- 카프카(Kafka)란 무엇인가?
카프카(Kafka)는 2011년 미국 링크드인(Linkedin)에서 개발하였다.
- 카프카 개발 전 링크드인의 데이터 처리 시스템
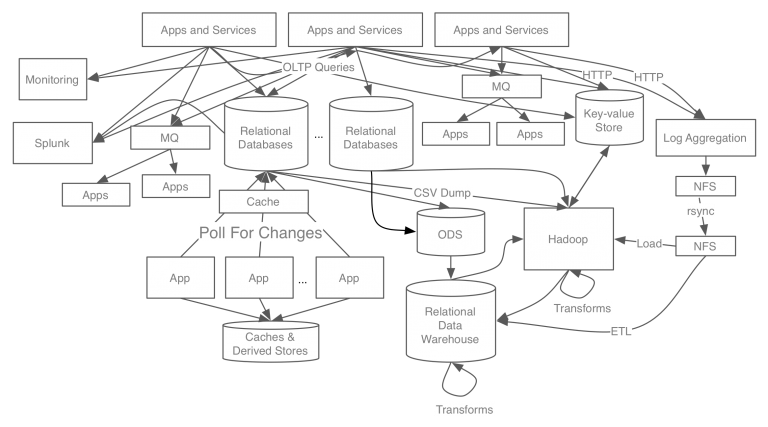
기존 링크드인의 데이터 처리 시스템은 각 파이프라인이 파편화되고 시스템 복잡도가 높아서 새로운 시스템을 확장하기 어려웠다.
이로 인해 새로운 시스템의 개발 필요성이 높아졌고, 다음과 같은 목표를 가지고 새로운 시스템을 개발했다.
- 프로듀서(Producer)와 컨슈머(Consumer)의 분리
- 메시징 시스템과 같이 영구 메시지 데이터를 여러 컨슈머에게 적용
- 높은 처리량을 위한 메시지 최적화
- 트래픽 증가에 따른 스케일아웃이 가능한 시스템
- 카프카를 적용한 후의 링크드인의 데이터 처리 시스템

한 눈에 보기에도 훨씬 간결해진 것을 알 수 있다. 카프카를 적용함으로써 모든 이벤트/데이터의 흐름을 중앙(Kafka)에서 관리할 수 있게 되었다.
카프카는 데이터 파이프라인, 스트리밍 분석, 데이터 통합 및 미션 크리티컬 애플리케이션을 위해 설계된 고성능 분산 이벤트 스트리밍 플랫폼이다.
카프카는 Pub-Sub 모델의 메시지 큐 형태로 동작하며 분산환경에 특화되어 있다.
Fortune 100개 기업 중 80% 이상이 Kafka를 사용한다.
Kafka의 구성요소
- 다음은 카프카(Kafka)의 구성도를 그림으로 표현것이다.
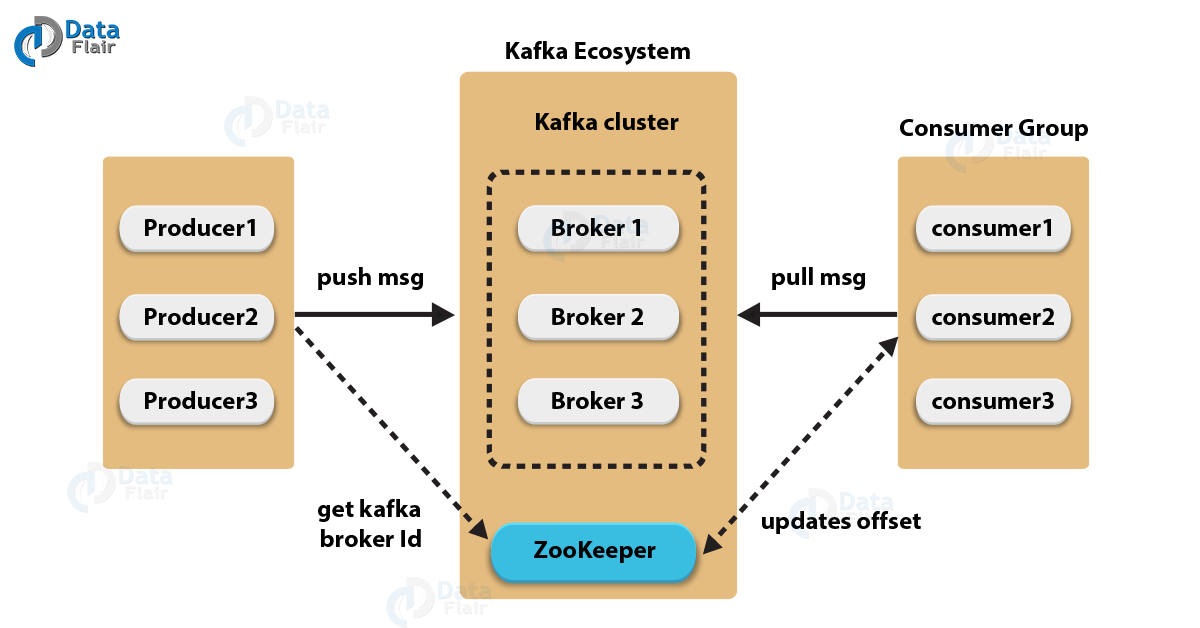
- Topic
각각의 메시지를 목적에 맞게 구분할 때 사용한다.
메시지를 전송하거나 소비할 때 Topic을 반드시 입력한다.
Consumer는 자신이 담당하는 Topic의 메시지를 처리한다.
한 개의 토픽은 한 개 이상의 파티션으로 구성된다.
- Partition
분산 처리를 위해 사용된다.
Topic 생성 시 partition 개수를 지정할 수 있다. (파티션 개수 변경 가능. *추가만 가능)
파티션이 1개라면 모든 메시지에 대해 순서가 보장된다.
파티션 내부에서 각 메시지는 offset(고유 번호)로 구분된다.
파티션이 여러개라면 Kafka 클러스터가 라운드 로빈 방식으로 분배해서 분산처리되기 때문에 순서 보장 X
파티션이 많을 수록 처리량이 좋지만 장애 복구 시간이 늘어난다.
- Producer
메시지를 만들어서 카프카 클러스터에 전송한다.
메시지 전송 시 Batch 처리가 가능하다.
key값을 지정하여 특정 파티션으로만 전송이 가능하다.
전송 acks값을 설정하여 효율성을 높일 수 있다.
ACKS=0 -> 매우 빠르게 전송. 파티션 리더가 받았는 지 알 수 없다.
ACKS=1 -> 파티션 리더가 받았는지 확인. 기본값
ACKS=ALL -> 파티션 리더 뿐만 아니라 팔로워까지 메시지를 받았는 지 확인
- Consumer
카프카 클러스터에서 메시지를 읽어서 처리한다.
메세지를 Batch 처리할 수 있다.
한 개의 컨슈머는 여러 개의 토픽을 처리할 수 있다.
메시지를 소비하여도 메시지를 삭제하지는 않는다. (Kafka delete policy에 의해 삭제)
한 번 저장된 메시지를 여러번 소비도 가능하다.
컨슈머는 컨슈머 그룹에 속한다.
한 개 파티션은 같은 컨슈머그룹의 여러 개의 컨슈머에서 연결할 수 없다.
- Broker
실행된 카프카 서버를 말한다.
프로듀서와 컨슈머는 별도의 애플리케이션으로 구성되는 반면, 브로커는 카프카 자체이다.
메시지를 저장하고 관리하는 역할
- Zookeeper
분산 애플리케이션 관리를 위한 코디네이션 시스템
분산 메시지큐의 메타 정보를 중앙에서 관리하는 역할
- Kafka의 특징
- 디스크에 메시지를 저장해서 영속성(persistency)를 보장한다.
- 프로듀서와 컨슈머를 분리하고 멀티 프로듀서와 멀티 컨슈머를 지원한다.
- 프로듀서와 컨슈머 모두 배치 처리가 가능해서 네트워크 오버헤드를 줄일 수 있다.
- 높은 성능과 고가용성과 확장성을 가진다.
- 메시지 보장 여부를 선택할 수 있다.
- Kafka의 활용
- 서비스간 결합도를 낮추기 위해 사용한다.
- 모든 데이터를 한 곳으로 집중할 때 유리하다. (ex. 로그 통합, 실시간 접속 분석, 서버 모니터링)
- 실시간 스트리밍 서비스에 적합하다. (ex. 알림 전송 등)
- 대규모 서비스와 배치 시스템에 적합하다.
- 트래픽의 변화가 큰 곳에서 유용하다.
- Reference
