
EDA는 탐색적 데이터 분석이라고 한다. 데이터를 수집하고 정제하는 과정이다. EDA과정을 거치면서 데이터의 잠재적 문제와 패턴을 발견할 수 있으며, 추가 자료수집을 위한 데이터기반을 형성할 수 있다.
1. EDA의 기본
문제1 데이터 읽어오기
데이터 <- 이곳에서 데이터를 다운 받아 읽어왔다.
여러개의 csv파일을 1개의 dataFrame으로 만들어야하는데 자꾸 에러가 떠서 1개의 csv파일로만 우선 진행하였다.
import pandas as pd
from glob import glob
import warnings
warnings.filterwarnings('ignore') # 경고 메세지를 출력 안 하는 코드입니다.
base_dir = "C:/Users/park/Desktop/GDSC/AI_STUDY/03_EDA/data/" #파일이 있는 폴더
file_lst = glob(base_dir + "*.csv") #*는 모든 csv가 붙은 파일들을 말함, glob는 csv파일을 리스트로 만들어줌
df = pd.read_csv("C:/Users/park/Desktop/GDSC/AI_STUDY/03_EDA/data/소상공인시장진흥공단_상가(상권)정보_인천_202212.csv", encoding='cp949') #본래는 for문으로 concat을 해주어야 했는데 에러떠서 인천파일만 쓰도록하겠음.
df
문제2 카페만 조회하기
1-1에서 만든 Data Frame에서 상권업종중분류명이 커피점/카페인 데이터들만 조회하는 코드를 작성해주세요.
concat_df = df.loc[df['상권업종중분류명']=='커피점/카페']
concat_df = concat_df.reset_index(drop=True)
concat_df
문제3 특정한 카페만 조회하기
1-2에서 만든 Data Frame에서 우리는 전국 카페의 정보를 얻어냈습니다. 이제 이중에서 마포구에 위치한 스타벅스의 데이터만 조회하는 코드를 작성해주세요.
concat_df = concat_df[concat_df['도로명주소'].str.contains('마포구')&concat_df['상호명'].str.startswith('스타벅스')] #서울.csv로 변경함
concat_df = concat_df.reset_index(drop=True)
concat_df
문제4 프렌차이즈 카페 조회해보기
마포구에 있는 스타벅스의 데이터를 모두 조회해봤습니다. 이제 스타벅스 뿐만 아니라, 투썸, 이디야, 할리스, 메가커피, 커피빈에 대한 정보도 한번 가져와봅시다! 위에서 명시된 프렌차이즈 카페(스타벅스 포함)들의 마포구 내의 점포 수와, 입점 비율 정보가 담겨있는 Data Frame을 생성하는 코드를 작성해주세요.
어려워서 답지의 도움을 받았다.
import pandas as pd
from glob import glob
import warnings
warnings.filterwarnings('ignore') # 경고 메세지를 출력 안 하는 코드입니다.
df = pd.read_csv("C:/Users/park/Desktop/GDSC/AI_STUDY/03_EDA/data/소상공인시장진흥공단_상가(상권)정보_서울_202212.csv", encoding='cp949') #본래는 for문으로 concat을 해주어야 했는데 에러떠서 서울파일만 쓰도록하겠음.
mapo_cafes = df[(df['시군구명'] == "마포구") & (df['상권업종중분류명'] == "커피점/카페")].reset_index(drop=True)
tot_cafes = len(mapo_cafes)
cafe_lst = ['스타벅스', "투썸플레이스", "이디야", "할리스", "메가커피", "커피빈"]
nums = []
ratio = []
for cafe in cafe_lst:
tmp_cafe_df = mapo_cafes[mapo_cafes["상호명"].str.contains(cafe)]
nums.append(len(tmp_cafe_df))
ratio.append(f"{(len(tmp_cafe_df) / tot_cafes)*100:.2f}%")
mapo_cafe_info = pd.DataFrame({"프렌차이즈" : cafe_lst,
"점포수" : nums,
"입점 비율" : ratio})
mapo_cafe_info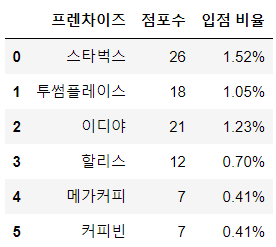
2. 마케팅 데이터 EDA 해보기
문제1 데이터 읽어오기
데이터 링크에서 Train.csv만 다운 받아 데이터를 불러왔다.
import pandas as pd
df= pd.read_csv("C:/Users/park/Downloads/Train.csv") #까먹어서 1주차 보고옴
df
문제2 결측치 확인하기
불러온 데이터의 Column 별 결측치(Missing Value) 정보를 출력하는 코드와 missingno를 활용하여 결측치를 시각화해보세요.
!pip install missingno #missingno 설치
import pandas as pd
import missingno as msno
print(df.isnull().sum()) #결측값 합 출력
msno.matrix(df) #matrix로 결측치 시각화 msno.bar(df)로 코드 실행 시
msno.bar(df)로 코드 실행 시
 msno참고사이트
msno참고사이트
결측값 참고 사이트
문제3 Distribution Check
2-1에서 불러온 Data Frame의 Column별 분포를 확인할 수 있는 코드를 작성해주세요. (단 한눈에 전체 column의 분포를 확인할 수 있게 시각화)
원래는 plt1,plt2,plt3....해서 for문을 돌릴까 했는데 도저히 답이 안나와서 답지를 가져왔다. 아직 제대로 분석을 하지 못한 코드이기에 추가적으로 학습을 한 뒤 추가 자료를 업데이트 하겠다.
import matplotlib.pyplot as plt
import seaborn as sns
df['Family_Size'] = df['Family_Size'].astype('object')
df['Work_Experience'] = df['Work_Experience'].astype('object')
columns = df.columns ## There are 11 columns
fig, axes = plt.subplots(3,4, figsize=(20,15))
axes = axes.ravel()
for idx, i in enumerate(columns) :
## dtype 별로 나눠서 category 면 Count plot , 연속형이면 distplot
if df[i].dtype == 'int64' :
sns.distplot(df[i], ax = axes[idx])
elif df[i].dtype == 'O' :
sns.countplot(df[i], ax = axes[idx])
axes[idx].set_xticklabels(axes[idx].get_xticklabels(),rotation = 30)
axes[-2].remove()
axes[-1].remove()
plt.subplots_adjust(left=0.1, bottom=0.1, right=0.9, top=0.9, wspace=0.3, hspace=0.4)
plt.show()