
Fortune 100개 기업 기준으로 80%이상이
Kafka를 사용하고 있으며,
제조, 은행, 통신 등 다양한 업종에서 높은 비율로 사용중이다.
(국내에서도 많은 큰 회사들이 사용중)
기본 구조
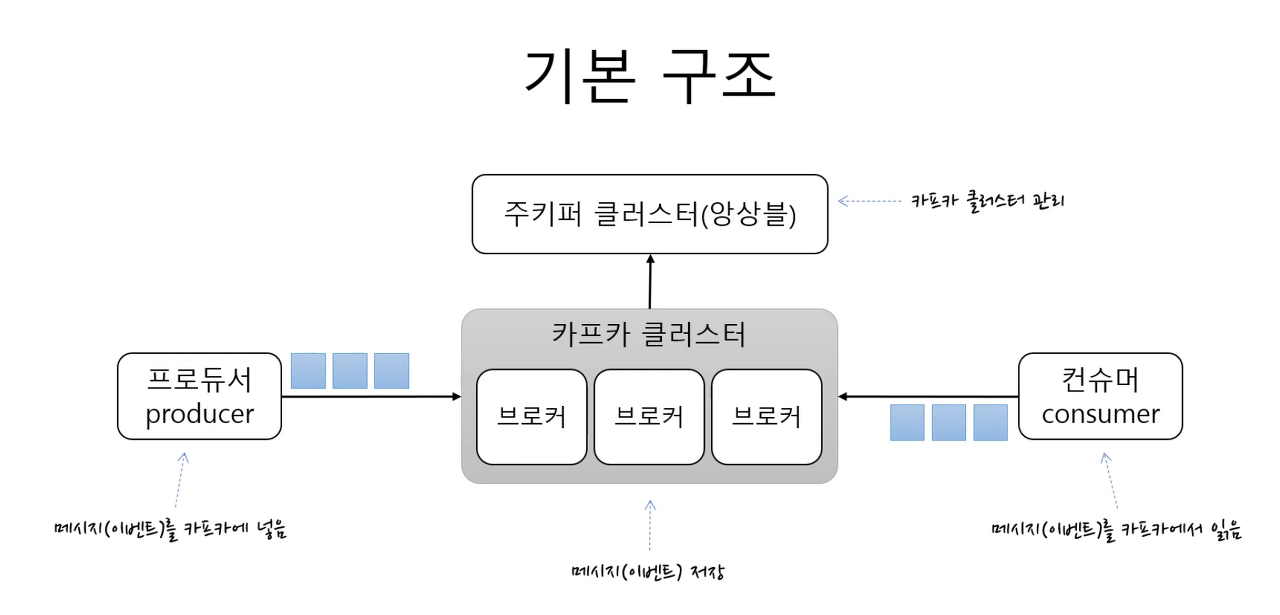
- 카프카 클러스터
- 메세지를 저장하는 저장소
- 하나의 여러개의 브로커(각각의 서버)로 구성이 됨
- 브로커들이 메세지를 나눠서 저장, 이중화 처리, 장애가 나면 대체 함
- 데이터를 이동하는데 필요한 핵심 역할을 맡음
-
주키퍼 클러스터(앙상블)
- 카프카 클러스터 관리
- 카프카 클러스터와 관련된 정보가 기록이되고 관리가 됨 -
프로듀서(producer)
- 카프카 클러스터에 메시지를 보냄 -
컨슈머(consumer)
- 카프카 클러스터에서 메세지를 읽음
토픽(Topic)과 파티션(Partition)
- 토픽 : 메시지를 구분하는 단위 (파일시스템의 폴더와 유사)
- 한 개의 토픽은 한 개 이상의 파티션으로 구성
- 파티션은 메시지를 저장하는 물리적인 파일
- 각각의 메시지를 알맞게 구분하기 위한 목적으로 사용
- 프로듀서와 컨슈머가 토픽을 기준으로 메시지를 주고 받음
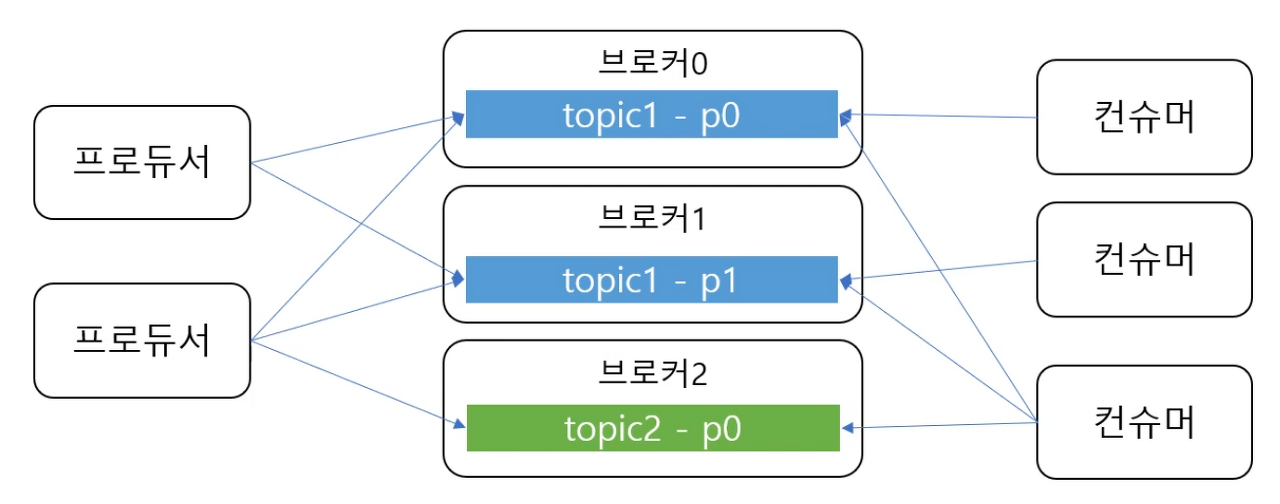
파티션(Partition), 오프셋(Offset), 메시지(Message) 순서
- 파티션은 추가만 가능한(append-only) 파일
- 각 메시지 저장 위치를 오프셋(offset)이라고 함
- 프로듀서가 넣은 메시지는 파티션의 맨 뒤에 추가
- 컨슈머는 오프셋 기준으로 메시지를 순서대로 읽음 (queue 방식으로, FIFO)
- 메시지는 삭제되지 않음(설정에 따라 일정시간이 지난 뒤 삭제)

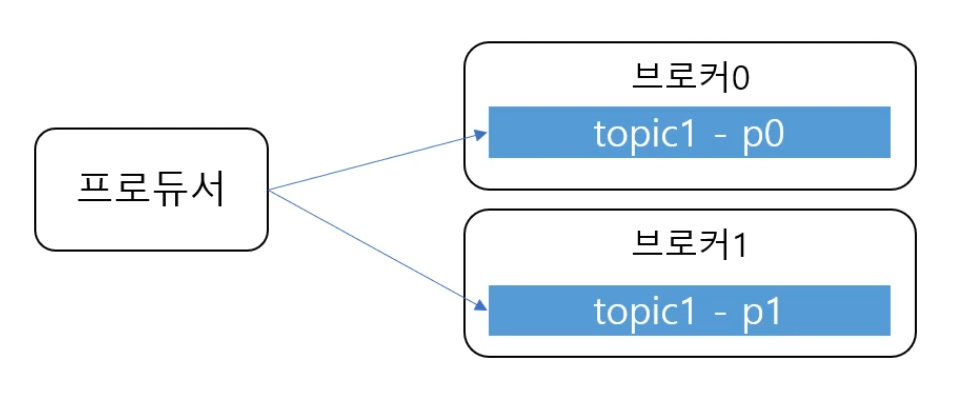
프로듀서(Producer) <-> 파티션 (Partition)
- 프로듀서는 라운드로빈(Round Robin Scheduling, RR) 또는 키로 파티션 선택
- 같은 키를 갖는 메시지는 같은 파티션에 저장 -> 같은 키는 순서 유지
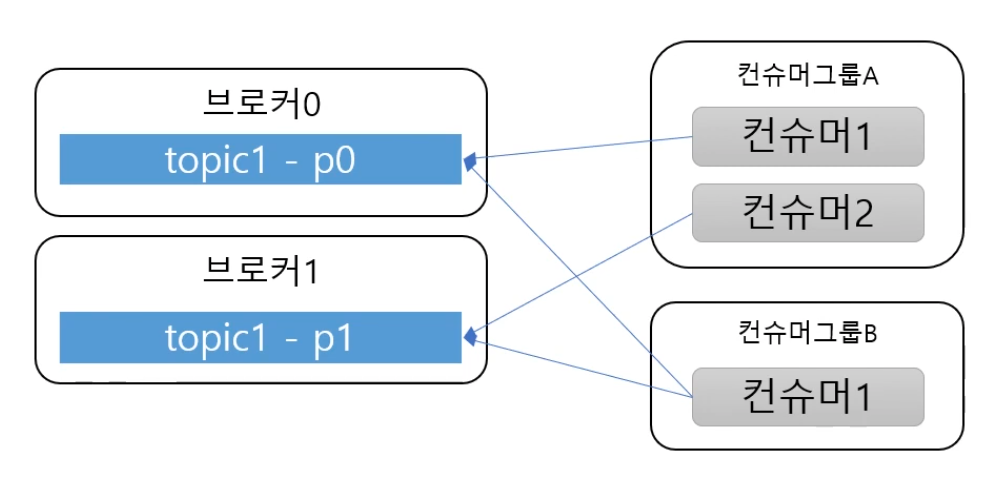
파티션(Partition) <-> 컨슈머(Consumer)
- 컨슈머는 컨슈머그룹에 속함
- 한 개 파티션은 컨슈머그룹의 한 개 컨슈머만 연결 가능
- 즉 컨슈머그룹에 속한 컨슈머들은 한 파티션을 공유할 수 없음
- 한 컨슈머그룹 기준으로 파티션의 메시지는 순서대로 처리
- 한 개 파티션을 서로 다른 그룹의 컨슈머는 공유할 수 있음
Kafka의 성능
- 파티션 파일은 OS 페이지캐시 사용
- 파티션에 대한 파일 IO를 메모리에서 처리
- 서버에서 페이지캐시를 카프카만 사용해야 성능에 유리- Zero Copy
- 디스크 버퍼에서 네트워크 버퍼로 직접 데이터 복사- 컨슈머 추적을 위해 브로커가 하는 일이 비교적 단순
- 메시지 필터, 메시지 재전송과 같은 일은 브로커가 하지 않음 (프로듀서, 컨슈머가 직접 해야 함)
- 브로커는 컨슈머와 파티션 간 매핑 관리- 묶어서 보내기, 묶어서 받기 (batch)
- 프로듀서 : 일정 크기만큼 메시지를 모아서 전송 가능
- 컨슈머 : 최소 크기만큼 메시지를 모아서 조회 가능
-> 낱개 처리보다 처리량 증가
Kafka의 성능 향상
- 수평확장이 용이한 구조를 가지고 있어서 처리량 증대(확장)가 쉬움
- 1개 장비의 용량 한계 -> 브로커 추가, 파티션 추가
- 컨슈머가 느림 -> 컨슈머 추가 (+파티션 추가)

카프카 - 레플리카(Replica)
- 레플리카 : 파티션의 복제본
- 복제수(replication factor) 만큼 파티션의 복제본이 각 브로커에 생김
- 리더와 팔로워 구성
- 프로듀서와 컨슈머는 리더를 통해서만 메시지 처리
- 팔로워는 리더로부터 복제
- 장애 대응
- 리더가 속한 브로커 장애시 다른 팔로워가 리더가 됨
- 프로듀서와 컨슈머는 새로운 리더를 통해서 메시지를 다시 처리할 수 있게 됨
정리
성능 (높은 처리량)
- OS 페이지캐시
- (다른 메시징 시스템 대비) 단순한 브로커
- 묶어서 데이터 전송 (Batch)
- 파티션/컨슈머 추가로 수평 확장 가능
고가용성
- 파티션 리플리케이션 + 리더/팔로워 구조

지속적으로 성장하고 발전하는 진취적인 태도를 가진 개발자의 삶을 추구합니다.