 표현할 공간이라고 보면 된다.
이것과 함께 볼 내용은 static 초기화 블록이다.
b. static 초기화 블록
static {
IALPHABET_MAX_INDEX = BASE64_IALPHABET.length - 1;
Arrays.fill(BASE64_IALPHABET, -1);
System.arraycopy(BASE64_IALPHABET, 0, BASE64URL_IALPHABET, 0, BASE64_IALPHABET.length);
int i = 0;
for(int iS = BASE64_ALPHABET.length; i < iS; BASE64URL_IALPHABET[BASE64URL_ALPHABET[i]] = i++) {
BASE64_IALPHABET[BASE64_ALPHABET[i]] = i;
}
.
.
.
} 우선 Arrays.fill()과 System.arraycopy()를 통해서 255크기의 배열인 BASE64_IALPHABET과 BASE64URL_IALPHABET을 -1로 초기화 한다.
그 이후에, for문을 통해서 클래스 변수에서 정의해둔 BASE64_ALPHABET의 크기에 맞게 Base64, Base64URL에 실제로 사용되는 64개의 값들만 초기화를 진행한다. 즉, 해당 값들은 -1이 아닌 그에 맞는 값으로 초기화 되는 것이다.
이제 볼 것은 decodeFast 메서드 이다.
c. decodeFast(CharSequence seq)
byte[] decodeFast(CharSequence seq) throws DecodingException {
int sLen = seq != null ? seq.length() : 0;
.
.
.
} else {
int sIx = 0;
int eIx;
for(eIx = sLen - 1; sIx < eIx && this.IALPHABET[seq.charAt(sIx)] < 0; ++sIx) {
}
while(eIx > 0 && this.IALPHABET[seq.charAt(eIx)] < 0) {
--eIx;
}
int pad = seq.charAt(eIx) == '=' ? (seq.charAt(eIx - 1) == '=' ? 2 : 1) : 0;
int cCnt = eIx - sIx + 1;
int sepCnt = sLen > 76 ? (seq.charAt(76) == '\r' ? cCnt / 78 : 0) << 1 : 0;
int len = ((cCnt - sepCnt) * 6 >> 3) - pad;
byte[] dArr = new byte[len];
int d = 0;
int i = 0;
int r = len / 3 * 3;
.
.
.
}
}위에서도 이 글에서 가장 중요한 부분은 아래의 부분이다
for (eIx = sLen - 1; sIx < eIx && this.IALPHABET[seq.charAt(sIx)] < 0; ++sIx) {}
while (eIx > 0 && this.IALPHABET[seq.charAt(eIx)] < 0) {
--eIx;
}위 코드는 입력 문자열에서 디코딩 대상이 아닌 문자들, 즉 Base64에 해당하지 않는 문자(예: 공백, 개행, @, #, ! 같은 특수문자 등)를 앞뒤에서 제거하는 역할을 한다.
이때 사용되는 IALPHABET 배열은 아스키 코드값을 인덱스로 하여 해당 문자가 Base64 알파벳인지 여부를 -1 또는 0~63으로 나타낸다. 따라서 IALPHABET < 0인 경우는 Base64에서 유효하지 않은 문자로 간주되어 디코딩 대상에서 자동으로 무시된다.
이 부분에서 확인할 수 있는건, 디코딩 과정에서 양 끝의 특수문자를 지우고 byte배열로 바꾸기 때문에 정상적으로 디코딩이 된다.
이렇게 되면, 헤더, 페이로드에서도 특수문자가 허용되는 것이 아닌가?
그것을 보기 위해서는DefaultJwtParser 클래스에서의 verifySignature 메서드를 봐야한다.
d. DefaultJwtParser.verifySignature
우선, 서명의 경우 인코딩된 헤더 + 인코딩된 페이로드 + 시크릿키의 조합으로 만들어진다. 그러면, 서명을 검증하기 위해서는 똑같이 인코딩된 헤더 + 인코딩된 페이로드가 필요하다.
과정의 코드를 보자면,
private void verifySignature(TokenizedJwt tokenized, JwsHeader jwsHeader, String alg, SigningKeyResolver resolver, Claims claims, Payload payload) {
.
.
.
} else {
byte[] signature = this.decode(tokenized.getDigest(), "JWS signature");
InputStream payloadStream = null;
Object verificationInput;
if (jwsHeader.isPayloadEncoded()) {
int len = tokenized.getProtected().length() + 1 + tokenized.getPayload().length();
CharBuffer cb = CharBuffer.allocate(len);
cb.put(Strings.wrap(tokenized.getProtected()));
cb.put('.');
cb.put(Strings.wrap(tokenized.getPayload()));
cb.rewind();
ByteBuffer bb = StandardCharsets.US_ASCII.encode(cb);
bb.rewind();
byte[] data = new byte[bb.remaining()];
bb.get(data);
verificationInput = Streams.of(data);
}
.
.
.
try {
String msg;
try {
VerifySecureDigestRequest<Key> request = new DefaultVerifySecureDigestRequest((InputStream)verificationInput, provider, (SecureRandom)null, key, signature);
if (!algorithm.verify(request)) {
msg = "JWT signature does not match locally computed signature. JWT validity cannot be asserted and should not be trusted.";
throw new SignatureException(msg);
}
}
.
.
.
이 곳에서 cb.put(Strings.wrap(tokenized.getProtected()));와 cb.put(Strings.wrap(tokenized.getPayload())); 부분이 바로 인코딩된 헤더, 페이로드이다.
이것은, 위 a, b, c에서 보았던 디코딩 과정과는 상관이 없고, 인코딩된 헤더와 페이로드를 사용하기 때문에 특수문자가 있으면 문제가 발생한다.
그리고, 그 아래에
VerifySecureDigestRequest<Key> request = new DefaultVerifySecureDigestRequest((InputStream)verificationInput, provider, (SecureRandom)null, key, signature);
if (!algorithm.verify(request)) {코드에서 만들어진 verificationInput을 사용하고, if (!algorithm.verify(request))을 통해서 서명 확인 과정 중, 잘못된 값이 발생하면 SignatureException가 발생하여 잘못된 서명 오류가 발생하는 것이다.
단, 위 로직에서 볼 수 있듯이 서명은 디코딩된 값을 그대로 사용한다. (이것은 아래 2. GitHub 오픈 소스 설명 및 이슈 탐색에서 말하는 강건성의 원칙이다.)
결국에는
1. byte배열로 디코딩 중, 특수문자가 양 끝에 있더라도 에러가 발생하지 않는다.
2. 헤더와 페이로드 또한, 디코딩 과정에서는 양 끝에 특수문자가 있어도 에러가 발생하지 않는다. 하지만, 서명 검증 과정에서 디코딩된 헤더, 페이로드가 아닌 인코딩된 헤더, 페이로드를 사용하기 때문에 특수문자로 인해 에러가 발생한다.
2. GitHub 오픈 소스 설명 및 이슈 탐색
아래와 같은 GitHub 내용이 있다.
jjwt GitHub 중 Adding Invalid Characters 부분
간단히 요약하자면, 아래와 같다.
<< jjwt GitHub 중 Adding Invalid Characters의 내용 >>
- Base64 또는 Base64URL 디코더가 기본적으로 잘못된 Base64 문자를 무시하는 이유를 설명이다.
why? 실제 서명 자체를 변경하지 않기 때문. - 서명은 항상 바이트 배열로 처리되며, 텍스트로 인코딩된 바이트 배열을 변경해도 실제 서명 데이터는 변경되지 않는다.
=> JJWT는 암호화 작업에서 바이트 배열이 중요하다고 보고, 텍스트 인코딩은 덜 중요하게 취급. 하지만, 실제 바이트 배열이 변경되면 JJWT 암호검사는 실패. - 서명의 존재 이유는 두 가지를 보장하기 위해서이다.
3.1 서명이 우리가 아는 누군가에 의해 생성되었는지(진위 확인).
3.2 생성된 이후에 아무도 서명을 변경하거나 조작하지 않았는지(무결성 유지).
=> 단순히 잘못된 문자를 추가한다고 해서 알고리즘을 속이는 것이 아니며, 바이트 배열의 무결성이나 진위를 변경하지 않기 때문에 문제가 되지 않는다는 뜻.
<< 특수문자 허용에 대한 의문점 제기 이슈 내용 >>
- 초기 설계에서 이러한 동작은 "강건성 원칙"에 따라 의도적으로 결정
- 서명을 검증할 때 잘못된 문자가 있어도 서명의 무결성에 영향을 주지 않기 때문에 실패할 필요가 없다고 설명.
- JJWT의 서명 검증은 기본적으로 암호화된 서명을 기준으로 하며, 단순히 텍스트 레벨에서 발생하는 문제는 보안에 실질적인 영향을 미치지 않는다고 생각.
- 하지만 이 문제는 추후 JJWT의 주요 업데이트에서 수정할 가능성이 있으며, 현재로서는 커스텀 Base64 디코더를 사용하는 것이 가장 쉬운 해결책이라고 제안. (오래전부터 사용해왔고, 기존 동작 방식에 의존하는 서비스가 많을 것이기에 업데이트하기에는 중요한 논점이다.)
강건성의 원칙이란, "너그러이 수용하고, 엄격하게 보낸다."는 뜻.
이 원칙의 목표는 시스템의 견고함을 높이고, 다양한 입력을 잘 처리하면서도 정확하고 신뢰성 있는 출력을 유지하는 것이다.
내가 생각했던 이유가 정확하진 않지만, 너그럽게 수용한다는 점에서 같은 의미인 것 같다. 나는, 사용자가 로그아웃을 한다면, 그 사용자의 AccessToken으로의 접근은 허용하지 않도록 BlackList 메모리에 담아 놓을 것이기 때문에, 아래와 같은 해결방법을 적용해보았다.
👉 해결방법
- 간단한 해결 방법이다. 그냥 검증을 해주는 과정이다. (나의 방법)
JWT를 통하여 인증을 처리하는 필터에서 특수문자를 처리해주는 코드를 넣었다.
간단히 보자면 아래와 같다. 시작과 끝 사이에 영문자, 하이픈(-), 언더바(_), 점(.)으로 이루어져야 한다.
public boolean isBase64URL(String token) {
return token.matches("^[0-9A-Za-z-_.]+$");
}
String accessToken = accessTokenGetHeader.substring(TOKEN_PREFIX.length()).trim();
if (!isBase64URL(accessToken)) {
// 예외 처리.
}하지만, 이거는 JWT 구조적으로 해결하는 방식이 아니다.
- Base64를 커스텀하는 것이다.
- base64url 인코더 구현
public class CustomBase64UrlEncoder implements Encoder<OutputStream, OutputStream> {
@Override
public OutputStream encode(OutputStream outputStream) {
// OutputStream을 Base64 URL-safe로 인코딩
Base64.Encoder encoder = Base64.getUrlEncoder().withoutPadding();
return encoder.wrap(outputStream); // Base64로 인코딩한 결과를 OutputStream으로 반환
}
}- base64url 디코더 구현
public class CustomBase64UrlDecoder implements Decoder<InputStream, InputStream> {
@Override
public InputStream decode(InputStream inputStream) {
try {
byte[] bytes = inputStream.readAllBytes(); // InputStream을 바이트 배열로 변환
byte[] decodedBytes = Base64.getUrlDecoder().decode(bytes); // Base64 URL-safe 디코딩
return new ByteArrayInputStream(decodedBytes); // 디코딩된 결과를 새로운 InputStream으로 반환
} catch (Exception e) {
throw new RuntimeException("Decoding failed", e);
}
}
}- 커스텀 인코더 설정
private final Encoder<OutputStream, OutputStream> base64UrlEncoder = new CustomBase64UrlEncoder();
/* 토큰 생성 */
private String createJwt(Map<String, Object> claims, String subject, Long expirationTime) {
return Jwts.builder()
.subject(subject)
.claims(claims)
.b64Url(base64UrlEncoder) // 커스텀 인코더 설정
.issuer(issuer)
.issuedAt(new Date(System.currentTimeMillis()))
.expiration(new Date(System.currentTimeMillis() + expirationTime))
.signWith(secretKey)
.compact();
}- 커스텀 디코더 설정
private final Decoder<InputStream, InputStream> base64UrlDecoder = new CustomBase64UrlDecoder();
/* 토큰 정보 불러오기 */
private Claims parseClaims(String token){
return Jwts.parser()
.verifyWith(secretKey)
.b64Url(base64UrlDecoder) // 커스텀 디코더 설정
.build()
.parseSignedClaims(token)
.getPayload();
}💡느낀점
내가 잘못된 코드를 짠 것인지 알 수 없었다. 하지만, 깃허브를 통해 다양한 사람들이 짠 코드를 보았고, 그 코드들을 적용시켜도 똑같은 결과가 나와 특수문자 처리에 대한 의심을 해보게 된 것이다.
또한, 특수문자 처리가 중요한가? 라는 생각을 가질 수 있다.
나는 개인의 정보가 사용되는 로그인 부분은 보안이 아주 중요하다고 생각한다. 그래서, 로그아웃을 하면 Access Token을 만료기간 까지 BlackList에 담아 사용하지 못하게 만드는 과정을 만들었다. 이러한 기능을 넣으면, 위처럼 특수문자를 사용할 시 그대로 접근이 되는 문제가 발생한다.
왜 이렇게 처리를 했는지, 이것을 해결하기 위해서는 어떻게 접근하여 해결해야하는지를 항상 생각을 하며 개발을 해야겠다고 다시 느꼈다.
