강의 복습!
DL-Basic의 1강부터 10강까지 수강하고 필수과제 작성 및 해당 내용들을 제가 구축한 DL-framework에 맞추어 연습했습니다. 해당 부분은 추후에 개별적으로 올릴 예정입니다!
강의 정리(예)
## (01강) 딥러닝 기본 용어 설명 - Historical Review
### 01. 딥러닝 기본 용어 설명
#### 딥러닝 개발자의 필수 역량
1. 구현 능력
2. 선형대수, 확률에 대한 수학적 지식
3. 최근 연구에 대한 지식
#### 딥러닝의 필수 요소
#### 01) Data
- Ex.
- Classification(분류)
- Semantic Segmentation(분리)
- Detection(검출)
- Pose Estimation(추정)
- Visual Q&A
...
Cf) **의료 영상 분석**에서는
- Classification, Segmentation, Enhancement, Registration가 중요하다!
#### 02) Model
- 데이터를 어떻게 변형시켜 원하는 문제를 해결할 지
- Ex.
- AlexNet
- GoogleNet
- ResNet
- DenseNet
- LSTM
- Deep AutoEncoders
- GAN
- ...
#### 03) Loss function
- 데이터를 토대로 산출한 모델의 예측값과 실제값의 차이를 표현하는 지표
- Ex.
- Regression Task
- Classification Task
- Probabilistic Task
...
#### 04) **Optimization algorithm** : Adjust the parameters to minimize the loss
- 손실을 최소화하기 위한 매개변수를 조정
- Ex.
- Dropout - For reducing overfitting in artificial neural networks by preventing complex co-adaptations on training data
- Early stopping
- k-fold validation
- Weight decay
- Batch normalizaion
...
### 02. Historical Review
#### 1. AlexNet(2012)
- Convolution Neural Network
- 244 x 244 image classifiaction
#### 2. DQN(2013)
- Reinforcement learning
- Q-learning
#### 3. Encoder/Decoder(2014)
- To solve Neural Machine Translation(NMT)
#### 4. Adam Optimizer(2014)
#### 5. Generative Adversarial Network(2015)
- Generator / Discriminator learning
#### 6. Residual Networks(2016)
- Solve **overfitting** problem while stack lot of network
#### 7. Transformer(2017)
- paradigm shift
#### 8.BERT(2018)
- Fine-tuned NLP models
#### 9.Big Language Model(GPT-X)(2019)
- autoregressive language model with 175 billion parameters
#### 10.Self supervised learning(2020)
- Using unsupervised learning
---
## (02강) Neural Networks & Multi-Layer-Perceptron
## Neural Networks
### 01. Introduction
**"Neural networks are computing system vaguely inspired by the biological neural networks that constitute animal brains."**
- Neural networks are **function approximators** that **stack affine transformations** followed by **nonlinear transformations**.
### 02. Linear Neural Networks
#### Ex) Linear Regression
- Data: $\mathcal{D} = \{(x_i,y_i)\}_{i=1}^N$ (x: 1D, y: 1D)
- Model: $\hat{y} = wx + b$
- Loss: $loss = {1 \over N}\sum_{i=1}^N (y_i-\hat{y_i})^2$
**We compute the partial derivatives w.r.t the optimization variables.**
$$
{\partial_{loss} \over \partial_{w}} that Partial derivative
={\partial \over \partial_w}{1 \over N}\sum_{i=1}^N (y_i-\hat{y_i})^2
={\partial \over \partial_w}{1 \over N}\sum_{i=1}^N (y_i-wx_i-b)^2
=-{1 \over N}\sum_{i=1}^N -2(y_i-wx_i-b)^2x_i
$$
**Then, we iteratively update optimization variables**
Update $w, b$ and stepsize $\eta$
$w \leftarrow w - \eta{\partial{loss} \over \partial{w}}$
$b \leftarrow b - \eta{\partial{loss} \over \partial{b}}$
**Of course, we can handle multi dimensional input and output**
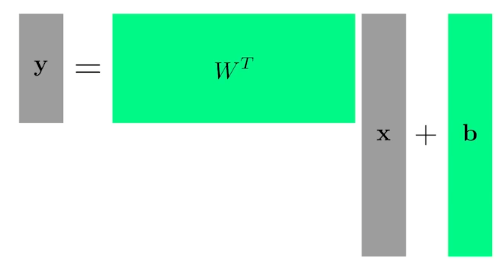
$$
y=W^Tx+b
$$
One way of interpreting a matrix is to regard it as a mapping between two vector spaces
### 03. Beyond Linear Neural Networks
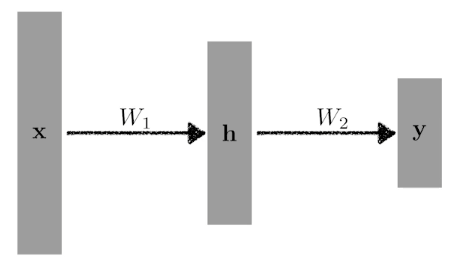
$$
y = W_2^Th=W_2^TW_1^Tx
$$
$$W_2^TW_1^T$$ just means **another matrix** so, we need nonlinear transform **$\rho$**.
$$
y = W_2^Th=W_2^T\rho(W_1^Tx)
$$
#### Activation functions
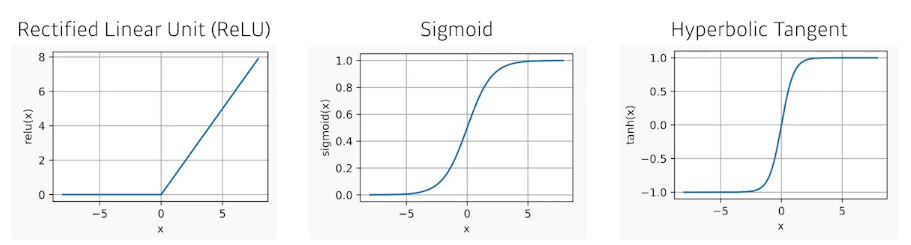
- Relu: $$R(x)=x^{+}=\max(0,x)$$
- Sigmoid: $S(x)={1 \over {1+e^{-1}}}={e^x\over{e^x+1}}$
- Tanh: $tanh x={e^x-e^{-x}\over {e^x+e^{-x}}}={e^{2x}-1\over e^{2x}+1}$
## Mult-Layer Perceptron
### 01. Introduction
**This class of architectures are often called multi-layer perceptrons.**
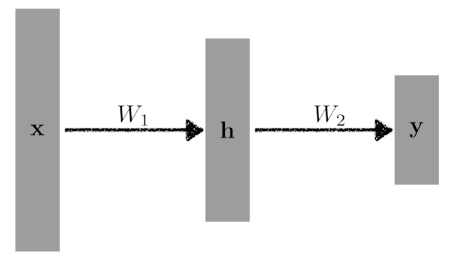
$$
y = W_2^Th=W_2^T\rho(W_1^Tx)
$$
#### Loss function
- Regression Task : $MSE={1 \over N}\sum_{i=1}^N\sum_{d=1}^D(y_i^{(d)}-\hat{y_i^{(d)}})^2$
- $y_i^{(d)}$: True target
- $\hat{y_i}^{(d)}$: Predicted output
- Classification Task : $CE=-{1 \over N}\sum_{i=1}^N\sum_{d=1}^Dy_i^{(d)}\log\hat{y_i}^{(d)}$
- Probabilistic Task : ${1 \over N}\sum_{i=1}^N\sum_{d=1}^Dy_i^{(d)}\log\mathcal N(y_i^{(d)};\hat{y_i}^{(d)},1)$ (=MSE)
## (03강) Optimization강의 수행 과정 / 결과물 정리!
01. Multilayer Perceptron(MLP)
02. CNN
03. Optimization
04. LSTM
05. Multi-Head Attention(MHA)
피어세션 정리!
- 8월 9일에 추가모집을 연락받아 10일날 처음으로 참여했으나.. 기존에 하던 부분을 정리하지 못해 이번 주는 제대로 된 정리가 힘들것 같습니다. 다음주에는 새로운 모습을 보여주겠습니다!
04. 학습 회고!
- 뒤늦게 추가모집으로 합류하였기에 이번 주는 제대로 된 정리가 힘들 것 같습니다. 기존에 혼자 학습했던 MIA 관련 코드들과 해당 캠프에서 배울 내용들을 조합하여 나만의 프로그래밍을 하는것을 최종 목표로 꾸준히 정진해야 할 것 같습니다.

Beyond the new era.