
수많은 개발동아리에 지원하고자 하였지만 지원양식(구글폼)의 질문들을 보고 나의 경험과 이 분야에 대한 지식이 너무 부족하다고 생각되어 한 학기동안 공부를 해보고자 홍익대학교 컴퓨터공학과 학회 GDSC에 가입하였다.
인공지능 전문가가 내가 관심있는 직업이기에 인공지능 스터디를 신청하였다.
인공지능 스터디 과제에서 Jupiter notebook을 사용한다고 하여 설치하였다.설치참고사이트
스터디과제는 별도의 강의없이 구글링으로 충분히 해결할 수 있는 난이도의 문제들을 제시해준다.
문제를 풀어보려했으나 코드를 어디서부터 작성해야할지 몰라서 youtube에 pandas기본강의를 찾아보았다. 유튜브 기본 강의에 대한 내용은 따로 정리할 예정이다. pandas 기본 강의 유튜브
pandas는 엑셀과 상당히 유사하지만 엑셀로는 프로그램 작성이 불가하다.
또한 pandas는 numpy를 사용하고 있어 계산하는 속도가 엑셀보다 빠르다고 한다.
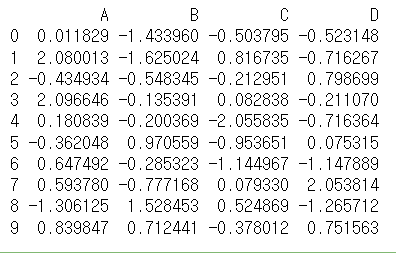
문제1 Dateframe 만들기
열(Column)의 이름이 A, B, C, D이고, 각 열마다 Random한 숫자가 10개씩 담겨져 있는 Data Frame을 생성해보세요.
<내 코드>
import pandas as pd #pandas를 pd로 사용하겠다
import numpy as np #numpy를 np로 사용하겠다
df=pd.DataFrame(np.random.randn(10,4),columns=list('ABCD')) #10x4형태로 랜덤 숫자가 나온다, 열인덱스는 ABCD로 지정
df*참고로 np.random.randint(시작범위,끝범위-1,size=(가로,세로))를 사용하면 정수값이 랜덤으로 나오는 것 같다.
<실행결과>
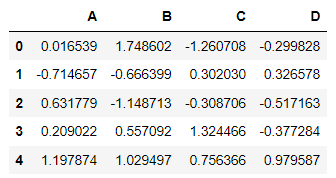
문제2 Data frame indexing 1
1-1에서 생성한 DataFrame에서 위에서부터 5개의 행을 출력하는 코드를 작성해보세요
<내 코드>
df.head(5) #df의 위에서 5번째 줄까지 출력, tail은 그 반대 <실행결과>
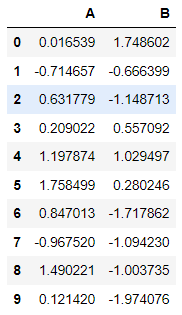
문제3 Data Frame Indexing 2
1-1에서 생성한 DataFrame에서 1번째, 2번째 열만 추출하는 코드를 작성해보세요
<내 코드>
df.loc[:,:'B'] #첫행부터 마지막행, 첫 열부터 B가 있는 열까지 출력<실행결과>
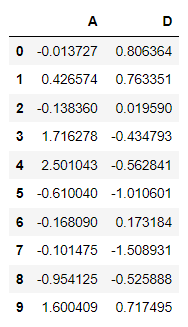
문제4 Data Frame Indexing 3
1-1에서 생성한 DataFrame에서 "A"열과 "D"열만 추출하는 코드를 작성해보세요
<내 코드>
df[['A','D']] #df['column명']->해당 열만 출력<실행결과>
이 문제도 위의 사이트를 참고하였다.
문제5 Data Frame columns, values, index
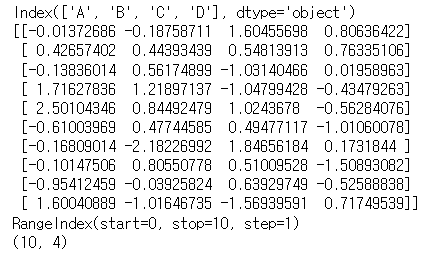
1-1에서 생성한 DataFrame의 Column들과 값들, index, shape을 출력하는 코드를 작성하세요
<내 코드>
print(df.columns)
print(df.values)
print(df.index)
print(df.shape)<실행결과>
문제6 Data Frame Informations
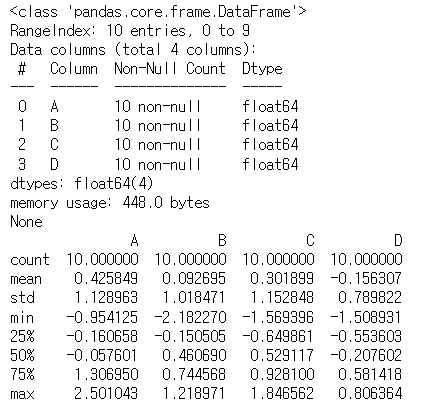
1-1에서 생성한 DataFrame의 column별 정보와 통계적 정보를 출력하는 코드를 작성하세요
<내 코드>
print(df.info())
print(df.describe())<실행결과>
문제7 Data Frame Sorting
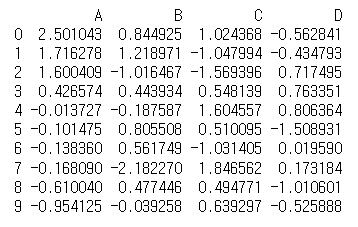
1-1에서 생성한 DataFrame을 "A" Column을 기준으로 내림차순으로 정렬한 뒤, Index를 재정렬하는 코드를 작성하세요.
(단, Index 재정렬 후 , 원래의 index는 삭제해주세요.)
<내 코드>
df=df.sort_values(by='A', ascending=False) #내림차순 정렬, ascending 안쓰면 오름차순
df=df.reset_index(drop=True) #index 초기화
print(df)<실행결과>
문제8 Data Frame Advanced Indexing 1
아래와 같은 Data Frame을 만들고, 주 언어가 파이썬인 사람들만 조회하는 코드를 작성해보세요.
<내 코드>
data={"이름":["피카츄","라이츄","파이리","꼬부기","버터풀","야도란","피죤투","또가스"],
"학과":["경제","경영","컴공","컴공","경제","전전","컴공","기계"],
"언어":["파이썬","C","C+","파이썬","자바","엄","파이썬","자바"],
"직무":["AI엔지니어","프론트","벡엔드","AI엔지니어","벡엔드","프론트","AI엔지니어","PM"]}
df=pd.DataFrame(data, columns=["이름","학과","언어","직무"])
print(df[df["언어"]=="파이썬"]) #df[]로 한 번 더 묶어주지 않으면 아래 아래와 같은 결과창이 뜬다.<실행결과>
 잘못 나오는 결과
잘못 나오는 결과
문제9 Data Frame Advanced Indexing 2
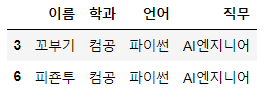
1-8에서 만든 Data Frame에서 학과가 컴공이고, 주 언어가 파이썬, 직무는 AI 엔지니어인 사람들만 조회하는 코드를 작성해보세요.
<내 코드>
df[(df["학과"]=="컴공")&(df["언어"]=="파이썬")&(df["직무"]=="AI엔지니어")]<실행결과>
문제10 Data Frame Concat
1-1에서 만든 Data Frame과 1-8에서 만든 Data Frame을 위아래로 합치는 코드와, 좌우로 합치는 코드를 작성해주세요. 각 작업을 수행한 후엔 Index를 다시 세팅해주세요!
<내 코드>
print(pd.concat([df1, df4])) #axis=0, 위아래
print(pd.concat([df1,df4],axis=1)) #좌우<실행결과>
참고사이트
문제 11 Data Frame Concat 2
1-10에서 만든 Data Frame가 뭔가 이상합니다. NaN값들이 막 섞여있고 상당히 지저분합니다. 왜 이러는 걸까요? 이유를 한번 생각해서 적어보세요!
이유를 적어본 뒤에, 1-8에서 만든 Data Frame의 이름을 "A", "B", "C", "D"로 바꾼 다음 다시 시도해보세요.
<내 코드>
위 아래로 합치는 경우 columns의 이름들을 지정해주어 해당 columns값이 지정되어있지 않으면 NaN값이 뜨는 것 같다. 좌우로 합치는 경우 두 데이터 모두 인덱스 값이 기본 설정이므로 값이 지정되어 있지 않은 아래 두줄만 NaN값이 뜬다.
