
EDA단계?의 정석? 어떤 한 분의 캐글의 필사를 진행하는 주차이다.
Ashwini Swain의 EDA
*데이터는 Titanic을 사용함
1. 관련 라이브러리 import하기
import numpy as np #과학 계산을 위한 라이브러리, 다차원 배열을 처리하는 데 필요한 유용한 기능 제공
import pandas as pd #데이터분석 라이브러리
import matplotlib.pyplot as plt #여러 그래프를 그려주는 함수가 있는 라이브러리
import seaborn as sns #matplotlib과 같은 데이터시각화 라이브러리
plt.style.use('fivethirtyeight') #matplotlib묘듈이며, 미리만들어 놓은 그래프 스타일 사용이 가능함
import warnings
warnings.filterwarnings('ignore') #경고메세지 무시
%matplotlib inline #notebook을 실행한 브라우저에서 바로 그림을 볼 수 있게 해주는 것2. 데이터 불러오기 및 확인
data=pd.read_csv('./titanic.csv') #가끔 경로복사하면 /대신 \가 있어서 에러가 뜨는 데 /로 바꾸어주면 된다.
print(data.isnull().sum()) #isnull()은 결측값, sum()은 합
data.head() #head()함수는 불러온 데이터의 상위 5개의 행을 출력한다.
3. 생존자 시각화 (Class 분포 확인)
f, ax = plt.subplots(1, 2, figsize=(18, 8)) #한번에 여러 그래프를 보여주기 위해 사용하는 코드, fig는 전체 subplot이고, axe는 전체중 낱낱개이다. (행, 열, figsize 18x8)
data['Survived'].value_counts().plot.pie(explode=[0,0.1],autopct='%1.1f%%',ax=ax[0],shadow=True) # value_counts(): 'Survived'열의 고유값 반환(아마도 1과 0의 개수가 반환될것), plot.pie: 파이차트로 나타냄, explode: 각 항목이 파이의 원점에서 튀어나오는 정도, autopct: 각 항목의 퍼센트(소수점 한자리), ax[0]은 첫번째 항목에만 적용한다는 뜻 아닐까 싶다, shadow:음영처리
ax[0].set_title('Survived') #첫번째 항목의 타이틀 설정
ax[0].set_ylabel('')
sns.countplot('Survived',data=data,ax=ax[1]) #countplot은 빈도 그래프로 위의 파이그래프를 그릴때 처럼 따로 value_counts()를 해주지 않아도 되는것 같다. (열, 데이터, 위치)
ax[1].set_title('Survived') #두번째 항목의 타이틀
plt.show()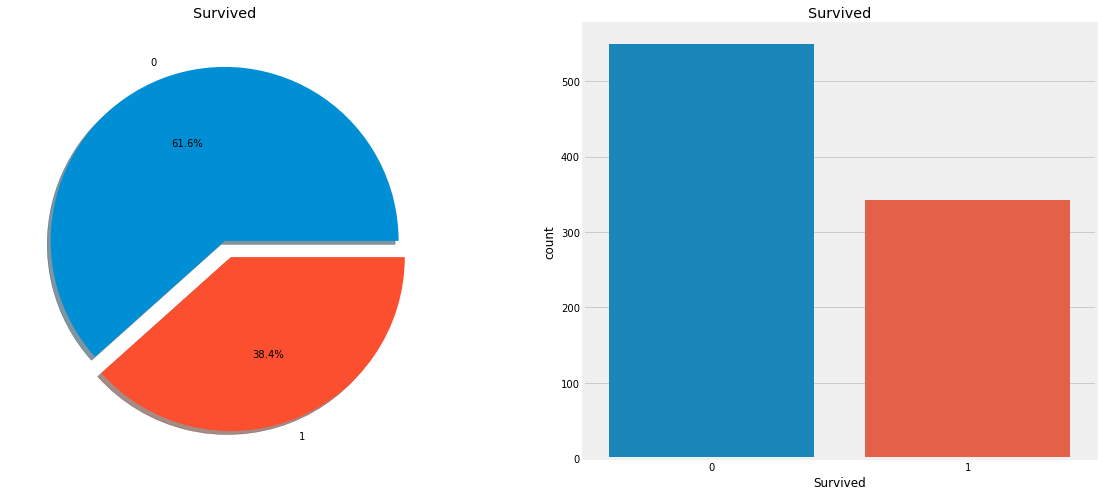
4. Feature와 Class 관계 파악하기
- 성별과 생존과의 관계
f,ax=plt.subplots(1,2,figsize=(18,8))
data[['Sex','Survived']].groupby(['Sex']).mean().plot.bar(ax=ax[0]) #groupby(칼럼): 그룹별로 데이터 집계, mean():평균, plot.bar():바 그래프로 표현
ax[0].set_title('Survived vs Sex')
sns.countplot('Sex',hue='Survived',data=data,ax=ax[1]) #hue:분화하기, 범주형 변수 입력,
ax[1].set_title('Sex:Survived vs Dead')
plt.show()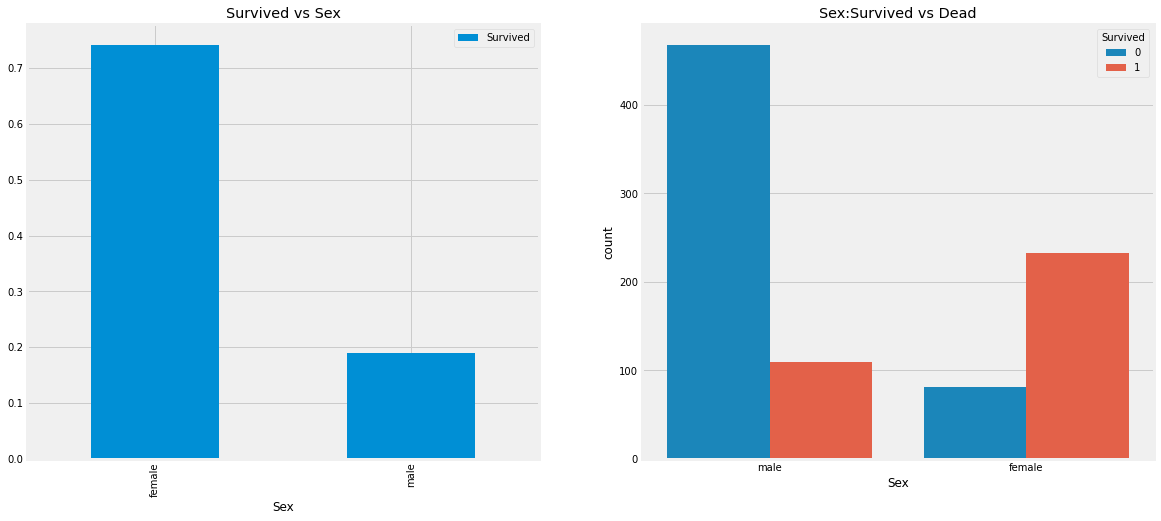
- 선실 등급과 생존과의 관계
f,ax=plt.subplots(1,2,figsize=(18,8))
data['Pclass'].value_counts().plot.bar(color=['#CD7F32','#FFDF00','#D3D3D3'],ax=ax[0])
ax[0].set_title('Number Of Passengers By Pclass')
ax[0].set_ylabel('Count')
sns.countplot('Pclass',hue='Survived',data=data,ax=ax[1])
ax[1].set_title('Pclass:Survived vs Dead')
plt.show() factorplot으로 나타내기
factorplot으로 나타내기
sns.factorplot('Pclass','Survived',hue='Sex',data=data) #factorplot이 정확히 무엇인지 모르겠지만 3개의 차원의 그래프를 그릴수 있다.
plt.show()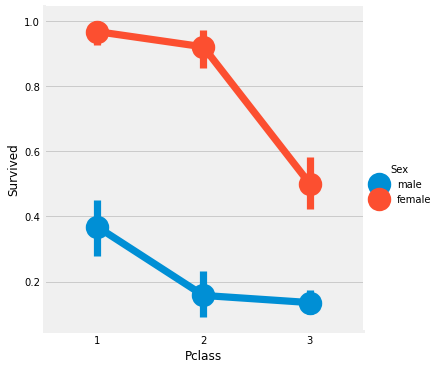
그래프를 분석해보면 Pclass가 1(가장 비싼 좌석?)이 남녀의 생존율이 높고, 전체적으로 남성보다 여성의 생존율이 높은 것을 보아 여성을 우선으로 구조하지 않았을까 싶다.
5. Age 공략하기
f,ax=plt.subplots(1,2,figsize=(18,8))
sns.violinplot("Pclass","Age", hue="Survived", data=data,split=True,ax=ax[0]) #violinplot: 가운데 흰점은 중앙값을 나타내고, 중앙의 두꺼운 선은 사분위 범위, 얇은 선은 신뢰구간을 나타낸다. split: 대칭성을 이용하여 한쪽만 남기고 합침
ax[0].set_title('Pclass and Age vs Survived')
ax[0].set_yticks(range(0,110,10)) #yticks() : 눈금설정
sns.violinplot("Sex","Age", hue="Survived", data=data,split=True,ax=ax[1])
ax[1].set_title('Sex and Age vs Survived')
ax[1].set_yticks(range(0,110,10))
plt.show()
print("# of Null Values of Age Column: ", data['Age'].isnull().sum()) #age의 결측값 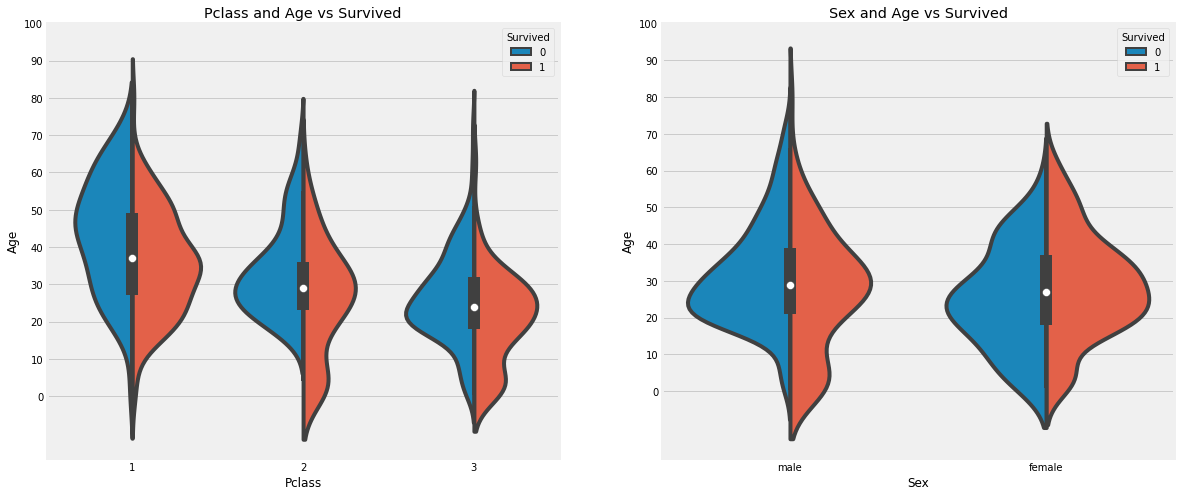
Age의 결측값 해결을 위한 코드(이름에서 나이에 대한 데이터 추출 : mr,mrs..)
data['Initial']=0
for i in data:
data['Initial']=data.Name.str.extract('([A-Za-z]+)\.') # [a-zA-Z]: 알파벳 모두, str.extract('([A-Za-z]+)\.'): 중괄호() 부분 추출, 알파벳이 포함된 문자열을 한 번이상 반복하다가 .으로 마무리하는 문자열 추출pd.crosstab(data.Initial,data.Sex).T #crosstab(): 빈도를 세어서 도수분포표 혹은 교차표를 만들어줌, (index, columns), T: 컬럼과 로우를 바꿈
일부 오타를 replace함수로 정리
data['Initial'].replace(
['Mlle','Mme','Ms','Dr','Major','Lady','Countess','Jonkheer','Col','Rev','Capt','Sir','Don'],
['Miss','Miss','Miss','Mr','Mr','Mrs','Mrs','Other','Other','Other','Mr','Mr','Mr'],
inplace=True) #replace('현재 문자열', '대체 문자열'), inplace:True일 경우 원본 데이터에 replace 함수의 반환 값이 반영
print(data.groupby('Initial')['Age'].mean()) # 평균값 확인!
각 이니셜 별 평균 나이를 알아냈으니, 결측값에 알맞은 나이를 채워준다.
data.loc[(data.Age.isnull())&(data.Initial=='Mr'),'Age']=33 #loc로 행 또는 열의 데이터 조회, Age가 null값이고, 이니셜이 Mr인 사람의 Age에 33을 넣어준다.
data.loc[(data.Age.isnull())&(data.Initial=='Mrs'),'Age']=36
data.loc[(data.Age.isnull())&(data.Initial=='Master'),'Age']=5
data.loc[(data.Age.isnull())&(data.Initial=='Miss'),'Age']=22
data.loc[(data.Age.isnull())&(data.Initial=='Other'),'Age']=46
print("결측치 제거 후 남은 결측치: ",data.Age.isnull().sum())결측값 해결후 최종 연령대별 생존여부 확인
f,ax=plt.subplots(1,2,figsize=(20,10))
data[data['Survived']==0].Age.plot.hist(ax=ax[0],bins=20,edgecolor='black',color='red') #plot.hist: 히스토그램, 도수분포표, bins: 가로축 구간의 개수
ax[0].set_title('Survived= 0')
x1=list(range(0,85,5))
ax[0].set_xticks(x1)
data[data['Survived']==1].Age.plot.hist(ax=ax[1],color='green',bins=20,edgecolor='black')
ax[1].set_title('Survived= 1')
x2=list(range(0,85,5))
ax[1].set_xticks(x2)
plt.show()
추가적으로 생각해볼수 있는 질문들을 제공해주었다.
영아(5세 미만)들은 최우선적으로 구해진 것같나요? 생존한 빈도수가 압도적으로 높은 것을 보아 5세미만의 사람들의 대부분은 생존한 것 같다. 우선적으로 구해진것이 아닐까?
생존자 중, 가장 나이가 많은 사람은 몇 세인가요? 30~35세정도이다
가장 많이 죽음을 당한 연령대는 몇 세인가요? 30~35세
30~35세의 나이대의 사람들이 그냥 많았던 것 같기도?
6. 탑승항구와 생존여부
sns.factorplot('Embarked','Survived',data=data)
fig=plt.gcf() #현재 figure를 확인하는 방법, get current figure의 약어
fig.set_size_inches(5,3) #figure의 크기 조정
plt.show()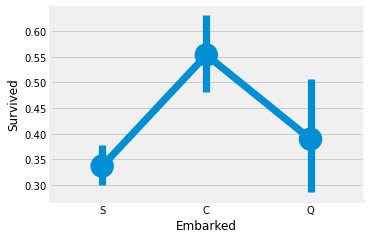
C탑승구에서 탑승한 사람들의 생존율이 가장 높다.
f,ax=plt.subplots(2,2,figsize=(20,15))
sns.countplot('Embarked',data=data,ax=ax[0,0])
ax[0,0].set_title('No. Of Passengers Boarded')
sns.countplot('Embarked',hue='Sex',data=data,ax=ax[0,1])
ax[0,1].set_title('Male-Female Split for Embarked')
sns.countplot('Embarked',hue='Survived',data=data,ax=ax[1,0])
ax[1,0].set_title('Embarked vs Survived')
sns.countplot('Embarked',hue='Pclass',data=data,ax=ax[1,1])
ax[1,1].set_title('Embarked vs Pclass')
plt.subplots_adjust(wspace=0.2,hspace=0.5)
plt.show()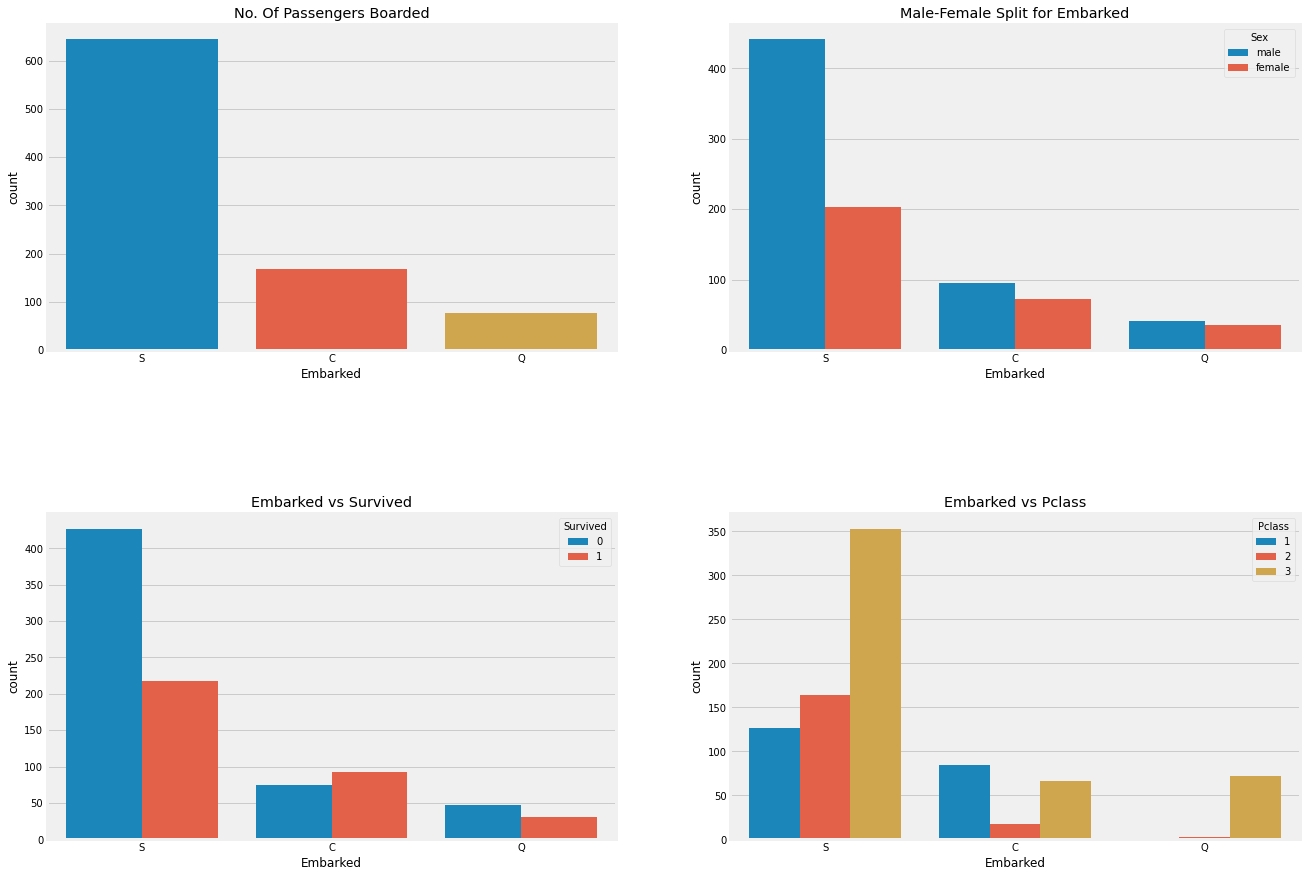
S탑승구에서 탑승한 사람이 가장많고 S탑승구의 남자비율이 압도적으로 높다.
G탑승구와 C탑승구의 인원은 둘다 적지만 C탑승구에는 Pclass가 1인 사람들이 많아 생존율이 더 높았던것 같다.
sns.factorplot('Pclass','Survived',hue='Sex',col='Embarked',data=data)
plt.show()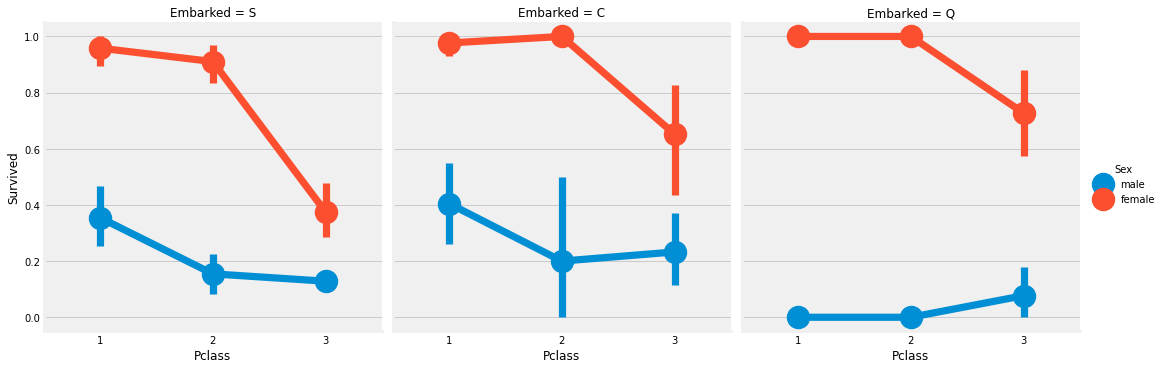
제공된 질문이다.
가장 많은 승객이 탑승한 선착장은 어디고, 대부분 몇 등급의 선실이었나요? 선착장 S이고, 대부분 3등급의 선실이었다.
마지막 그림에서, S 선착장에서 알아낼 수 있는 사실은 무엇인가요? 3등급의 선실에 사람이 가장 많음에도 불구하고 1등급 선실의 생존율이 높다.
제공된 학습자료는 여기까지이다. 데이터분석이라는 것이 어떻게 보면 창의적인 추리력?이 필요한 것 같다. 나이의 결측값을 채우기 위해 이름의 앞부분을 활용하려는 아이디어를 떠올린 것과 같이. 이러한 부분이 나에게 굉장히 흥미롭게 느껴진다. 이 단계가 물론 머신러닝, 딥러닝을 위한 준비과정 단계이고, 아직 머신러닝과 딥러닝에 대해서는 잘 모르지만, 이 단계의 흥미로움이 나의 인공지능 분야에 대한 관심을 증폭시켜주었다. 앞으로 다양한 데이터를 분석하고 접해봐야겠다.
타이타닉 캐글 필사를 검색해보니 더 많은 데이터를 분석해보는 내용이 있었다. 또한 다들 캐글 필사로 데이터 분석 공부를 많이 하는 것 같다. 앞으로 데이터 분석 공부를 할 때에 캐글필사를 하면 될 것 같다는 방향성을 얻었다.
*캐글은 데이터 분석 경진대회 플랫폼이라고 한다. 데이터 사이언스 계의 '깃허브'느낌. 찾아보니 초보자들을 위한 Kaggle Course라는 실습이루어진 강의?가 있다. 등급도 있네? 백준같은 느낌인가? 캐글코스도 틈틈히 공부해봐야겠군
우리학교에 산업데이터학과?가 있는데 이 과에서 데이터분석과 관련된 수업이 있는 지도 한 번 찾아봐야겠다.
추가적으로 느낀 것은 내가 파이썬 문법에 대해 약간 아슬아슬한 부분들이 있다는 것이다. 파이썬과 관련된 문법을 익힐만한 예제문제들도 많이 풀어봐야겠다...

정리가 잘 된 글이네요. 도움이 됐습니다.