
2-1 Read CSV
문제: 방금 다운받은 데이터를 Data Frame으로 읽는 코드를 작성해주세요.
<내 코드>
df1 = pd.read_csv("penguins_size.csv") #파일 불러오기
df1<실행 결과>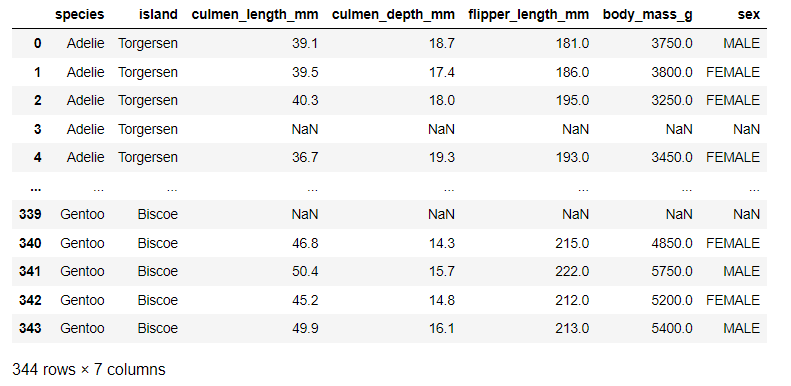 엑셀 파일을 다운받아 불러오기에 성공했다.
엑셀 파일을 다운받아 불러오기에 성공했다.
2-2 Data Frame Indexing 복습!
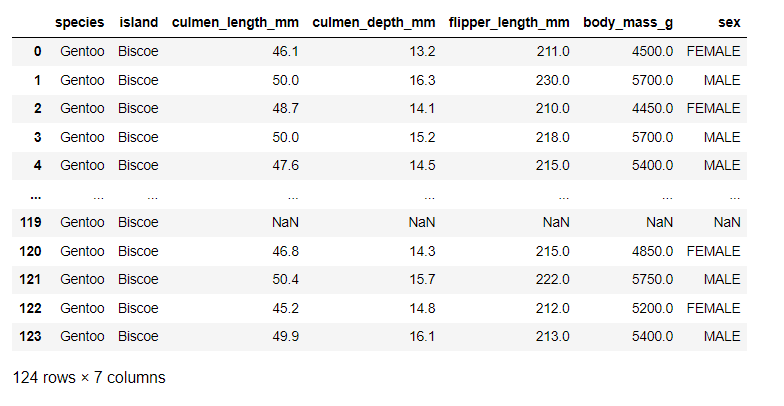
문제: 읽어온 Data Frame에서, species가 Gentoo인 데이터만 조회하고, index를 새로 재배치 하는 코드를 작성해주세요.
<내 코드>
df1=df1[df1["species"]=="Gentoo"] #species가 Gentoo인 데이터만 조회
df1=df1.reset_index(drop=True) #index 초기화
df1<실행 결과>
2-3 Groupby
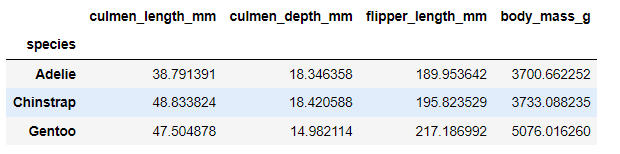
문제: 2-1에서 읽어온 Data Frame에서, species별 평균값 데이터를 조회해보세요.
species별 평균값의 조회가 끝났다면, island별 평균, 최대, 최소, 중앙값 데이터도 조회해보세요!
<내 코드>
df1.groupby('species').mean() #species를 그룹으로 묶고 평균값 계산df1.groupby('island').agg(['mean','max','min','median']) #island를 그룹으로 묶고, 평균, 최대, 최소, 중앙값 계산<실행 결과>

참고사이트
2-4 apply lambda
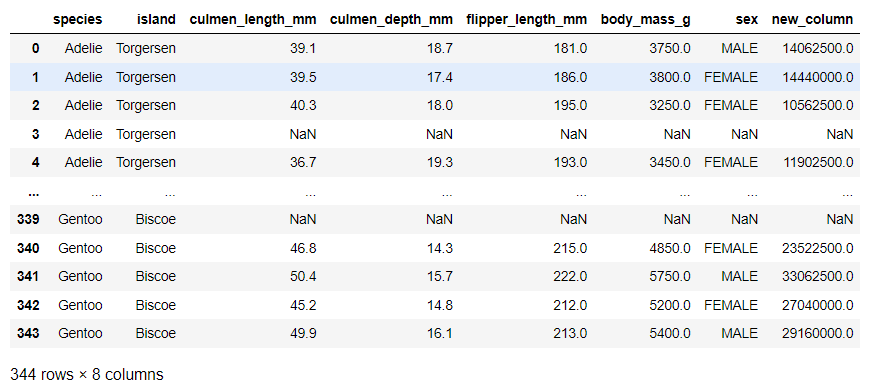
문제:들어온 input에 대해서 제곱된 값을 return 해주는 함수를 작성하세요.
그런 다음 2-1에서 읽어온 Data Frame에서, body_mass_g Column의 값을 제곱한 새로운 Column을 만들어보세요
<내 코드>
df1['new_column']=df1['body_mass_g']**2 #new_column은 body_mass_g를 제곱한 값이다.
df1<실행 결과>
 참고사이트
참고사이트
2-5 drop nan values
문제:2-1에서 읽어온 Data Frame에서 칼럼 별로 값이 없는 데이터의 수를 구하는 코드를 작성해보세요.
그리고 그런 공백값들을 제거한 Data Frame을 출력하는 코드를 작성해주세요.
<내 코드>
df1 = pd.read_csv("penguins_size.csv") #df1 초기화
df1.isnull().sum() #공백(결측값)이 있는 칸 개수 구하기df1 = pd.read_csv("penguins_size.csv")
df1.isnull().sum()
df1.dropna(axis=0) #결측값이 있는 행 삭제(axis=1은 열 삭제)
2-6 remove column
문제:2-1에서 읽어온 Data Frame에서 island Column을 제거하는 코드를 작성해주세요.
<내 코드>
df1 = pd.read_csv("penguins_size.csv")
df1.drop('island', axis=1) #'island'열 삭제<실행 결과>

도여줄게 완전히 도라진 나